 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSR: Trajectory-Search Rollouts for Multi-Turn RL of LLM Agents
Feb 12, 2026Advances in large language models (LLMs) are driving a shift toward using reinforcement learning (RL) to train agents from iterative, multi-turn interactions across tasks. However, multi-turn RL remains challenging as rewards are often sparse or delayed, and environments can be stochastic. In this regime, naive trajectory sampling can hinder exploitation and induce mode collapse. We propose TSR (Trajectory-Search Rollouts), a training-time approach that repurposes test-time scaling ideas for improved per-turn rollout generation. TSR performs lightweight tree-style search to construct high-quality trajectories by selecting high-scoring actions at each turn using task-specific feedback. This improves rollout quality and stabilizes learning while leaving the underlying optimization objective unchanged, making TSR optimizer-agnostic. We instantiate TSR with best-of-N, beam, and shallow lookahead search, and pair it with PPO and GRPO, achieving up to 15% performance gains and more stable learning on Sokoban, FrozenLake, and WebShop tasks at a one-time increase in training compute. By moving search from inference time to the rollout stage of training, TSR provides a simple and general mechanism for stronger multi-turn agent learning, complementary to existing frameworks and rejection-sampling-style selection methods.
Real-Time Multi-Target Detection and Tracking with mmWave 5G NR Waveforms on RFSoC
Dec 27, 2025We demonstrate a real-time implementation of multi-target detection and tracking using 5G New Radio (NR) physical downlink shared channel (PDSCH) waveform with 400 MHz bandwidth at 28 GHz carrier frequency. The hardware platform is built on a radio frequency system-on-chip (RFSoC) 4x2 board connected with a pair of Sivers EVK02001 mmWave beamformers for transmission and reception. The entire sensing transceiver processing and fast beam control are realized purely in the programmable logic (PL) part of the RFSoC, enabling low-latency and fully hardware-accelerated operation. The continuously acquired sensing data constitute 3D range-angle (RA) tensors, which are processed on a host PC using adaptive background subtraction, cell-averaging constant false alarm rate (CA-CFAR) detection with density-based spatial clustering of applications with noise (DBSCAN) clustering, and extended Kalman filtering (EKF), to detect and track targets in the environment. Our software-defined radio (SDR) testbed integrates heterogeneous computing resources, including CPUs, GPUs, and FPGAs, thereby providing design flexibility for a wide range of tasks.
When Data is the Algorithm: A Systematic Study and Curation of Preference Optimization Datasets
Nov 14, 2025Aligning large language models (LLMs) is a central objective of post-training, often achieved through reward modeling and reinforcement learning methods. Among these, direct preference optimization (DPO) has emerged as a widely adopted technique that fine-tunes LLMs on preferred completions over less favorable ones. While most frontier LLMs do not disclose their curated preference pairs, the broader LLM community has released several open-source DPO datasets, including TuluDPO, ORPO, UltraFeedback, HelpSteer, and Code-Preference-Pairs. However, systematic comparisons remain scarce, largely due to the high computational cost and the lack of rich quality annotations, making it difficult to understand how preferences were selected, which task types they span, and how well they reflect human judgment on a per-sample level. In this work, we present the first comprehensive, data-centric analysis of popular open-source DPO corpora. We leverage the Magpie framework to annotate each sample for task category, input quality, and preference reward, a reward-model-based signal that validates the preference order without relying on human annotations. This enables a scalable, fine-grained inspection of preference quality across datasets, revealing structural and qualitative discrepancies in reward margins. Building on these insights, we systematically curate a new DPO mixture, UltraMix, that draws selectively from all five corpora while removing noisy or redundant samples. UltraMix is 30% smaller than the best-performing individual dataset yet exceeds its performance across key benchmarks. We publicly release all annotations, metadata, and our curated mixture to facilitate future research in data-centric preference optimization.
Variational Secret Common Randomness Extraction
Oct 02, 2025This paper studies the problem of extracting common randomness (CR) or secret keys from correlated random sources observed by two legitimate parties, Alice and Bob, through public discussion in the presence of an eavesdropper, Eve. We propose a practical two-stage CR extraction framework. In the first stage, the variational probabilistic quantization (VPQ) step is introduced, where Alice and Bob employ probabilistic neural network (NN) encoders to map their observations into discrete, nearly uniform random variables (RVs) with high agreement probability while minimizing information leakage to Eve. This is realized through a variational learning objective combined with adversarial training. In the second stage, a secure sketch using code-offset construction reconciles the encoder outputs into identical secret keys, whose secrecy is guaranteed by the VPQ objective. As a representative application, we study physical layer key (PLK) generation. Beyond the traditional methods, which rely on the channel reciprocity principle and require two-way channel probing, thus suffering from large protocol overhead and being unsuitable in high mobility scenarios, we propose a sensing-based PLK generation method for integrated sensing and communications (ISAC) systems, where paired range-angle (RA) maps measured at Alice and Bob serve as correlated sources. The idea is verified through both end-to-end simulations and real-world software-defined radio (SDR) measurements, including scenarios where Eve has partial knowledge about Bob's position. The results demonstrate the feasibility and convincing performance of both the proposed CR extraction framework and sensing-based PLK generation method.
