 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-component Causal Tracing in Large Language Models
Jun 02, 2026Causal tracing systematically intervenes on a large language model's (LLM's) internal representations to uncover and quantify the causal pathways linking specific inputs or computations to specific metrics of interest, quantifying the LLM's behavior. Building on previous single-component or single-layer studies, this paper presents a unified framework for causally tracing multiple components simultaneously. This framework systematically identifies the subsets of components (e.g., attention heads and multi-layer perceptron neurons) most critical to a desired target performance metric (e.g., accuracy and fairness). This is achieved by incorporating flexible interventions applied to a wide range of desired metrics. To address the combinatorial complexity of the multi-component problem, an efficient algorithm is designed that leverages soft interventions and a carefully designed metric transformation, converting the combinatorial search problem into a continuous one that can be solved efficiently under proper constraints, thereby generating proper binary decisions for selecting components. Experimental results demonstrate that the proposed method efficiently identifies subsets of the model's components that have a high impact on the target metric, outperforming existing baseline approaches. Our code is available at https://github.com/ZiruiYan/multi-component-causal-tracing.
AI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
CoFrGeNet: Continued Fraction Architectures for Language Generation
Jan 29, 2026Transformers are arguably the preferred architecture for language generation. In this paper, inspired by continued fractions, we introduce a new function class for generative modeling. The architecture family implementing this function class is named CoFrGeNets - Continued Fraction Generative Networks. We design novel architectural components based on this function class that can replace Multi-head Attention and Feed-Forward Networks in Transformer blocks while requiring much fewer parameters. We derive custom gradient formulations to optimize the proposed components more accurately and efficiently than using standard PyTorch-based gradients. Our components are a plug-in replacement requiring little change in training or inference procedures that have already been put in place for Transformer-based models thus making our approach easy to incorporate in large industrial workflows. We experiment on two very different transformer architectures GPT2-xl (1.5B) and Llama3 (3.2B), where the former we pre-train on OpenWebText and GneissWeb, while the latter we pre-train on the docling data mix which consists of nine different datasets. Results show that the performance on downstream classification, Q\& A, reasoning and text understanding tasks of our models is competitive and sometimes even superior to the original models with $\frac{2}{3}$ to $\frac{1}{2}$ the parameters and shorter pre-training time. We believe that future implementations customized to hardware will further bring out the true potential of our architectures.
ICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Highlight All the Phrases: Enhancing LLM Transparency through Visual Factuality Indicators
Aug 09, 2025Large language models (LLMs) are susceptible to generating inaccurate or false information, often referred to as "hallucinations" or "confabulations." While several technical advancements have been made to detect hallucinated content by assessing the factuality of the model's responses, there is still limited research on how to effectively communicate this information to users. To address this gap, we conducted two scenario-based experiments with a total of 208 participants to systematically compare the effects of various design strategies for communicating factuality scores by assessing participants' ratings of trust, ease in validating response accuracy, and preference. Our findings reveal that participants preferred and trusted a design in which all phrases within a response were color-coded based on factuality scores. Participants also found it easier to validate accuracy of the response in this style compared to a baseline with no style applied. Our study offers practical design guidelines for LLM application developers and designers, aimed at calibrating user trust, aligning with user preferences, and enhancing users' ability to scrutinize LLM outputs.
Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills
Jun 15, 2025Recent advances in large reasoning models (LRMs) have enabled strong chain-of-thought (CoT) generation through test-time computation. While these multi-step reasoning capabilities represent a major milestone in language model performance, they also introduce new safety risks. In this work, we present the first systematic study to revisit the problem of machine unlearning in the context of LRMs. Machine unlearning refers to the process of removing the influence of sensitive, harmful, or undesired data or knowledge from a trained model without full retraining. We show that conventional unlearning algorithms, originally designed for non-reasoning models, are inadequate for LRMs. In particular, even when final answers are successfully erased, sensitive information often persists within the intermediate reasoning steps, i.e., CoT trajectories. To address this challenge, we extend conventional unlearning and propose Reasoning-aware Representation Misdirection for Unlearning ($R^2MU$), a novel method that effectively suppresses sensitive reasoning traces and prevents the generation of associated final answers, while preserving the model's reasoning ability. Our experiments demonstrate that $R^2MU$ significantly reduces sensitive information leakage within reasoning traces and achieves strong performance across both safety and reasoning benchmarks, evaluated on state-of-the-art models such as DeepSeek-R1-Distill-LLaMA-8B and DeepSeek-R1-Distill-Qwen-14B.
