 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Programmable Wireless Connectivity: Challenges and Research Directions Toward Interactive and Immersive Industry
Mar 31, 2026This vision paper addresses the research challenges of integrating traditional signal processing with Artificial Intelligence (AI) to enable energy-efficient, programmable, and scalable wireless connectivity infrastructures. While prior studies have primarily focused on high-level concepts, such as the potential role of Large Language Model (LLM) in 6G systems, this work advances the discussion by emphasizing integration challenges and research opportunities at the system level. Specifically, this paper examines the role of compact AI models, including Tiny and Real-time Machine Learning (ML), in enhancing wireless connectivity while adhering to strict constraints on computing resources, adaptability, and reliability. Application examples are provided to illustrate practical considerations and highlight how AI-driven signal processing can support next-generation wireless networks. By combining classical signal processing with lightweight AI methods, this paper outlines a pathway toward efficient and adaptive connectivity solutions for 6G and beyond.
R-MTLLMF: Resilient Multi-Task Large Language Model Fusion at the Wireless Edge
Nov 27, 2024



Multi-task large language models (MTLLMs) are important for many applications at the wireless edge, where users demand specialized models to handle multiple tasks efficiently. However, training MTLLMs is complex and exhaustive, particularly when tasks are subject to change. Recently, the concept of model fusion via task vectors has emerged as an efficient approach for combining fine-tuning parameters to produce an MTLLM. In this paper, the problem of enabling edge users to collaboratively craft such MTTLMs via tasks vectors is studied, under the assumption of worst-case adversarial attacks. To this end, first the influence of adversarial noise to multi-task model fusion is investigated and a relationship between the so-called weight disentanglement error and the mean squared error (MSE) is derived. Using hypothesis testing, it is directly shown that the MSE increases interference between task vectors, thereby rendering model fusion ineffective. Then, a novel resilient MTLLM fusion (R-MTLLMF) is proposed, which