 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Unlearning for Text-to-Image Diffusion Models: A Regularization Perspective
Nov 11, 2025Machine unlearning--the ability to remove designated concepts from a pre-trained model--has advanced rapidly, particularly for text-to-image diffusion models. However, existing methods typically assume that unlearning requests arrive all at once, whereas in practice they often arrive sequentially. We present the first systematic study of continual unlearning in text-to-image diffusion models and show that popular unlearning methods suffer from rapid utility collapse: after only a few requests, models forget retained knowledge and generate degraded images. We trace this failure to cumulative parameter drift from the pre-training weights and argue that regularization is crucial to addressing it. To this end, we study a suite of add-on regularizers that (1) mitigate drift and (2) remain compatible with existing unlearning methods. Beyond generic regularizers, we show that semantic awareness is essential for preserving concepts close to the unlearning target, and propose a gradient-projection method that constrains parameter drift orthogonal to their subspace. This substantially improves continual unlearning performance and is complementary to other regularizers for further gains. Taken together, our study establishes continual unlearning as a fundamental challenge in text-to-image generation and provides insights, baselines, and open directions for advancing safe and accountable generative AI.
Downgrade to Upgrade: Optimizer Simplification Enhances Robustness in LLM Unlearning
Oct 02, 2025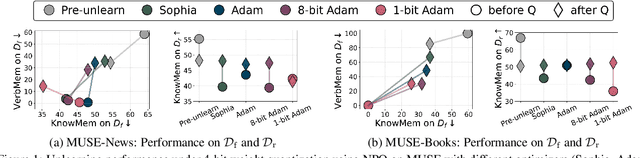
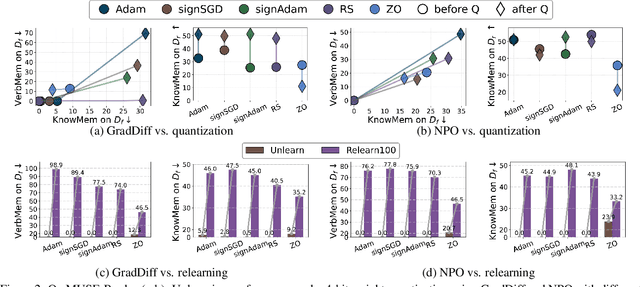

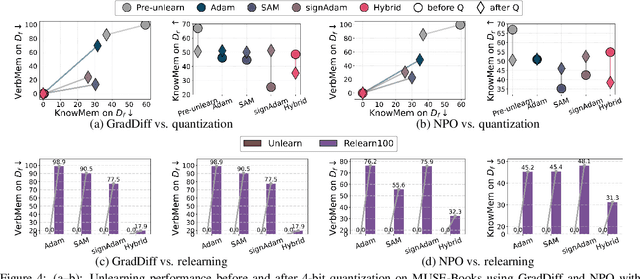
Large language model (LLM) unlearning aims to surgically remove the influence of undesired data or knowledge from an existing model while preserving its utility on unrelated tasks. This paradigm has shown promise in addressing privacy and safety concerns. However, recent findings reveal that unlearning effects are often fragile: post-unlearning manipulations such as weight quantization or fine-tuning can quickly neutralize the intended forgetting. Prior efforts to improve robustness primarily reformulate unlearning objectives by explicitly assuming the role of vulnerability sources. In this work, we take a different perspective by investigating the role of the optimizer, independent of unlearning objectives and formulations, in shaping unlearning robustness. We show that the 'grade' of the optimizer, defined by the level of information it exploits, ranging from zeroth-order (gradient-free) to first-order (gradient-based) to second-order (Hessian-based), is tightly linked to the resilience of unlearning. Surprisingly, we find that downgrading the optimizer, such as using zeroth-order methods or compressed-gradient variants (e.g., gradient sign-based optimizers), often leads to stronger robustness. While these optimizers produce noisier and less precise updates, they encourage convergence to harder-to-disturb basins in the loss landscape, thereby resisting post-training perturbations. By connecting zeroth-order methods with randomized smoothing, we further highlight their natural advantage for robust unlearning. Motivated by these insights, we propose a hybrid optimizer that combines first-order and zeroth-order updates, preserving unlearning efficacy while enhancing robustness. Extensive experiments on the MUSE and WMDP benchmarks, across multiple LLM unlearning algorithms, validate that our approach achieves more resilient forgetting without sacrificing unlearning quality.
Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills
Jun 15, 2025Recent advances in large reasoning models (LRMs) have enabled strong chain-of-thought (CoT) generation through test-time computation. While these multi-step reasoning capabilities represent a major milestone in language model performance, they also introduce new safety risks. In this work, we present the first systematic study to revisit the problem of machine unlearning in the context of LRMs. Machine unlearning refers to the process of removing the influence of sensitive, harmful, or undesired data or knowledge from a trained model without full retraining. We show that conventional unlearning algorithms, originally designed for non-reasoning models, are inadequate for LRMs. In particular, even when final answers are successfully erased, sensitive information often persists within the intermediate reasoning steps, i.e., CoT trajectories. To address this challenge, we extend conventional unlearning and propose Reasoning-aware Representation Misdirection for Unlearning ($R^2MU$), a novel method that effectively suppresses sensitive reasoning traces and prevents the generation of associated final answers, while preserving the model's reasoning ability. Our experiments demonstrate that $R^2MU$ significantly reduces sensitive information leakage within reasoning traces and achieves strong performance across both safety and reasoning benchmarks, evaluated on state-of-the-art models such as DeepSeek-R1-Distill-LLaMA-8B and DeepSeek-R1-Distill-Qwen-14B.
EPiC: Towards Lossless Speedup for Reasoning Training through Edge-Preserving CoT Condensation
Jun 04, 2025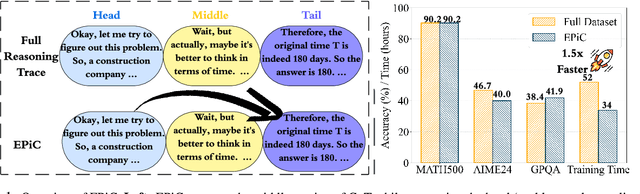
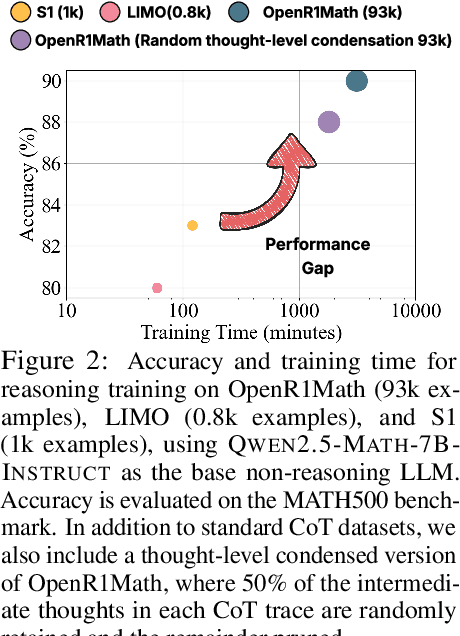

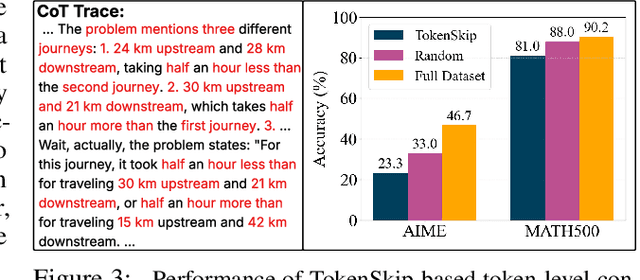
Large language models (LLMs) have shown remarkable reasoning capabilities when trained with chain-of-thought (CoT) supervision. However, the long and verbose CoT traces, especially those distilled from large reasoning models (LRMs) such as DeepSeek-R1, significantly increase training costs during the distillation process, where a non-reasoning base model is taught to replicate the reasoning behavior of an LRM. In this work, we study the problem of CoT condensation for resource-efficient reasoning training, aimed at pruning intermediate reasoning steps (i.e., thoughts) in CoT traces, enabling supervised model training on length-reduced CoT data while preserving both answer accuracy and the model's ability to generate coherent reasoning. Our rationale is that CoT traces typically follow a three-stage structure: problem understanding, exploration, and solution convergence. Through empirical analysis, we find that retaining the structure of the reasoning trace, especially the early stage of problem understanding (rich in reflective cues) and the final stage of solution convergence, is sufficient to achieve lossless reasoning supervision. To this end, we propose an Edge-Preserving Condensation method, EPiC, which selectively retains only the initial and final segments of each CoT trace while discarding the middle portion. This design draws an analogy to preserving the "edge" of a reasoning trajectory, capturing both the initial problem framing and the final answer synthesis, to maintain logical continuity. Experiments across multiple model families (Qwen and LLaMA) and benchmarks show that EPiC reduces training time by over 34% while achieving lossless reasoning accuracy on MATH500, comparable to full CoT supervision. To the best of our knowledge, this is the first study to explore thought-level CoT condensation for efficient reasoning model distillation.
Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond
Feb 07, 2025The LLM unlearning technique has recently been introduced to comply with data regulations and address the safety and ethical concerns of LLMs by removing the undesired data-model influence. However, state-of-the-art unlearning methods face a critical vulnerability: they are susceptible to ``relearning'' the removed information from a small number of forget data points, known as relearning attacks. In this paper, we systematically investigate how to make unlearned models robust against such attacks. For the first time, we establish a connection between robust unlearning and sharpness-aware minimization (SAM) through a unified robust optimization framework, in an analogy to adversarial training designed to defend against adversarial attacks. Our analysis for SAM reveals that smoothness optimization plays a pivotal role in mitigating relearning attacks. Thus, we further explore diverse smoothing strategies to enhance unlearning robustness. Extensive experiments on benchmark datasets, including WMDP and MUSE, demonstrate that SAM and other smoothness optimization approaches consistently improve the resistance of LLM unlearning to relearning attacks. Notably, smoothness-enhanced unlearning also helps defend against (input-level) jailbreaking attacks, broadening our proposal's impact in robustifying LLM unlearning. Codes are available at https://github.com/OPTML-Group/Unlearn-Smooth.
Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning
Oct 09, 2024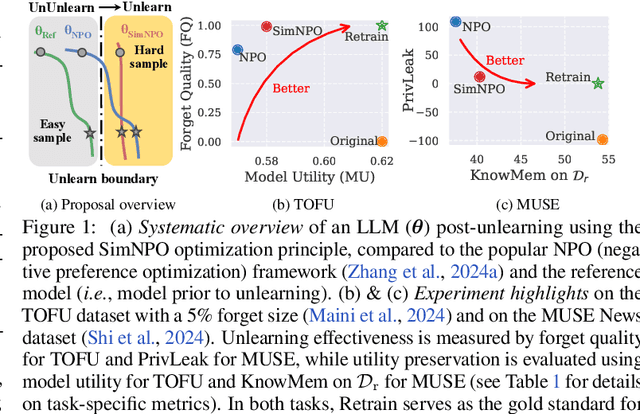
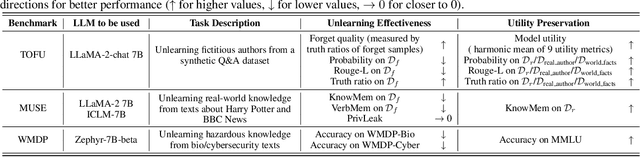
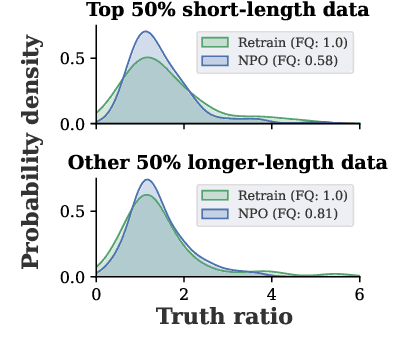
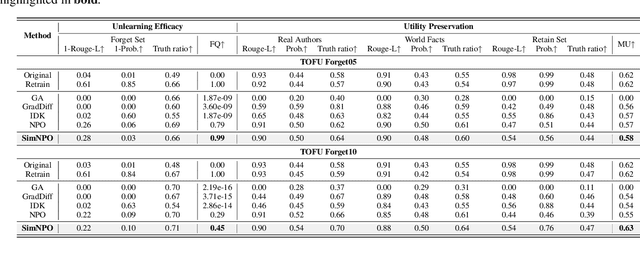
In this work, we address the problem of large language model (LLM) unlearning, aiming to remove unwanted data influences and associated model capabilities (e.g., copyrighted data or harmful content generation) while preserving essential model utilities, without the need for retraining from scratch. Despite the growing need for LLM unlearning, a principled optimization framework remains lacking. To this end, we revisit the state-of-the-art approach, negative preference optimization (NPO), and identify the issue of reference model bias, which could undermine NPO's effectiveness, particularly when unlearning forget data of varying difficulty. Given that, we propose a simple yet effective unlearning optimization framework, called SimNPO, showing that 'simplicity' in removing the reliance on a reference model (through the lens of simple preference optimization) benefits unlearning. We also provide deeper insights into SimNPO's advantages, supported by analysis using mixtures of Markov chains. Furthermore, we present extensive experiments validating SimNPO's superiority over existing unlearning baselines in benchmarks like TOFU and MUSE, and robustness against relearning attacks. Codes are available at https://github.com/OPTML-Group/Unlearn-Simple.