Fixing It in Post: A Comparative Study of LLM Post-Training Data Quality and Model Performance
Jun 06, 2025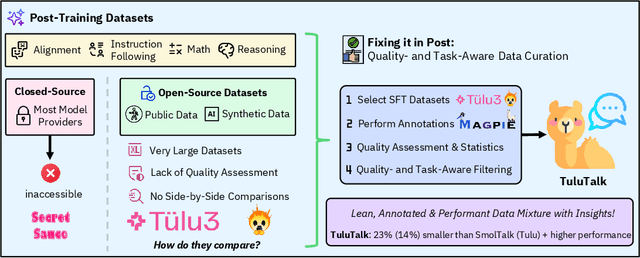


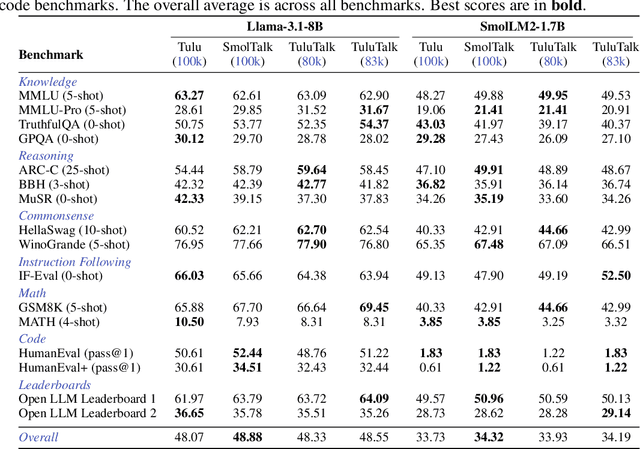
Recent work on large language models (LLMs) has increasingly focused on post-training and alignment with datasets curated to enhance instruction following, world knowledge, and specialized skills. However, most post-training datasets used in leading open- and closed-source LLMs remain inaccessible to the public, with limited information about their construction process. This lack of transparency has motivated the recent development of open-source post-training corpora. While training on these open alternatives can yield performance comparable to that of leading models, systematic comparisons remain challenging due to the significant computational cost of conducting them rigorously at scale, and are therefore largely absent. As a result, it remains unclear how specific samples, task types, or curation strategies influence downstream performance when assessing data quality. In this work, we conduct the first comprehensive side-by-side analysis of two prominent open post-training datasets: Tulu-3-SFT-Mix and SmolTalk. Using the Magpie framework, we annotate each sample with detailed quality metrics, including turn structure (single-turn vs. multi-turn), task category, input quality, and response quality, and we derive statistics that reveal structural and qualitative similarities and differences between the two datasets. Based on these insights, we design a principled curation recipe that produces a new data mixture, TuluTalk, which contains 14% fewer samples than either source dataset while matching or exceeding their performance on key benchmarks. Our findings offer actionable insights for constructing more effective post-training datasets that improve model performance within practical resource limits. To support future research, we publicly release both the annotated source datasets and our curated TuluTalk mixture.
"Don't Do That!": Guiding Embodied Systems through Large Language Model-based Constraint Generation
Jun 04, 2025



Recent advancements in large language models (LLMs) have spurred interest in robotic navigation that incorporates complex spatial, mathematical, and conditional constraints from natural language into the planning problem. Such constraints can be informal yet highly complex, making it challenging to translate into a formal description that can be passed on to a planning algorithm. In this paper, we propose STPR, a constraint generation framework that uses LLMs to translate constraints (expressed as instructions on ``what not to do'') into executable Python functions. STPR leverages the LLM's strong coding capabilities to shift the problem description from language into structured and transparent code, thus circumventing complex reasoning and avoiding potential hallucinations. We show that these LLM-generated functions accurately describe even complex mathematical constraints, and apply them to point cloud representations with traditional search algorithms. Experiments in a simulated Gazebo environment show that STPR ensures full compliance across several constraints and scenarios, while having short runtimes. We also verify that STPR can be used with smaller, code-specific LLMs, making it applicable to a wide range of compact models at low inference cost.