leverages insights about the LLM architecture and fine-tuning process to safeguard task vector aggregation under adversarial noise by realigning the MTLLM. The proposed R-MTLLMF is then compared for both worst-case and ideal transmission scenarios to study the impact of the wireless channel. Extensive model fusion experiments with vision LLMs demonstrate R-MTLLMF's effectiveness, achieving close-to-baseline performance across eight different tasks in ideal noise scenarios and significantly outperforming unprotected model fusion in worst-case scenarios. The results further advocate for additional physical layer protection for a holistic approach to resilience, from both a wireless and LLM perspective.
Robust Communication and Computation using Deep Learning via Joint Uncertainty Injection
Jun 05, 2024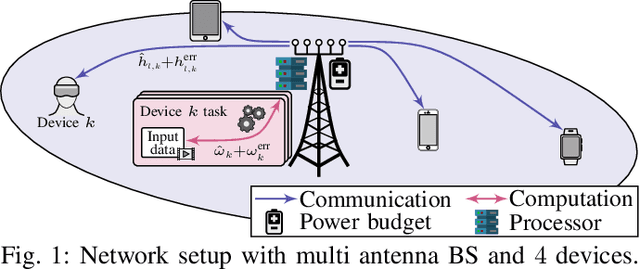
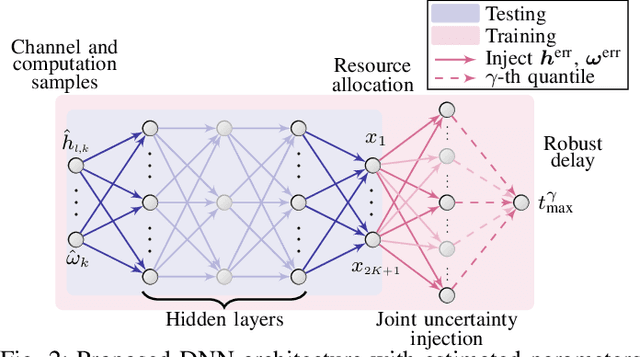
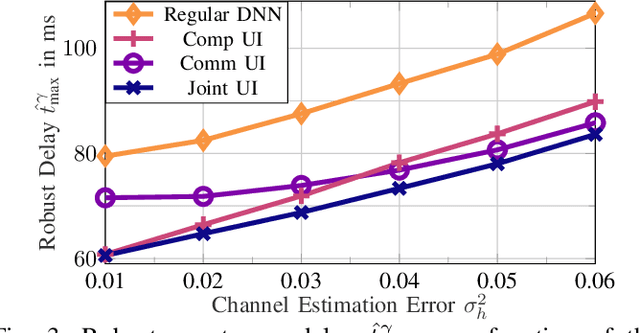
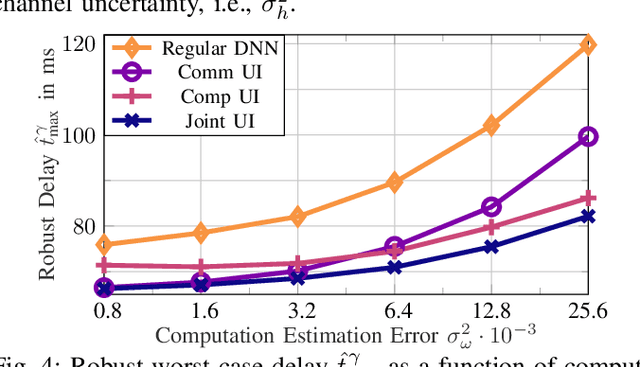
The convergence of communication and computation, along with the integration of machine learning and artificial intelligence, stand as key empowering pillars for the sixth-generation of communication systems (6G). This paper considers a network of one base station serving a number of devices simultaneously using spatial multiplexing. The paper then presents an innovative deep learning-based approach to simultaneously manage the transmit and computing powers, alongside computation allocation, amidst uncertainties in both channel and computing states information. More specifically, the paper aims at proposing a robust solution that minimizes the worst-case delay across the served devices subject to computation and power constraints. The paper uses a deep neural network (DNN)-based solution that maps estimated channels and computation requirements to optimized resource allocations. During training, uncertainty samples are injected after the DNN output to jointly account for both communication and computation estimation errors. The DNN is then trained via backpropagation using the robust utility, thus implicitly learning the uncertainty distributions. Our results validate the enhanced robust delay performance of the joint uncertainty injection versus the classical DNN approach, especially in high channel and computational uncertainty regimes.
