 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Forget Vectors at Play: Universal Input Perturbations Driving Machine Unlearning in Image Classification
Dec 21, 2024



Machine unlearning (MU), which seeks to erase the influence of specific unwanted data from already-trained models, is becoming increasingly vital in model editing, particularly to comply with evolving data regulations like the ``right to be forgotten''. Conventional approaches are predominantly model-based, typically requiring retraining or fine-tuning the model's weights to meet unlearning requirements. In this work, we approach the MU problem from a novel input perturbation-based perspective, where the model weights remain intact throughout the unlearning process. We demonstrate the existence of a proactive input-based unlearning strategy, referred to forget vector, which can be generated as an input-agnostic data perturbation and remains as effective as model-based approximate unlearning approaches. We also explore forget vector arithmetic, whereby multiple class-specific forget vectors are combined through simple operations (e.g., linear combinations) to generate new forget vectors for unseen unlearning tasks, such as forgetting arbitrary subsets across classes. Extensive experiments validate the effectiveness and adaptability of the forget vector, showcasing its competitive performance relative to state-of-the-art model-based methods. Codes are available at https://github.com/Changchangsun/Forget-Vector.
WAGLE: Strategic Weight Attribution for Effective and Modular Unlearning in Large Language Models
Oct 23, 2024The need for effective unlearning mechanisms in large language models (LLMs) is increasingly urgent, driven by the necessity to adhere to data regulations and foster ethical generative AI practices. Despite growing interest of LLM unlearning, much of the existing research has focused on varied unlearning method designs to boost effectiveness and efficiency. However, the inherent relationship between model weights and LLM unlearning has not been extensively examined. In this paper, we systematically explore how model weights interact with unlearning processes in LLMs and we design the weight attribution-guided LLM unlearning method, WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE can erase the undesired content, while maintaining the performance of the original tasks. We refer to the weight attribution-guided LLM unlearning method as WAGLE, which unveils the interconnections between 'influence' of weights and 'influence' of data to forget and retain in LLM generation. Our extensive experiments show that WAGLE boosts unlearning performance across a range of LLM unlearning methods such as gradient difference and (negative) preference optimization, applications such as fictitious unlearning, malicious use prevention, and copyrighted information removal, and models including Zephyr-7b-beta and Llama2-7b. To the best of our knowledge, our work offers the first principled method for attributing and pinpointing the influential weights in enhancing LLM unlearning. It stands in contrast to previous methods that lack weight attribution and simpler weight attribution techniques.
Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning
Oct 09, 2024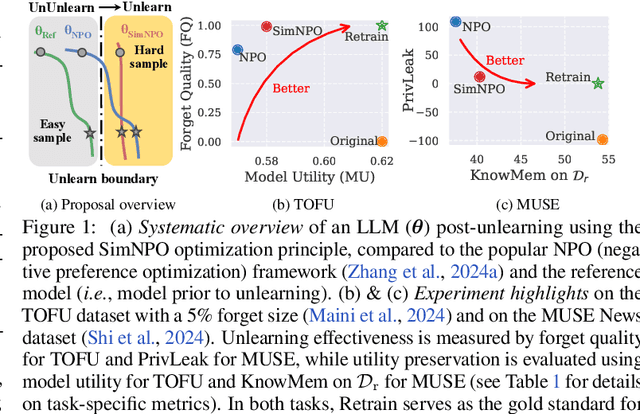
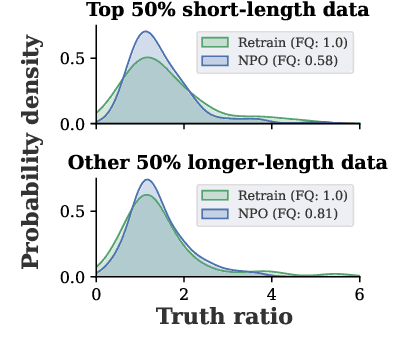
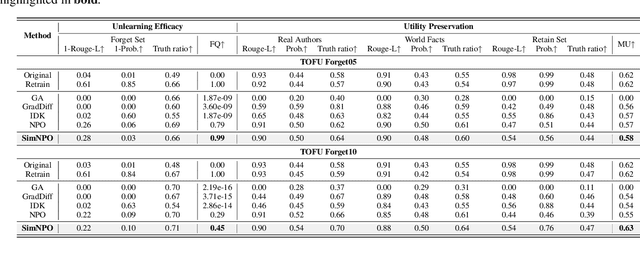
In this work, we address the problem of large language model (LLM) unlearning, aiming to remove unwanted data influences and associated model capabilities (e.g., copyrighted data or harmful content generation) while preserving essential model utilities, without the need for retraining from scratch. Despite the growing need for LLM unlearning, a principled optimization framework remains lacking. To this end, we revisit the state-of-the-art approach, negative preference optimization (NPO), and identify the issue of reference model bias, which could undermine NPO's effectiveness, particularly when unlearning forget data of varying difficulty. Given that, we propose a simple yet effective unlearning optimization framework, called SimNPO, showing that 'simplicity' in removing the reliance on a reference model (through the lens of simple preference optimization) benefits unlearning. We also provide deeper insights into SimNPO's advantages, supported by analysis using mixtures of Markov chains. Furthermore, we present extensive experiments validating SimNPO's superiority over existing unlearning baselines in benchmarks like TOFU and MUSE, and robustness against relearning attacks. Codes are available at https://github.com/OPTML-Group/Unlearn-Simple.