CoFrNets: Interpretable Neural Architecture Inspired by Continued Fractions
Jun 05, 2025In recent years there has been a considerable amount of research on local post hoc explanations for neural networks. However, work on building interpretable neural architectures has been relatively sparse. In this paper, we present a novel neural architecture, CoFrNet, inspired by the form of continued fractions which are known to have many attractive properties in number theory, such as fast convergence of approximations to real numbers. We show that CoFrNets can be efficiently trained as well as interpreted leveraging their particular functional form. Moreover, we prove that such architectures are universal approximators based on a proof strategy that is different than the typical strategy used to prove universal approximation results for neural networks based on infinite width (or depth), which is likely to be of independent interest. We experiment on nonlinear synthetic functions and are able to accurately model as well as estimate feature attributions and even higher order terms in some cases, which is a testament to the representational power as well as interpretability of such architectures. To further showcase the power of CoFrNets, we experiment on seven real datasets spanning tabular, text and image modalities, and show that they are either comparable or significantly better than other interpretable models and multilayer perceptrons, sometimes approaching the accuracies of state-of-the-art models.
Final-Model-Only Data Attribution with a Unifying View of Gradient-Based Methods
Dec 05, 2024



Training data attribution (TDA) is the task of attributing model behavior to elements in the training data. This paper draws attention to the common setting where one has access only to the final trained model, and not the training algorithm or intermediate information from training. To serve as a gold standard for TDA in this "final-model-only" setting, we propose further training, with appropriate adjustment and averaging, to measure the sensitivity of the given model to training instances. We then unify existing gradient-based methods for TDA by showing that they all approximate the further training gold standard in different ways. We investigate empirically the quality of these gradient-based approximations to further training, for tabular, image, and text datasets and models. We find that the approximation quality of first-order methods is sometimes high but decays with the amount of further training. In contrast, the approximations given by influence function methods are more stable but surprisingly lower in quality.
Identifying Sub-networks in Neural Networks via Functionally Similar Representations
Oct 21, 2024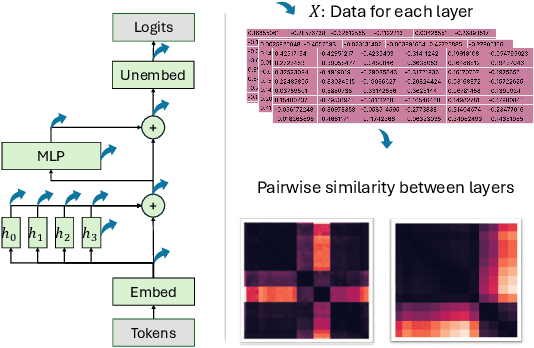
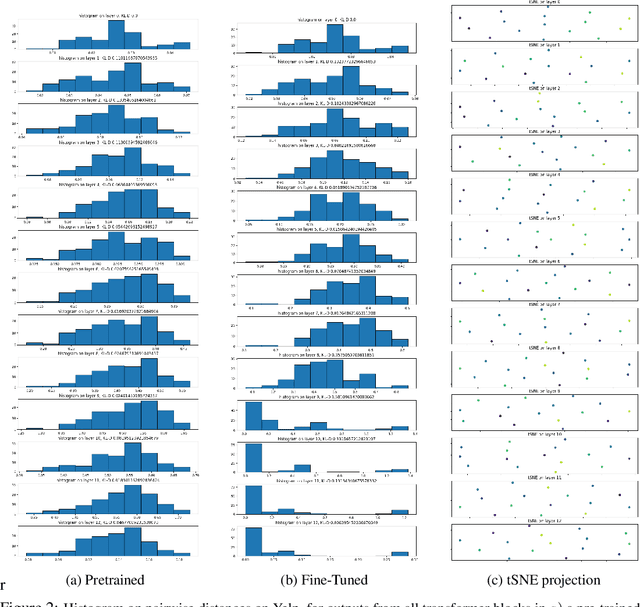

Mechanistic interpretability aims to provide human-understandable insights into the inner workings of neural network models by examining their internals. Existing approaches typically require significant manual effort and prior knowledge, with strategies tailored to specific tasks. In this work, we take a step toward automating the understanding of the network by investigating the existence of distinct sub-networks. Specifically, we explore a novel automated and task-agnostic approach based on the notion of functionally similar representations within neural networks, reducing the need for human intervention. Our method identifies similar and dissimilar layers in the network, revealing potential sub-components. We achieve this by proposing, for the first time to our knowledge, the use of Gromov-Wasserstein distance, which overcomes challenges posed by varying distributions and dimensionalities across intermediate representations, issues that complicate direct layer-to-layer comparisons. Through experiments on algebraic and language tasks, we observe the emergence of sub-groups within neural network layers corresponding to functional abstractions. Additionally, we find that different training strategies influence the positioning of these sub-groups. Our approach offers meaningful insights into the behavior of neural networks with minimal human and computational cost.