Rogue Emitter Detection Using Hybrid Network of Denoising Autoencoder and Deep Metric Learning
Dec 01, 2022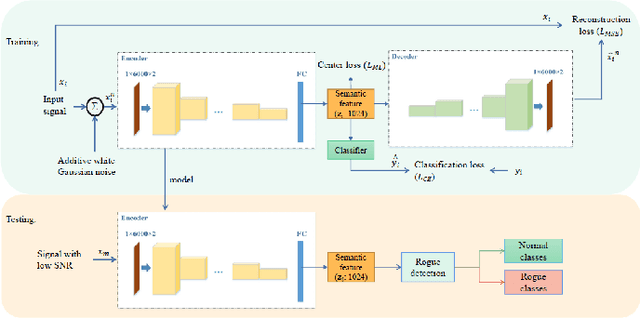
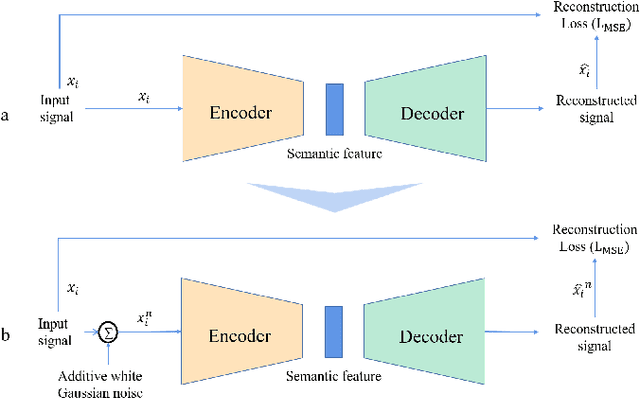
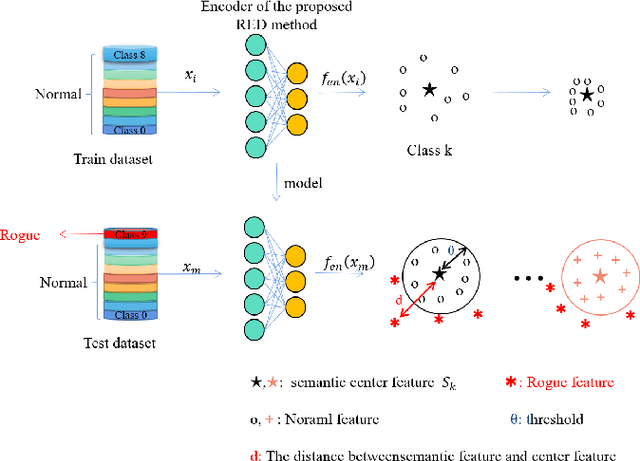
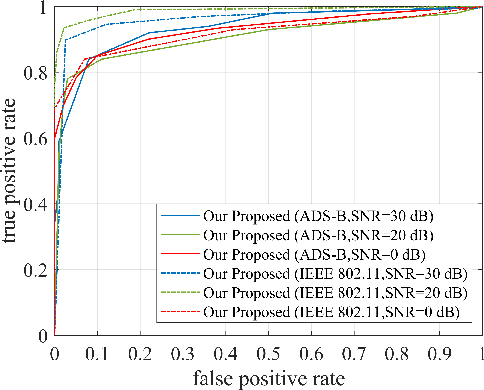
Rogue emitter detection (RED) is a crucial technique to maintain secure internet of things applications. Existing deep learning-based RED methods have been proposed under the friendly environments. However, these methods perform unstable under low signal-to-noise ratio (SNR) scenarios. To address this problem, we propose a robust RED method, which is a hybrid network of denoising autoencoder and deep metric learning (DML). Specifically, denoising autoencoder is adopted to mitigate noise interference and then improve its robustness under low SNR while DML plays an important role to improve the feature discrimination. Several typical experiments are conducted to evaluate the proposed RED method on an automatic dependent surveillance-Broadcast dataset and an IEEE 802.11 dataset and also to compare it with existing RED methods. Simulation results show that the proposed method achieves better RED performance and higher noise robustness with more discriminative semantic vectors than existing methods.
Few-Shot Specific Emitter Identification via Hybrid Data Augmentation and Deep Metric Learning
Dec 01, 2022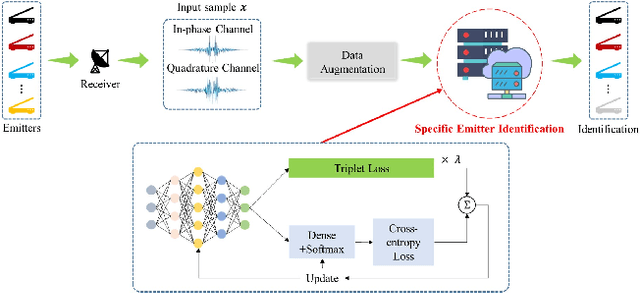
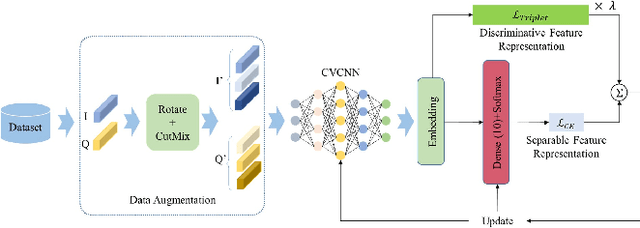
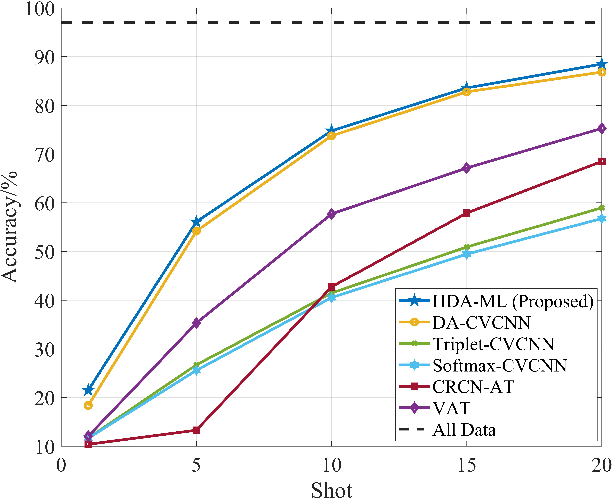
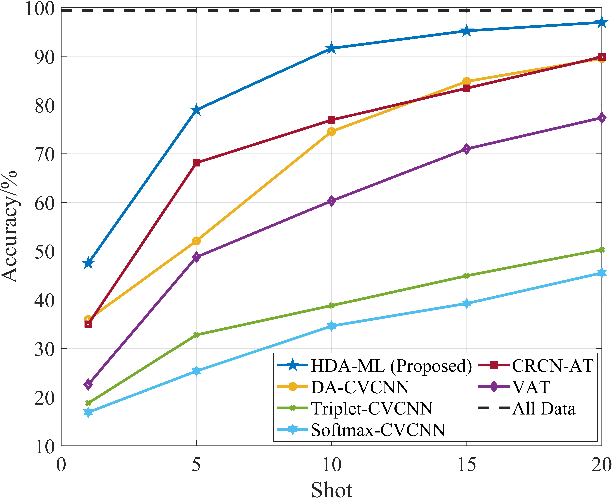
Specific emitter identification (SEI) is a potential physical layer authentication technology, which is one of the most critical complements of upper layer authentication. Radio frequency fingerprint (RFF)-based SEI is to distinguish one emitter from each other by immutable RF characteristics from electronic components. Due to the powerful ability of deep learning (DL) to extract hidden features and perform classification, it can extract highly separative features from massive signal samples, thus enabling SEI. Considering the condition of limited training samples, we propose a novel few-shot SEI (FS-SEI) method based on hybrid data augmentation and deep metric learning (HDA-DML) which gets rid of the dependence on auxiliary datasets. Specifically, HDA consisting rotation and CutMix is designed to increase data