Towards Universal Mesh Movement Networks
Jul 02, 2024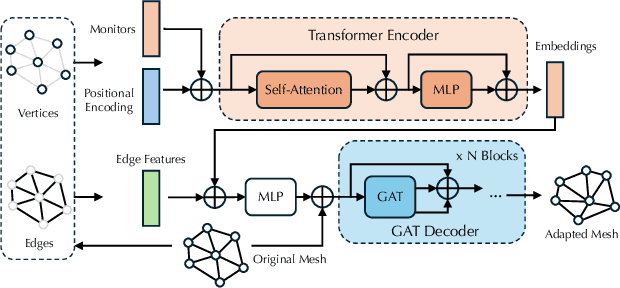



Solving complex Partial Differential Equations (PDEs) accurately and efficiently is an essential and challenging problem in all scientific and engineering disciplines. Mesh movement methods provide the capability to improve the accuracy of the numerical solution without increasing the overall mesh degree of freedom count. Conventional sophisticated mesh movement methods are extremely expensive and struggle to handle scenarios with complex boundary geometries. However, existing learning-based methods require re-training from scratch given a different PDE type or boundary geometry, which limits their applicability, and also often suffer from robustness issues in the form of inverted elements. In this paper, we introduce the Universal Mesh Movement Network (UM2N), which -- once trained -- can be applied in a non-intrusive, zero-shot manner to move meshes with different size distributions and structures, for solvers applicable to different PDE types and boundary geometries. UM2N consists of a Graph Transformer (GT) encoder for extracting features and a Graph Attention Network (GAT) based decoder for moving the mesh. We evaluate our method on advection and Navier-Stokes based examples, as well as a real-world tsunami simulation case. Our method outperforms existing learning-based mesh movement methods in terms of the benchmarks described above. In comparison to the conventional sophisticated Monge-Amp\`ere PDE-solver based method, our approach not only significantly accelerates mesh movement, but also proves effective in scenarios where the conventional method fails. Our project page is at https://erizmr.github.io/UM2N/.
Label Smoothing Improves Machine Unlearning
Jun 11, 2024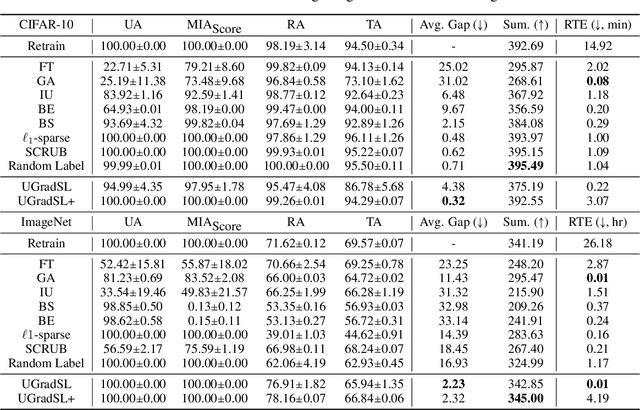
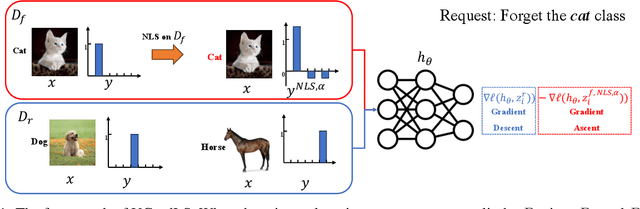
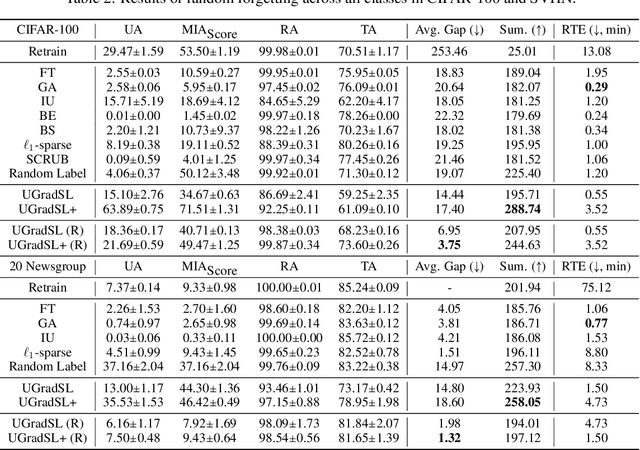
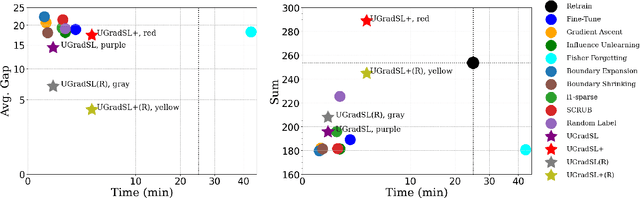
The objective of machine unlearning (MU) is to eliminate previously learned data from a model. However, it is challenging to strike a balance between computation cost and performance when using existing MU techniques. Taking inspiration from the influence of label smoothing on model confidence and differential privacy, we propose a simple gradient-based MU approach that uses an inverse process of label smoothing. This work introduces UGradSL, a simple, plug-and-play MU approach that uses smoothed labels. We provide theoretical analyses demonstrating why properly introducing label smoothing improves MU performance. We conducted extensive experiments on six datasets of various sizes and different modalities, demonstrating the effectiveness and robustness of our proposed method. The consistent improvement in MU performance is only at a marginal cost of additional computations. For instance, UGradSL improves over the gradient ascent MU baseline by 66% unlearning accuracy without sacrificing unlearning efficiency.
