 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Probing for Membership Inference in Fine-Tuned Language Models
Dec 21, 2025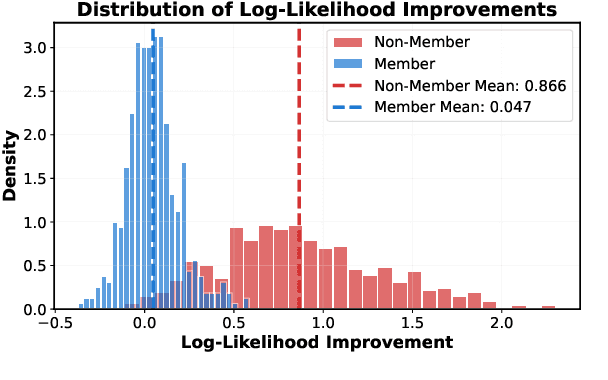
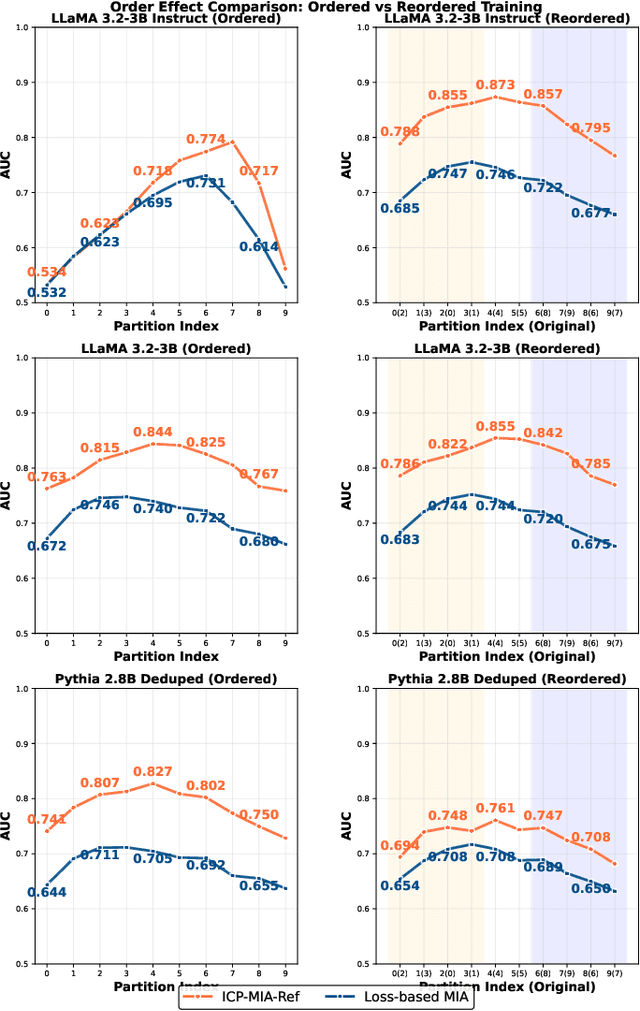
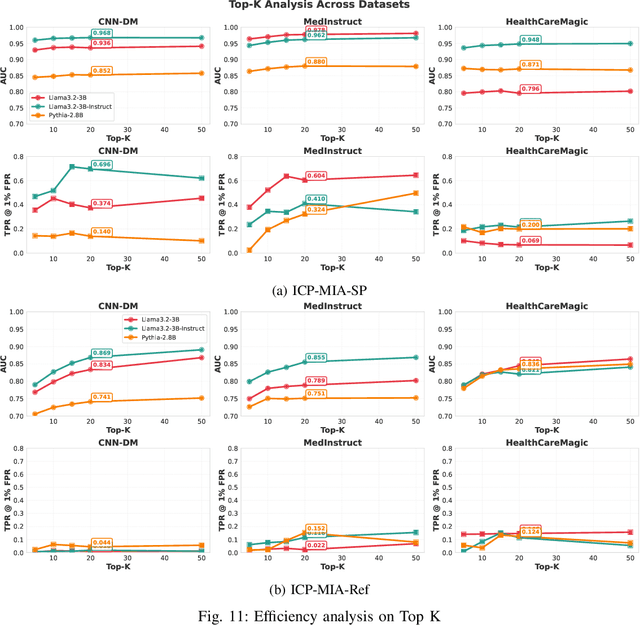
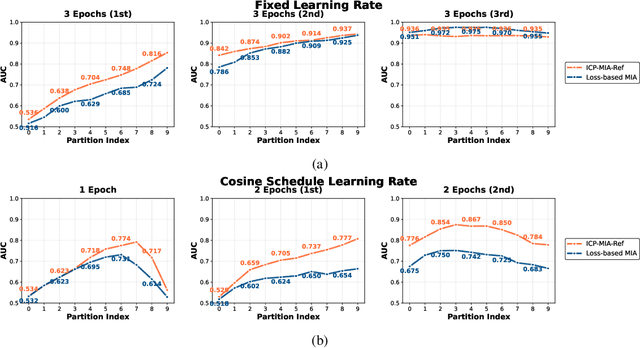
Membership inference attacks (MIAs) pose a critical privacy threat to fine-tuned large language models (LLMs), especially when models are adapted to domain-specific tasks using sensitive data. While prior black-box MIA techniques rely on confidence scores or token likelihoods, these signals are often entangled with a sample's intrinsic properties - such as content difficulty or rarity - leading to poor generalization and low signal-to-noise ratios. In this paper, we propose ICP-MIA, a novel MIA framework grounded in the theory of training dynamics, particularly the phenomenon of diminishing returns during optimization. We introduce the Optimization Gap as a fundamental signal of membership: at convergence, member samples exhibit minimal remaining loss-reduction potential, while non-members retain significant potential for further optimization. To estimate this gap in a black-box setting, we propose In-Context Probing (ICP), a training-free method that simulates fine-tuning-like behavior via strategically constructed input contexts. We propose two probing strategies: reference-data-based (using semantically similar public samples) and self-perturbation (via masking or generation). Experiments on three tasks and multiple LLMs show that ICP-MIA significantly outperforms prior black-box MIAs, particularly at low false positive rates. We further analyze how reference data alignment, model type, PEFT configurations, and training schedules affect attack effectiveness. Our findings establish ICP-MIA as a practical and theoretically grounded framework for auditing privacy risks in deployed LLMs.
When Data is the Algorithm: A Systematic Study and Curation of Preference Optimization Datasets
Nov 14, 2025Aligning large language models (LLMs) is a central objective of post-training, often achieved through reward modeling and reinforcement learning methods. Among these, direct preference optimization (DPO) has emerged as a widely adopted technique that fine-tunes LLMs on preferred completions over less favorable ones. While most frontier LLMs do not disclose their curated preference pairs, the broader LLM community has released several open-source DPO datasets, including TuluDPO, ORPO, UltraFeedback, HelpSteer, and Code-Preference-Pairs. However, systematic comparisons remain scarce, largely due to the high computational cost and the lack of rich quality annotations, making it difficult to understand how preferences were selected, which task types they span, and how well they reflect human judgment on a per-sample level. In this