diversity, and DML is used to extract high discriminative semantic features. The proposed HDA-DML-based FS-SEI method is evaluated on an open source large-scale real-world automatic-dependent surveillance-broadcast (ADS-B) dataset and a real-world WiFi dataset. The simulation results of two datasets show that the proposed method achieves better identification performance and higher feature discriminability than five latest FS-SEI methods.
Semi-Supervised Specific Emitter Identification Method Using Metric-Adversarial Training
Nov 28, 2022



Specific emitter identification (SEI) plays an increasingly crucial and potential role in both military and civilian scenarios. It refers to a process to discriminate individual emitters from each other by analyzing extracted characteristics from given radio signals. Deep learning (DL) and deep neural networks (DNNs) can learn the hidden features of data and build the classifier automatically for decision making, which have been widely used in the SEI research. Considering the insufficiently labeled training samples and large unlabeled training samples, semi-supervised learning-based SEI (SS-SEI) methods have been proposed. However, there are few SS-SEI methods focusing on extracting the discriminative and generalized semantic features of radio signals. In this paper, we propose an SS-SEI method using metric-adversarial training (MAT). Specifically, pseudo labels are innovatively introduced into metric learning to enable semi-supervised metric learning (SSML), and an objective function alternatively regularized by SSML and virtual adversarial training (VAT) is designed to extract discriminative and generalized semantic features of radio signals. The proposed MAT-based SS-SEI method is evaluated on an open-source large-scale real-world automatic-dependent surveillance-broadcast (ADS-B) dataset and WiFi dataset and is compared with state-of-the-art methods. The simulation results show that the proposed method achieves better identification performance than existing state-of-the-art methods. Specifically, when the ratio of the number of labeled training samples to the number of all training samples is 10\%, the identification accuracy is 84.80\% under the ADS-B dataset and 80.70\% under the WiFi dataset. Our code can be downloaded from https://github.com/lovelymimola/MAT-based-SS-SEI.