Split, Unlearn, Merge: Leveraging Data Attributes for More Effective Unlearning in LLMs
Jun 17, 2024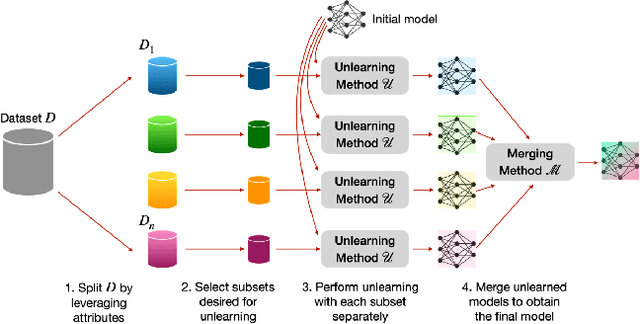
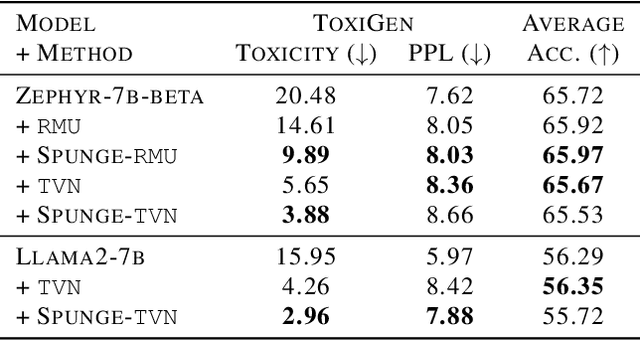
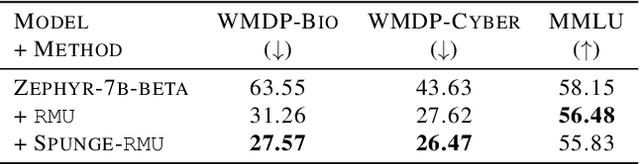
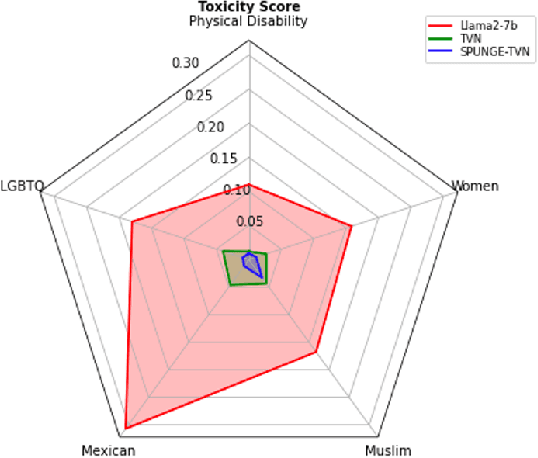
Large language models (LLMs) have shown to pose social and ethical risks such as generating toxic language or facilitating malicious use of hazardous knowledge. Machine unlearning is a promising approach to improve LLM safety by directly removing harmful behaviors and knowledge. In this paper, we propose "SPlit, UNlearn, MerGE" (SPUNGE), a framework that can be used with any unlearning method to amplify its effectiveness. SPUNGE leverages data attributes during unlearning by splitting unlearning data into subsets based on specific attribute values, unlearning each subset separately, and merging the unlearned models. We empirically demonstrate that SPUNGE significantly improves the performance of two recent unlearning methods on state-of-the-art LLMs while maintaining their general capabilities on standard academic benchmarks.