work, we present the first comprehensive, data-centric analysis of popular open-source DPO corpora. We leverage the Magpie framework to annotate each sample for task category, input quality, and preference reward, a reward-model-based signal that validates the preference order without relying on human annotations. This enables a scalable, fine-grained inspection of preference quality across datasets, revealing structural and qualitative discrepancies in reward margins. Building on these insights, we systematically curate a new DPO mixture, UltraMix, that draws selectively from all five corpora while removing noisy or redundant samples. UltraMix is 30% smaller than the best-performing individual dataset yet exceeds its performance across key benchmarks. We publicly release all annotations, metadata, and our curated mixture to facilitate future research in data-centric preference optimization.
Fixing It in Post: A Comparative Study of LLM Post-Training Data Quality and Model Performance
Jun 06, 2025Recent work on large language models (LLMs) has increasingly focused on post-training and alignment with datasets curated to enhance instruction following, world knowledge, and specialized skills. However, most post-training datasets used in leading open- and closed-source LLMs remain inaccessible to the public, with limited information about their construction process. This lack of transparency has motivated the recent development of open-source post-training corpora. While training on these open alternatives can yield performance comparable to that of leading models, systematic comparisons remain challenging due to the significant computational cost of conducting them rigorously at scale, and are therefore largely absent. As a result, it remains unclear how specific samples, task types, or curation strategies influence downstream performance when assessing data quality. In this work, we conduct the first comprehensive side-by-side analysis of two prominent open post-training datasets: Tulu-3-SFT-Mix and SmolTalk. Using the Magpie framework, we annotate each sample with detailed quality metrics, including turn structure (single-turn vs. multi-turn), task category, input quality, and response quality, and we derive statistics that reveal structural and qualitative similarities and differences between the two datasets. Based on these insights, we design a principled curation recipe that produces a new data mixture, TuluTalk, which contains 14% fewer samples than either source dataset while matching or exceeding their performance on key benchmarks. Our findings offer actionable insights for constructing more effective post-training datasets that improve model performance within practical resource limits. To support future research, we publicly release both the annotated source datasets and our curated TuluTalk mixture.