Attention Mechanism Based Intelligent Channel Feedback for mmWave Massive MIMO Systems
Aug 13, 2022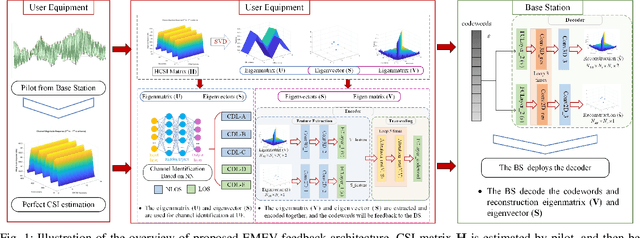
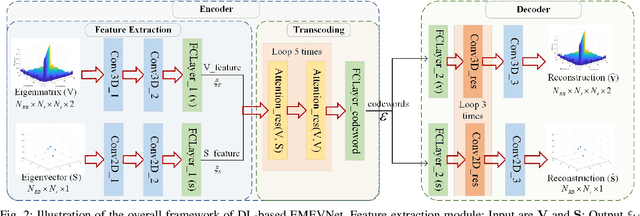
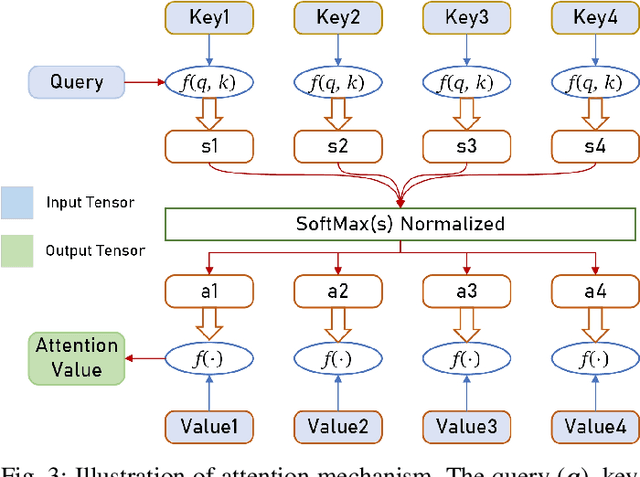

The potential advantages of intelligent wireless communications with millimeter wave (mmWave) and massive multiple-input multiple-output (MIMO) are all based on the availability of instantaneous channel state information (CSI) at the base station (BS). However, in frequency division duplex (FDD) systems, no existence of channel reciprocity leads to the difficult acquisition of accurate CSI at the BS. In recent years, many researchers explored effective architectures based on deep learning (DL) to solve this problem and proved the success of DL-based solutions. However, existing schemes focused on the acquisition of complete CSI while ignoring the beamforming and precoding operations. In this paper, we propose an intelligent channel feedback architecture designed for beamforming based on attention mechanism and eigen features. That is, we design an eigenmatrix and eigenvector feedback neural network, called EMEVNet. The key idea of EMEVNet is to extract and feedback effective information meeting the requirements of beamforming and precoding operations at the BS. With the help of the attention mechanism, the proposed EMEVNet can be considered as a dual channel auto-encoder, which is able to jointly encode the eigenmatrix and eigenvector into codewords. Hence, the EMEVNet consists of an encoder deployed at the user and the decoder at the BS. Each user first utilizes singular value decomposition (SVD) transformation to extract the eigen features from CSI, and then selects an appropriate encoder for a specific channel to generate feedback codewords.
