 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowering Up Zeroth-Order Training via Subspace Gradient Orthogonalization
Feb 19, 2026Zeroth-order (ZO) optimization provides a gradient-free alternative to first-order (FO) methods by estimating gradients via finite differences of function evaluations, and has recently emerged as a memory-efficient paradigm for fine-tuning large-scale models by avoiding backpropagation. However, ZO optimization has a fundamental tension between accuracy and query efficiency. In this work, we show that ZO optimization can be substantially improved by unifying two complementary principles: (i) a projection-based subspace view that reduces gradient estimation variance by exploiting the intrinsic low-rank structure of model updates, and (ii) Muon-style spectral optimization that applies gradient orthogonalization to extract informative spectral structure from noisy ZO gradients. These findings form a unified framework of subspace gradient orthogonalization, which we instantiate in a new method, ZO-Muon, admitting a natural interpretation as a low-rank Muon optimizer in the ZO setting. Extensive experiments on large language models (LLMs) and vision transformers (ViTs) demonstrate that ZO-Muon significantly accelerates convergence and achieves a win-win improvement in accuracy and query/runtime efficiency. Notably, compared to the popular MeZO baseline, ZO-Muon requires only 24.7% of the queries to reach the same SST-2 performance for LLM fine-tuning, and improves accuracy by 25.1% on ViT-B fine-tuning on CIFAR-100.
Downgrade to Upgrade: Optimizer Simplification Enhances Robustness in LLM Unlearning
Oct 02, 2025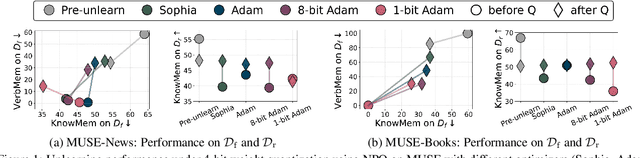
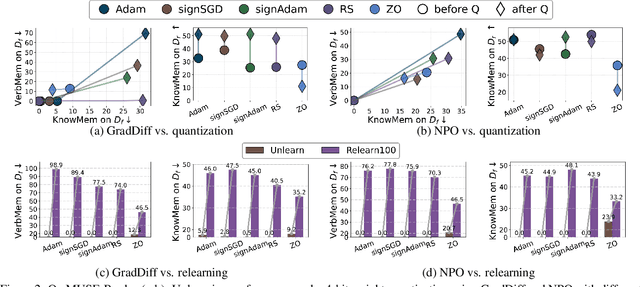

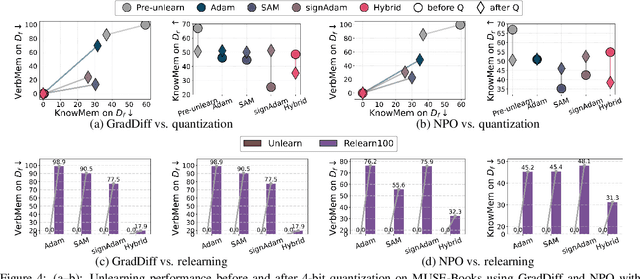
Large language model (LLM) unlearning aims to surgically remove the influence of undesired data or knowledge from an existing model while preserving its utility on unrelated tasks. This paradigm has shown promise in addressing privacy and safety concerns. However, recent findings reveal that unlearning effects are often fragile: post-unlearning manipulations such as weight quantization or fine-tuning can quickly neutralize the intended forgetting. Prior efforts to improve robustness primarily reformulate unlearning objectives by explicitly assuming the role of vulnerability sources. In this work, we take a different perspective by investigating the role of the optimizer, independent of unlearning objectives and formulations, in shaping unlearning robustness. We show that the 'grade' of the optimizer, defined by the level of information it exploits, ranging from zeroth-order (gradient-free) to first-order (gradient-based) to second-order (Hessian-based), is tightly linked to the resilience of unlearning. Surprisingly, we find that downgrading the optimizer, such as using zeroth-order methods or compressed-gradient variants (e.g., gradient sign-based optimizers), often leads to stronger robustness. While these optimizers produce noisier and less precise updates, they encourage convergence to harder-to-disturb basins in the loss landscape, thereby resisting post-training perturbations. By connecting zeroth-order methods with randomized smoothing, we further highlight their natural advantage for robust unlearning. Motivated by these insights, we propose a hybrid optimizer that combines first-order and zeroth-order updates, preserving unlearning efficacy while enhancing robustness. Extensive experiments on the MUSE and WMDP benchmarks, across multiple LLM unlearning algorithms, validate that our approach achieves more resilient forgetting without sacrificing unlearning quality.
Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills
Jun 15, 2025Recent advances in large reasoning models (LRMs) have enabled strong chain-of-thought (CoT) generation through test-time computation. While these multi-step reasoning capabilities represent a major milestone in language model performance, they also introduce new safety risks. In this work, we present the first systematic study to revisit the problem of machine unlearning in the context of LRMs. Machine unlearning refers to the process of removing the influence of sensitive, harmful, or undesired data or knowledge from a trained model without full retraining. We show that conventional unlearning algorithms, originally designed for non-reasoning models, are inadequate for LRMs. In particular, even when final answers are successfully erased, sensitive information often persists within the intermediate reasoning steps, i.e., CoT trajectories. To address this challenge, we extend conventional unlearning and propose Reasoning-aware Representation Misdirection for Unlearning ($R^2MU$), a novel method that effectively suppresses sensitive reasoning traces and prevents the generation of associated final answers, while preserving the model's reasoning ability. Our experiments demonstrate that $R^2MU$ significantly reduces sensitive information leakage within reasoning traces and achieves strong performance across both safety and reasoning benchmarks, evaluated on state-of-the-art models such as DeepSeek-R1-Distill-LLaMA-8B and DeepSeek-R1-Distill-Qwen-14B.
When is Task Vector Provably Effective for Model Editing? A Generalization Analysis of Nonlinear Transformers
Apr 15, 2025Task arithmetic refers to editing the pre-trained model by adding a weighted sum of task vectors, each of which is the weight update from the pre-trained model to fine-tuned models for certain tasks. This approach recently gained attention as a computationally efficient inference method for model editing, e.g., multi-task learning, forgetting, and out-of-domain generalization capabilities. However, the theoretical understanding of why task vectors can execute various conceptual operations remains limited, due to the highly non-convexity of training Transformer-based models. To the best of our knowledge, this paper provides the first theoretical characterization of the generalization guarantees of task vector methods on nonlinear Transformers. We consider a conceptual learning setting, where each task is a binary classification problem based on a discriminative pattern. We theoretically prove the effectiveness of task addition in simultaneously learning a set of irrelevant or aligned tasks, as well as the success of task negation in unlearning one task from irrelevant or contradictory tasks. Moreover, we prove the proper selection of linear coefficients for task arithmetic to achieve guaranteed generalization to out-of-domain tasks. All of our theoretical results hold for both dense-weight parameters and their low-rank approximations. Although established in a conceptual setting, our theoretical findings were validated on a practical machine unlearning task using the large language model Phi-1.5 (1.3B).
Safety Mirage: How Spurious Correlations Undermine VLM Safety Fine-tuning
Mar 14, 2025Recent vision-language models (VLMs) have made remarkable strides in generative modeling with multimodal inputs, particularly text and images. However, their susceptibility to generating harmful content when exposed to unsafe queries raises critical safety concerns. While current alignment strategies primarily rely on supervised safety fine-tuning with curated datasets, we identify a fundamental limitation we call the "safety mirage" where supervised fine-tuning inadvertently reinforces spurious correlations between superficial textual patterns and safety responses, rather than fostering deep, intrinsic mitigation of harm. We show that these spurious correlations leave fine-tuned VLMs vulnerable even to a simple one-word modification-based attack, where substituting a single word in text queries with a spurious correlation-inducing alternative can effectively bypass safeguards. Additionally, these correlations contribute to the over prudence, causing fine-tuned VLMs to refuse benign queries unnecessarily. To address this issue, we show machine unlearning (MU) as a powerful alternative to supervised safety fine-tuning as it avoids biased feature-label mappings and directly removes harmful knowledge from VLMs while preserving their general capabilities. Extensive evaluations across safety benchmarks show that under one-word attacks, MU-based alignment reduces the attack success rate by up to 60.17% and cuts unnecessary rejections by over 84.20%. Codes are available at https://github.com/OPTML-Group/VLM-Safety-MU. WARNING: There exist AI generations that may be offensive in nature.
Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond
Feb 07, 2025The LLM unlearning technique has recently been introduced to comply with data regulations and address the safety and ethical concerns of LLMs by removing the undesired data-model influence. However, state-of-the-art unlearning methods face a critical vulnerability: they are susceptible to ``relearning'' the removed information from a small number of forget data points, known as relearning attacks. In this paper, we systematically investigate how to make unlearned models robust against such attacks. For the first time, we establish a connection between robust unlearning and sharpness-aware minimization (SAM) through a unified robust optimization framework, in an analogy to adversarial training designed to defend against adversarial attacks. Our analysis for SAM reveals that smoothness optimization plays a pivotal role in mitigating relearning attacks. Thus, we further explore diverse smoothing strategies to enhance unlearning robustness. Extensive experiments on benchmark datasets, including WMDP and MUSE, demonstrate that SAM and other smoothness optimization approaches consistently improve the resistance of LLM unlearning to relearning attacks. Notably, smoothness-enhanced unlearning also helps defend against (input-level) jailbreaking attacks, broadening our proposal's impact in robustifying LLM unlearning. Codes are available at https://github.com/OPTML-Group/Unlearn-Smooth.
Forget Vectors at Play: Universal Input Perturbations Driving Machine Unlearning in Image Classification
Dec 21, 2024



Machine unlearning (MU), which seeks to erase the influence of specific unwanted data from already-trained models, is becoming increasingly vital in model editing, particularly to comply with evolving data regulations like the ``right to be forgotten''. Conventional approaches are predominantly model-based, typically requiring retraining or fine-tuning the model's weights to meet unlearning requirements. In this work, we approach the MU problem from a novel input perturbation-based perspective, where the model weights remain intact throughout the unlearning process. We demonstrate the existence of a proactive input-based unlearning strategy, referred to forget vector, which can be generated as an input-agnostic data perturbation and remains as effective as model-based approximate unlearning approaches. We also explore forget vector arithmetic, whereby multiple class-specific forget vectors are combined through simple operations (e.g., linear combinations) to generate new forget vectors for unseen unlearning tasks, such as forgetting arbitrary subsets across classes. Extensive experiments validate the effectiveness and adaptability of the forget vector, showcasing its competitive performance relative to state-of-the-art model-based methods. Codes are available at https://github.com/Changchangsun/Forget-Vector.
UOE: Unlearning One Expert Is Enough For Mixture-of-experts LLMS
Nov 27, 2024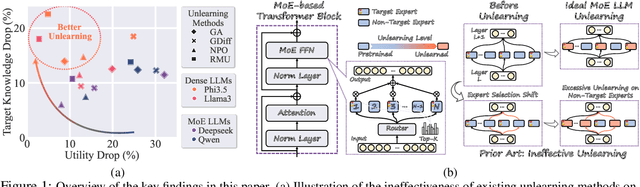

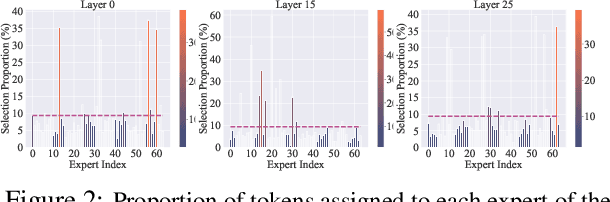
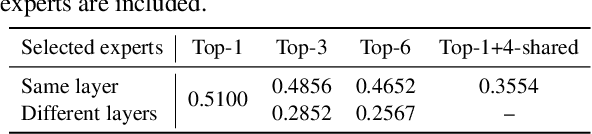
Recent advancements in large language model (LLM) unlearning have shown remarkable success in removing unwanted data-model influences while preserving the model's utility for legitimate knowledge. However, despite these strides, sparse Mixture-of-Experts (MoE) LLMs--a key subset of the LLM family--have received little attention and remain largely unexplored in the context of unlearning. As MoE LLMs are celebrated for their exceptional performance and highly efficient inference processes, we ask: How can unlearning be performed effectively and efficiently on MoE LLMs? And will traditional unlearning methods be applicable to MoE architectures? Our pilot study shows that the dynamic routing nature of MoE LLMs introduces unique challenges, leading to substantial utility drops when existing unlearning methods are applied. Specifically, unlearning disrupts the router's expert selection, causing significant selection shift from the most unlearning target-related experts to irrelevant ones. As a result, more experts than necessary are affected, leading to excessive forgetting and loss of control over which knowledge is erased. To address this, we propose a novel single-expert unlearning framework, referred to as UOE, for MoE LLMs. Through expert attribution, unlearning is concentrated on the most actively engaged expert for the specified knowledge. Concurrently, an anchor loss is applied to the router to stabilize the active state of this targeted expert, ensuring focused and controlled unlearning that preserves model utility. The proposed UOE framework is also compatible with various unlearning algorithms. Extensive experiments demonstrate that UOE enhances both forget quality up to 5% and model utility by 35% on MoE LLMs across various benchmarks, LLM architectures, while only unlearning 0.06% of the model parameters.
Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing
Nov 25, 2024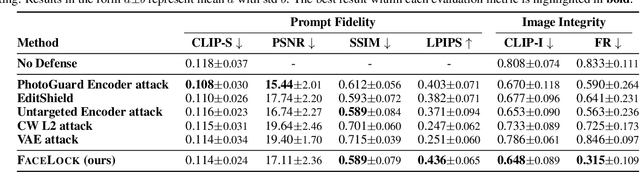
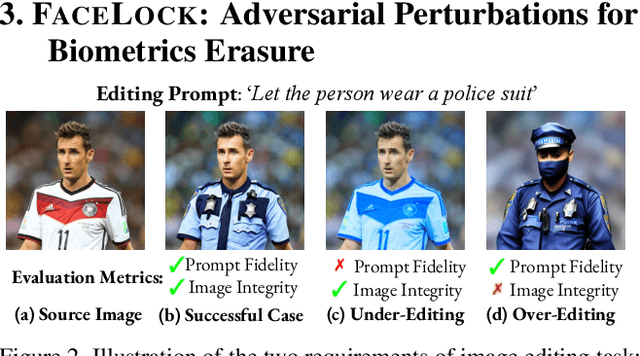
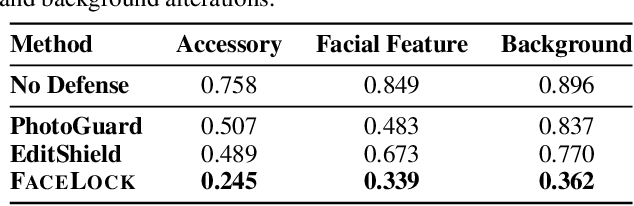

Recent advancements in diffusion models have made generative image editing more accessible, enabling creative edits but raising ethical concerns, particularly regarding malicious edits to human portraits that threaten privacy and identity security. Existing protection methods primarily rely on adversarial perturbations to nullify edits but often fail against diverse editing requests. We propose FaceLock, a novel approach to portrait protection that optimizes adversarial perturbations to destroy or significantly alter biometric information, rendering edited outputs biometrically unrecognizable. FaceLock integrates facial recognition and visual perception into perturbation optimization to provide robust protection against various editing attempts. We also highlight flaws in commonly used evaluation metrics and reveal how they can be manipulated, emphasizing the need for reliable assessments of protection. Experiments show FaceLock outperforms baselines in defending against malicious edits and is robust against purification techniques. Ablation studies confirm its stability and broad applicability across diffusion-based editing algorithms. Our work advances biometric defense and sets the foundation for privacy-preserving practices in image editing. The code is available at: https://github.com/taco-group/FaceLock.
WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
Oct 23, 2024The need for effective unlearning mechanisms in large language models (LLMs) is increasingly urgent, driven by the necessity to adhere to data regulations and foster ethical generative AI practices. Despite growing interest of LLM unlearning, much of the existing research has focused on varied unlearning method designs to boost effectiveness and efficiency. However, the inherent relationship between model weights and LLM unlearning has not been extensively examined. In this paper, we systematically explore how model weights interact with unlearning processes in LLMs and we design the weight attribution-guided LLM unlearning method, WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE can erase the undesired content, while maintaining the performance of the original tasks. We refer to the weight attribution-guided LLM unlearning method as WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. Our extensive experiments show that WAGLE boosts unlearning performance across a range of LLM unlearning methods such as gradient difference and (negative) preference optimization, applications such as fictitious unlearning, malicious use prevention, and copyrighted information removal, and models including Zephyr-7b-beta and Llama2-7b. To the best of our knowledge, our work offers the first principled method for attributing and pinpointing the influential weights in enhancing LLM unlearning. It stands in contrast to previous methods that lack weight attribution and simpler weight attribution techniques.