SafeMERGE: Preserving Safety Alignment in Fine-Tuned Large Language Models via Selective Layer-Wise Model Merging
Mar 21, 2025
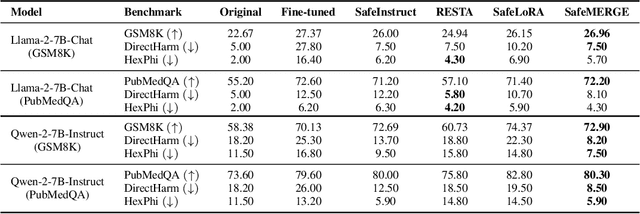
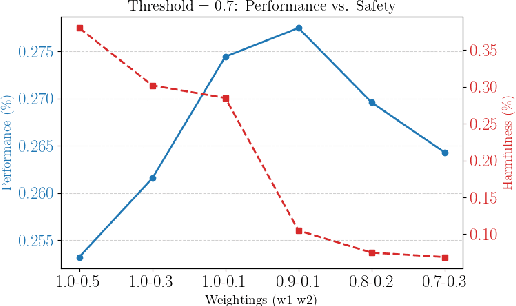
Fine-tuning large language models (LLMs) on downstream tasks can inadvertently erode their safety alignment, even for benign fine-tuning datasets. We address this challenge by proposing SafeMERGE, a post-fine-tuning framework that preserves safety while maintaining task utility. It achieves this by selectively merging fine-tuned and safety-aligned model layers only when those deviate from safe behavior, measured by a cosine similarity criterion. We evaluate SafeMERGE against other fine-tuning- and post-fine-tuning-stage approaches for Llama-2-7B-Chat and Qwen-2-7B-Instruct models on GSM8K and PubMedQA tasks while exploring different merging strategies. We find that SafeMERGE consistently reduces harmful outputs compared to other baselines without significantly sacrificing performance, sometimes even enhancing it. The results suggest that our selective, subspace-guided, and per-layer merging method provides an effective safeguard against the inadvertent loss of safety in fine-tuned LLMs while outperforming simpler post-fine-tuning-stage defenses.
GneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025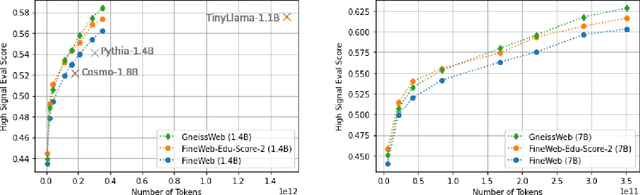
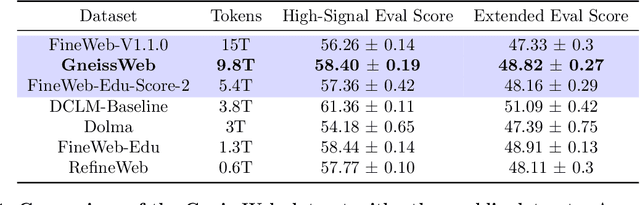
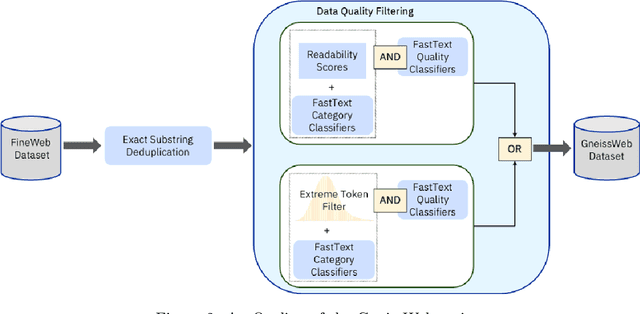

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Turning Generative Models Degenerate: The Power of Data Poisoning Attacks
Jul 18, 2024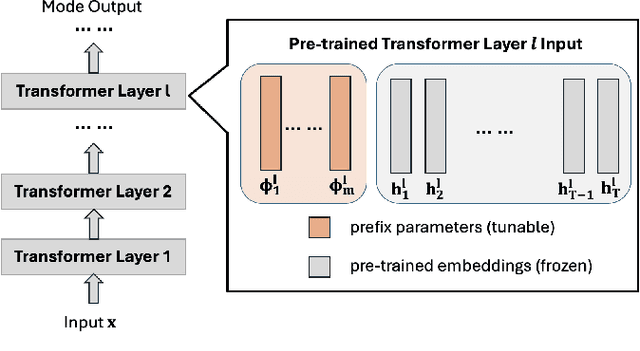
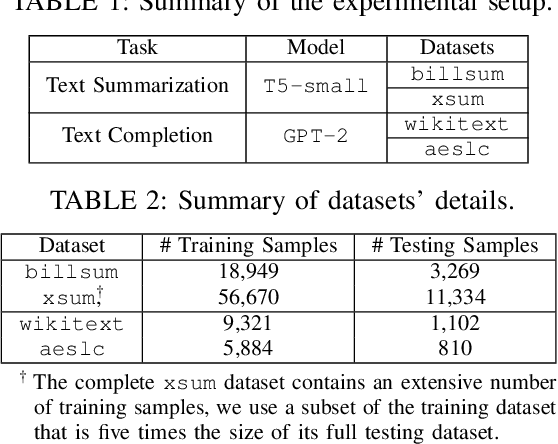
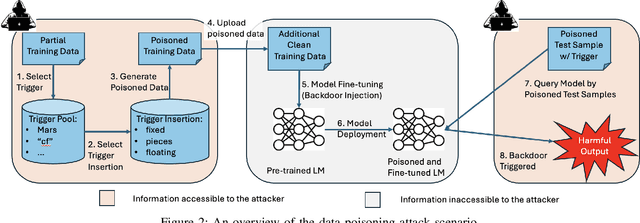

The increasing use of large language models (LLMs) trained by third parties raises significant security concerns. In particular, malicious actors can introduce backdoors through poisoning attacks to generate undesirable outputs. While such attacks have been extensively studied in image domains and classification tasks, they remain underexplored for natural language generation (NLG) tasks. To address this gap, we conduct an investigation of various poisoning techniques targeting the LLM's fine-tuning phase via prefix-tuning, a Parameter Efficient Fine-Tuning (PEFT) method. We assess their effectiveness across two generative tasks: text summarization and text completion; and we