Beamforming Analysis and Design for Wideband THz Reconfigurable Intelligent Surface Communications
Jul 30, 2022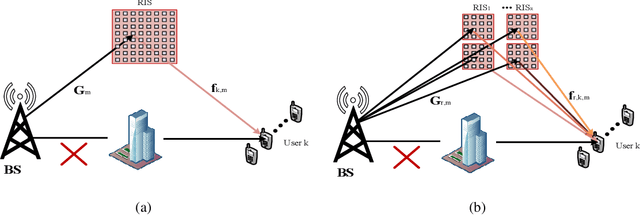
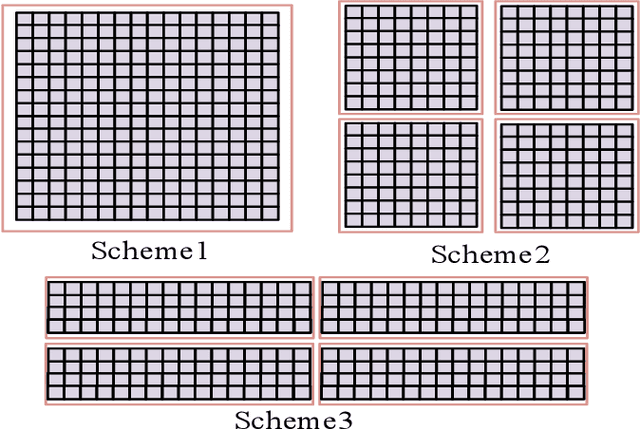
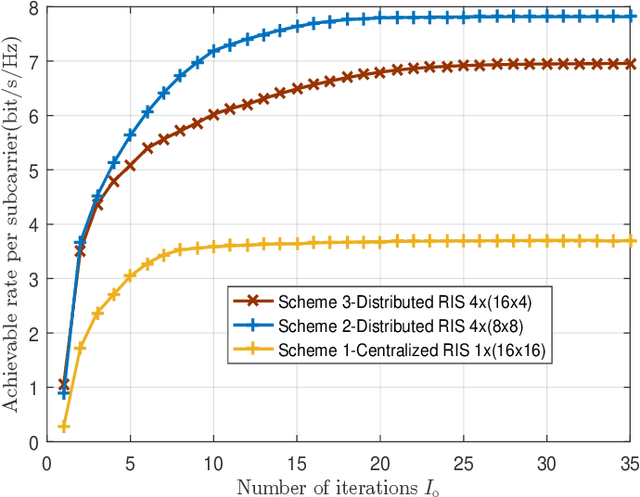
Reconfigurable intelligent surface (RIS)-aided terahertz (THz) communications have been regarded as a promising candidate for future 6G networks because of its ultra-wide bandwidth and ultra-low power consumption. However, there exists the beam split problem, especially when the base station (BS) or RIS owns the large-scale antennas, which may lead to serious array gain loss. Therefore, in this paper, we investigate the beam split and beamforming design problems in the THz RIS communications. Specifically, we first analyze the beam split effect caused by different RIS sizes, shapes and deployments. On this basis, we apply the fully connected time delayer phase shifter hybrid beamforming architecture at the BS and deploy distributed RISs to cooperatively mitigate the beam split effect. We aim to maximize the achievable sum rate by jointly optimizing the hybrid analog/digital beamforming, time delays at the BS and reflection coefficients at the RISs. To solve the formulated problem, we first design the analog beamforming and time delays based on different RISs physical directions, and then it is transformed into an optimization problem by jointly optimizing the digital beamforming and reflection coefficients. Next, we propose an alternatively iterative optimization algorithm to deal with it. Specifically, for given the reflection coefficients, we propose an iterative algorithm based on the minimum mean square error technique to obtain the digital beamforming. After, we apply LDR and MCQT methods to transform the original problem to a QCQP, which can be solved by ADMM technique to obtain the reflection coefficients. Finally, the digital beamforming and reflection coefficients are obtained via repeating the above processes until convergence. Simulation results verify that the proposed scheme can effectively alleviate the beam split effect and improve the system capacity.