Computation of Capacity-Distortion-Cost Functions for Continuous Memoryless Channels
Apr 28, 2025


This paper aims at computing the capacity-distortion-cost (CDC) function for continuous memoryless channels, which is defined as the supremum of the mutual information between channel input and output, constrained by an input cost and an expected distortion of estimating channel state. Solving the optimization problem is challenging because the input distribution does not lie in a finite-dimensional Euclidean space and the optimal estimation function has no closed form in general. We propose to adopt the Wasserstein proximal point method and parametric models such as neural networks (NNs) to update the input distribution and estimation function alternately. To implement it in practice, the importance sampling (IS) technique is used to calculate integrals numerically, and the Wasserstein gradient descent is approximated by pushing forward particles. The algorithm is then applied to an integrated sensing and communications (ISAC) system, validating theoretical results at minimum and maximum distortion as well as the random-deterministic trade-off.
SafeMERGE: Preserving Safety Alignment in Fine-Tuned Large Language Models via Selective Layer-Wise Model Merging
Mar 21, 2025
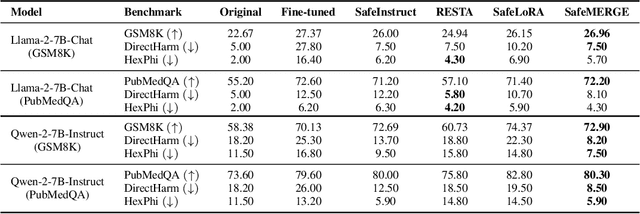
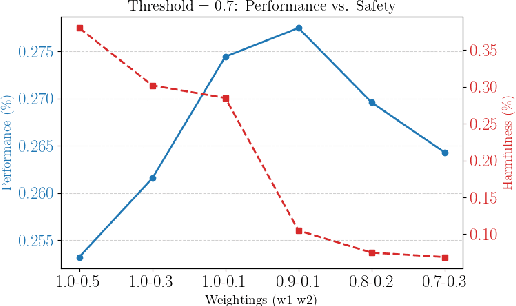
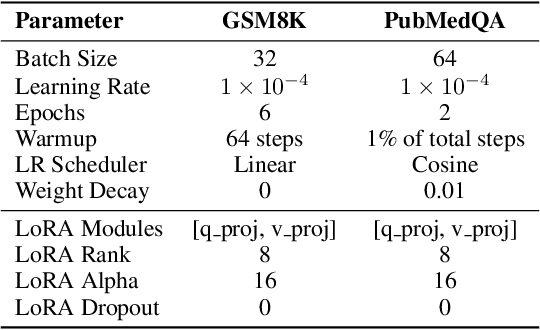
Fine-tuning large language models (LLMs) on downstream tasks can inadvertently erode their safety alignment, even for benign fine-tuning datasets. We address this challenge by proposing SafeMERGE, a post-fine-tuning framework that preserves safety while maintaining task utility. It achieves this by selectively merging fine-tuned and safety-aligned model layers only when those deviate from safe behavior, measured by a cosine similarity criterion. We evaluate SafeMERGE against other fine-tuning- and post-fine-tuning-stage approaches for Llama-2-7B-Chat and Qwen-2-7B-Instruct models on GSM8K and PubMedQA tasks while exploring different merging strategies. We find that SafeMERGE consistently reduces harmful outputs compared to other baselines without significantly sacrificing performance, sometimes even enhancing it. The results suggest that our selective, subspace-guided, and per-layer merging method provides an effective safeguard against the inadvertent loss of safety in fine-tuned LLMs while outperforming simpler post-fine-tuning-stage defenses.
Sustainable AI: Mathematical Foundations of Spiking Neural Networks
Mar 03, 2025Deep learning's success comes with growing energy demands, raising concerns about the long-term sustainability of the field. Spiking neural networks, inspired by biological neurons, offer a promising alternative with potential computational and energy-efficiency gains. This article examines the computational properties of spiking networks through the lens of learning theory, focusing on expressivity, training, and generalization, as well as energy-efficient implementations while comparing them to artificial neural networks. By categorizing spiking models based on time representation and information encoding, we highlight their strengths, challenges, and potential as an alternative computational paradigm.
$SE(3)$-Based Trajectory Optimization and Target Tracking in UAV-Enabled ISAC Systems
Jan 20, 2025


This paper introduces a novel approach to enhance the performance of UAV-enabled integrated sensing and communication (ISAC) systems. By integrating uniform planar arrays (UPAs) and modeling the UAV as a rigid body using $SE(3)$, the study addresses key challenges in existing ISAC frameworks, such as rigid-body dynamics and trajectory design. We propose a target tracking scheme based on extended Kalman filtering (EKF) in $SE(3)$ and trajectory optimization from a control signal design perspective, leveraging the conditional Posterior Cramer-Rao bound (CPCRB) to optimize performance. Numerical results demonstrate the effectiveness of the proposed method in improving target tracking and trajectory optimization for a UAV-enabled MIMO-OFDM ISAC system.