also introduce new metrics to quantify the success and stealthiness of such NLG poisoning attacks. Through our experiments, we find that the prefix-tuning hyperparameters and trigger designs are the most crucial factors to influence attack success and stealthiness. Moreover, we demonstrate that existing popular defenses are ineffective against our poisoning attacks. Our study presents the first systematic approach to understanding poisoning attacks targeting NLG tasks during fine-tuning via PEFT across a wide range of triggers and attack settings. We hope our findings will aid the AI security community in developing effective defenses against such threats.
Split, Unlearn, Merge: Leveraging Data Attributes for More Effective Unlearning in LLMs
Jun 17, 2024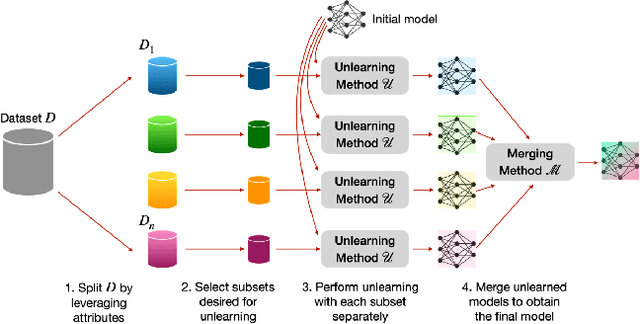
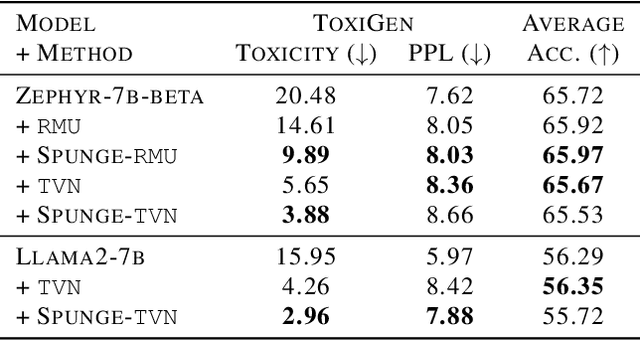
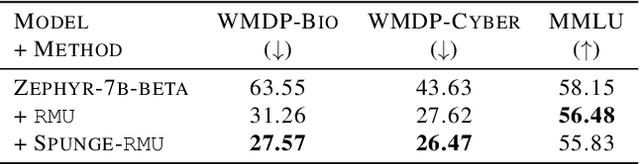
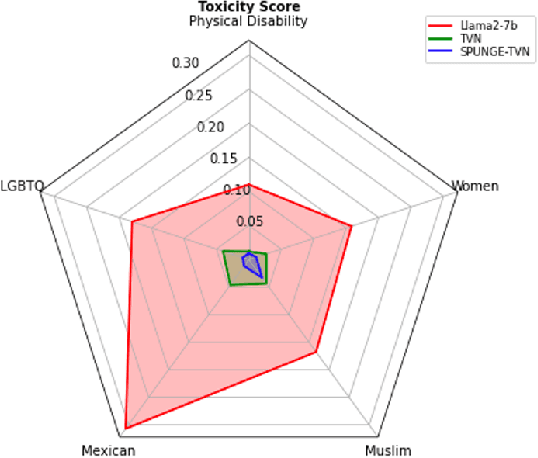
Large language models (LLMs) have shown to pose social and ethical risks such as generating toxic language or facilitating malicious use of hazardous knowledge. Machine unlearning is a promising approach to improve LLM safety by directly removing harmful behaviors and knowledge. In this paper, we propose "SPlit, UNlearn, MerGE" (SPUNGE), a framework that can be used with any unlearning method to amplify its effectiveness. SPUNGE leverages data attributes during unlearning by splitting unlearning data into subsets based on specific attribute values, unlearning each subset separately, and merging the unlearned models. We empirically demonstrate that SPUNGE significantly improves the performance of two recent unlearning methods on state-of-the-art LLMs while maintaining their general capabilities on standard academic benchmarks.
FairSISA: Ensemble Post-Processing to Improve Fairness of Unlearning in LLMs
Dec 12, 2023



Training large language models (LLMs) is a costly endeavour in terms of time and computational resources. The large amount of training data used during the unsupervised pre-training phase makes it difficult to verify all data and, unfortunately, undesirable data may be ingested during training. Re-training from scratch is impractical and has led to the creation of the 'unlearning' discipline where models are modified to "unlearn" undesirable information without retraining. However, any modification can alter the behaviour of LLMs, especially