A Real-World Radio Frequency Signal Dataset Based on LTE System and Variable Channels
May 25, 2022
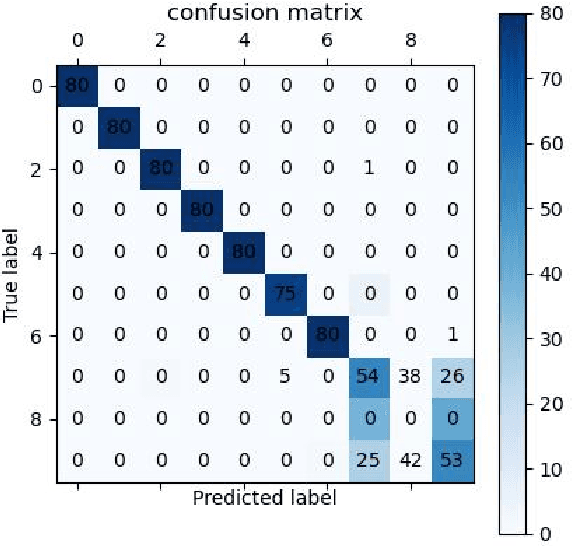
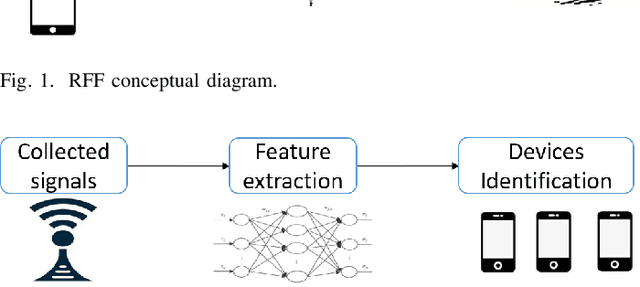
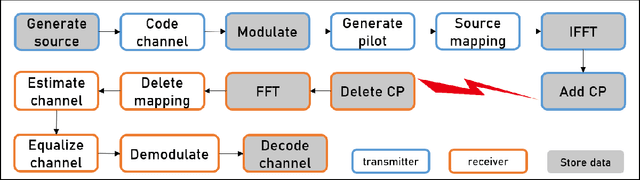
Radio Frequency Fingerprint (RFF) identification on account of deep learning has the potential to enhance the security performance of wireless networks. Recently, several RFF datasets were proposed to satisfy requirements of large-scale datasets. However, most of these datasets are collected from 2.4G WiFi devices and through similar channel environments. Meanwhile, they only provided receiving data collected by the specific equipment. This paper utilizes software radio peripheral as a dataset generating platform. Therefore, the user can customize the parameters of the dataset, such as frequency band, modulation mode, antenna gain, and so on. In addition, the proposed dataset is generated through various and complex channel environments, which aims to better characterize the radio frequency signals in the real world. We collect the dataset at transmitters and receivers to simulate a real-world RFF dataset based on the long-term evolution (LTE). Furthermore, we verify the dataset and confirm its reliability. The dataset and reproducible code of this paper can be downloaded from GitHub link: https://github.com/njuptzsp/XSRPdataset.
A Novel Channel Identification Architecture for mmWave Systems Based on Eigen Features