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
May 24, 2024
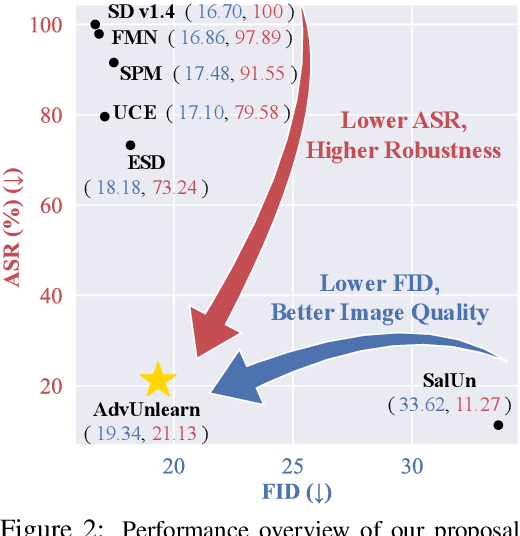
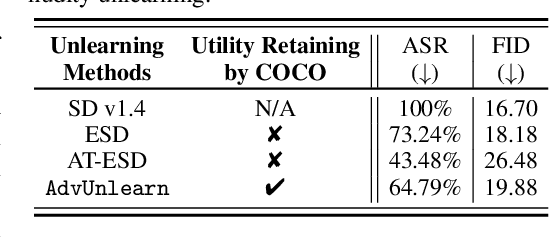

Diffusion models (DMs) have achieved remarkable success in text-to-image generation, but they also pose safety risks, such as the potential generation of harmful content and copyright violations. The techniques of machine unlearning, also known as concept erasing, have been developed to address these risks. However, these techniques remain vulnerable to adversarial prompt attacks, which can prompt DMs post-unlearning to regenerate undesired images containing concepts (such as nudity) meant to be erased. This work aims to enhance the robustness of concept erasing by integrating the principle of adversarial training (AT) into machine unlearning, resulting in the robust unlearning framework referred to as AdvUnlearn. However, achieving this effectively and efficiently is highly nontrivial. First, we find that a straightforward implementation of AT compromises DMs' image generation quality post-unlearning. To address this, we develop a utility-retaining regularization on an additional retain set, optimizing the trade-off between concept erasure robustness and model utility in AdvUnlearn. Moreover, we identify the text encoder as a more suitable module for robustification compared to UNet, ensuring unlearning effectiveness. And the acquired text encoder can serve as a plug-and-play robust unlearner for various DM types. Empirically, we perform extensive experiments to demonstrate the robustness advantage of AdvUnlearn across various DM unlearning scenarios, including the erasure of nudity, objects, and style concepts. In addition to robustness, AdvUnlearn also achieves a balanced tradeoff with model utility. To our knowledge, this is the first work to systematically explore robust DM unlearning through AT, setting it apart from existing methods that overlook robustness in concept erasing. Codes are available at: https://github.com/OPTML-Group/AdvUnlearn
Challenging Forgets: Unveiling the Worst-Case Forget Sets in Machine Unlearning
Mar 12, 2024The trustworthy machine learning (ML) community is increasingly recognizing the crucial need for models capable of selectively 'unlearning' data points after training. This leads to the problem of machine unlearning (MU), aiming to eliminate the influence of chosen data points on model performance, while still maintaining the model's utility post-unlearning. Despite various MU methods for data influence erasure, evaluations have largely focused on random data forgetting, ignoring the vital inquiry into which subset should be chosen to truly gauge the authenticity of unlearning performance. To tackle this issue, we introduce a new evaluative angle for MU from an adversarial viewpoint. We propose identifying the data subset that presents the most significant challenge for influence erasure, i.e., pinpointing the worst-case forget set. Utilizing a bi-level optimization principle, we amplify unlearning challenges at the upper optimization level to emulate worst-case scenarios, while simultaneously engaging in standard training and unlearning at the lower level, achieving a balance between data influence erasure and model utility. Our proposal offers a worst-case evaluation of MU's resilience and effectiveness. Through extensive experiments across different datasets (including CIFAR-10, 100, CelebA, Tiny ImageNet, and ImageNet) and models (including both image classifiers and generative models), we expose critical pros and cons in existing (approximate) unlearning strategies. Our results illuminate the complex challenges of MU in practice, guiding the future development of more accurate and robust unlearning algorithms. The code is available at https://github.com/OPTML-Group/Unlearn-WorstCase.
SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation
Oct 19, 2023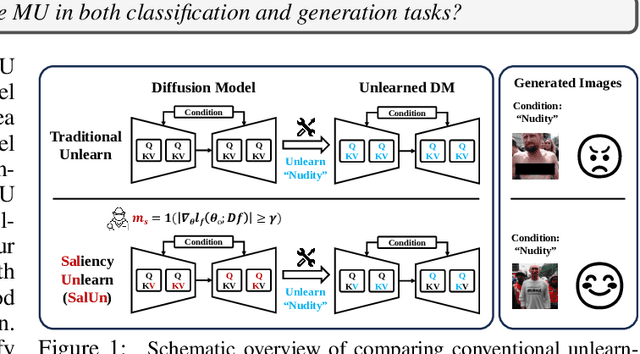
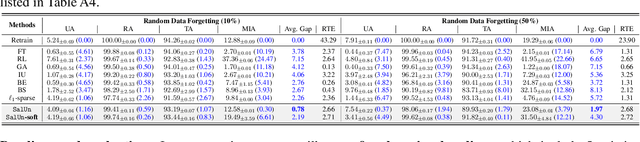
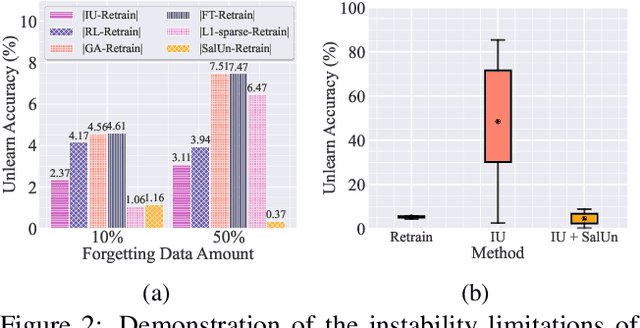
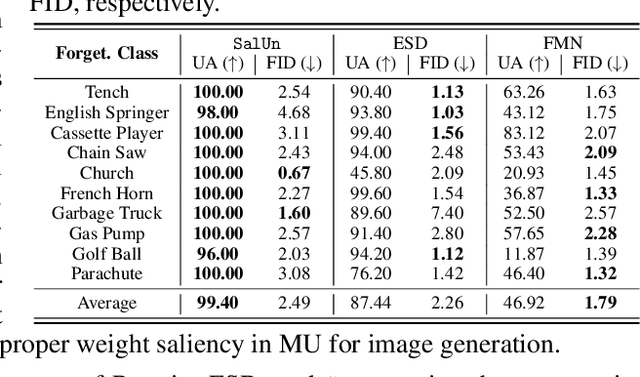
With evolving data regulations, machine unlearning (MU) has become an important tool for fostering trust and safety in today's AI models. However, existing MU methods focusing on data and/or weight perspectives often grapple with limitations in unlearning accuracy, stability, and cross-domain applicability. To address these challenges, we introduce the concept of 'weight saliency' in MU, drawing parallels with input saliency in model explanation. This innovation directs MU's attention toward specific model weights rather than the entire model, improving effectiveness and efficiency. The resultant method that we call saliency unlearning (SalUn) narrows the performance gap with 'exact' unlearning (model retraining from scratch after removing the forgetting dataset). To the best of our knowledge, SalUn is the first principled MU approach adaptable enough to effectively erase the influence of forgetting data, classes, or concepts in both image classification and generation. For example, SalUn yields a stability advantage in high-variance random data forgetting, e.g., with a 0.2% gap compared to exact unlearning on the CIFAR-10 dataset. Moreover, in preventing conditional diffusion models from generating harmful images, SalUn achieves nearly 100% unlearning accuracy, outperforming current state-of-the-art baselines like Erased Stable Diffusion and Forget-Me-Not.