on key dimensions such as fairness. This is the first work that examines this interplay between unlearning and fairness for LLMs. In particular, we focus on a popular unlearning framework known as SISA [Bourtoule et al., 2021], which creates an ensemble of models trained on disjoint shards. We evaluate the performance-fairness trade-off for SISA, and empirically demsontrate that SISA can indeed reduce fairness in LLMs. To remedy this, we propose post-processing bias mitigation techniques for ensemble models produced by SISA. We adapt the post-processing fairness improvement technique from [Hardt et al., 2016] to design three methods that can handle model ensembles, and prove that one of the methods is an optimal fair predictor for ensemble of models. Through experimental results, we demonstrate the efficacy of our post-processing framework called 'FairSISA'.
Forcing Generative Models to Degenerate Ones: The Power of Data Poisoning Attacks
Dec 07, 2023



Growing applications of large language models (LLMs) trained by a third party raise serious concerns on the security vulnerability of LLMs.It has been demonstrated that malicious actors can covertly exploit these vulnerabilities in LLMs through poisoning attacks aimed at generating undesirable outputs. While poisoning attacks have received significant attention in the image domain (e.g., object detection), and classification tasks, their implications for generative models, particularly in the realm of natural language generation (NLG) tasks, remain poorly understood. To bridge this gap, we perform a comprehensive exploration of various poisoning techniques to assess their effectiveness across a range of generative tasks. Furthermore, we introduce a range of metrics designed to quantify the success and stealthiness of poisoning attacks specifically tailored to NLG tasks. Through extensive experiments on multiple NLG tasks, LLMs and datasets, we show that it is possible to successfully poison an LLM during the fine-tuning stage using as little as 1\% of the total tuning data samples. Our paper presents the first systematic approach to comprehend poisoning attacks targeting NLG tasks considering a wide range of triggers and attack settings. We hope our findings will assist the AI security community in devising appropriate defenses against such threats.
Privacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.