Apr 11, 2022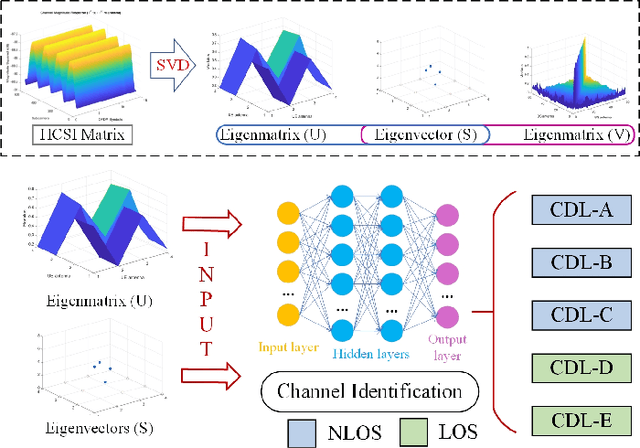
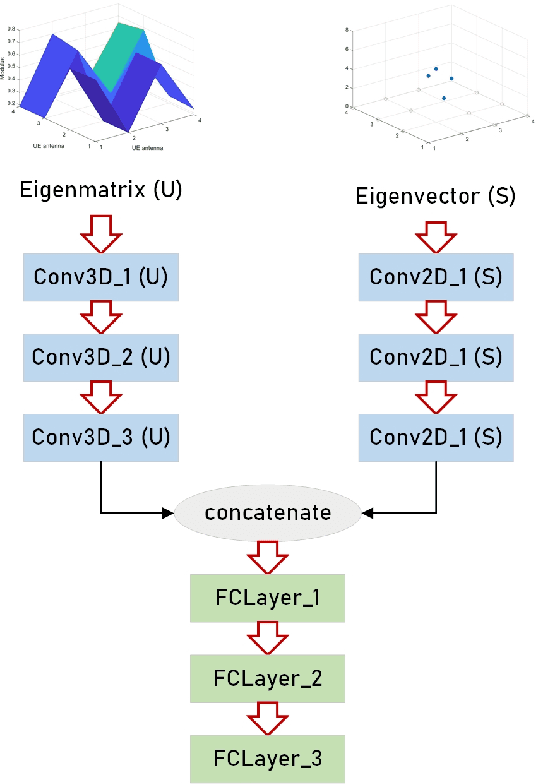
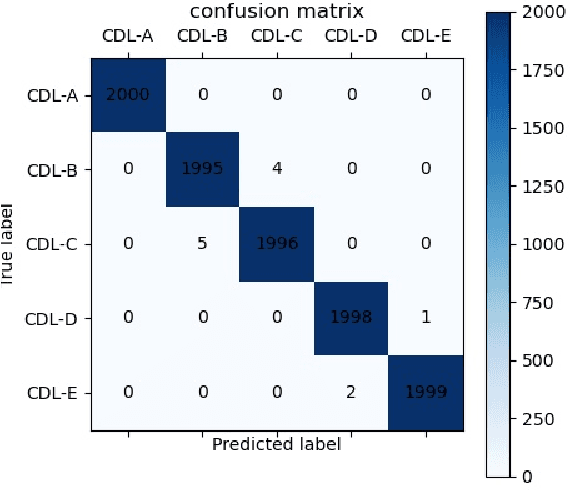
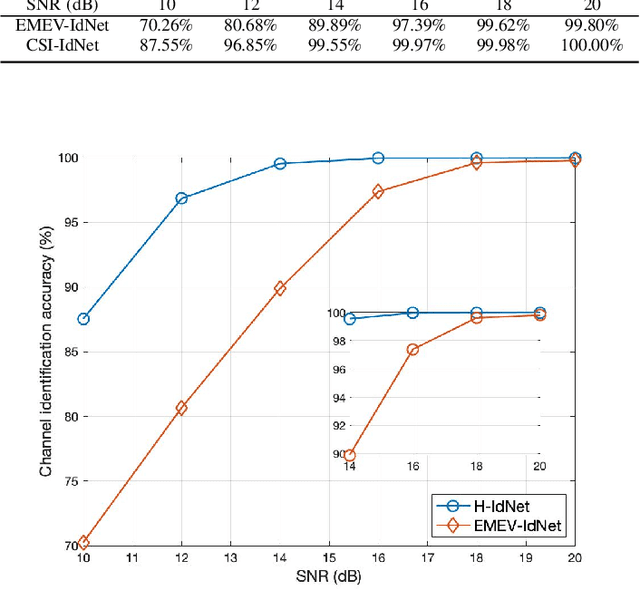
Millimeter wave (mmWave) communication technique has been developed rapidly because of many advantages of high speed, large bandwidth, and ultra-low delay. However, mmWave communications systems suffer from fast fading and frequent blocking. Hence, the ideal communication environment for mmWave is line of sight (LOS) channel. To improve the efficiency and capacity of mmWave system, and to better build the Internet of Everything (IoE) service network, this paper focuses on the channel identification technique in line-of- sight (LOS) and non-LOS (NLOS) environments. Considering the limited computing ability of user equipments (UEs), this paper proposes a novel channel identification architecture based on eigen features, i.e. eigenmatrix and eigenvector (EMEV) of channel state information (CSI). Furthermore, this paper explores clustered delay line (CDL) channel identification with mmWave, which is defined by the 3rd generation partnership project (3GPP). Ther experimental results show that the EMEV based scheme can achieve identification accuracy of 99.88% assuming perfect CSI. In the robustness test, the maximum noise can be tolerated is SNR= 16 dB, with the threshold acc \geq 95%. What is more, the novel architecture based on EMEV feature will reduce the comprehensive overhead by about 90%.