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
May 24, 2024
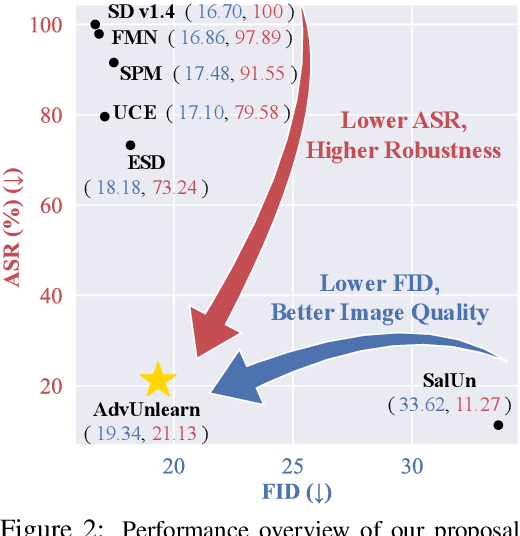
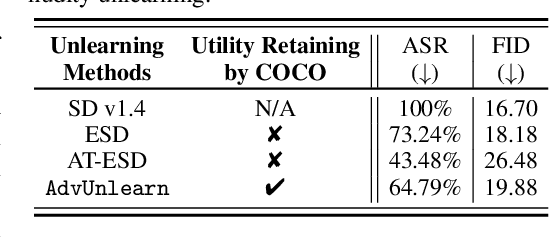

Diffusion models (DMs) have achieved remarkable success in text-to-image generation, but they also pose safety risks, such as the potential generation of harmful content and copyright violations. The techniques of machine unlearning, also known as concept erasing, have been developed to address these risks. However, these techniques remain vulnerable to adversarial prompt attacks, which can prompt DMs post-unlearning to regenerate undesired images containing concepts (such as nudity) meant to be erased. This work aims to enhance the robustness of concept erasing by integrating the principle of adversarial training (AT) into machine unlearning, resulting in the robust unlearning framework referred to as AdvUnlearn. However, achieving this effectively and efficiently is highly nontrivial. First, we find that a straightforward implementation of AT compromises DMs' image generation quality post-unlearning. To address this, we develop a utility-retaining regularization on an additional retain set, optimizing the trade-off between concept erasure robustness and model utility in AdvUnlearn. Moreover, we identify the text encoder as a more suitable module for robustification compared to UNet, ensuring unlearning effectiveness. And the acquired text encoder can serve as a plug-and-play robust unlearner for various DM types. Empirically, we perform extensive experiments to demonstrate the robustness advantage of AdvUnlearn across various DM unlearning scenarios, including the erasure of nudity, objects, and style concepts. In addition to robustness, AdvUnlearn also achieves a balanced tradeoff with model utility. To our knowledge, this is the first work to systematically explore robust DM unlearning through AT, setting it apart from existing methods that overlook robustness in concept erasing. Codes are available at: https://github.com/OPTML-Group/AdvUnlearn
SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning
Apr 28, 2024



Large Language Models (LLMs) have highlighted the necessity of effective unlearning mechanisms to comply with data regulations and ethical AI practices. LLM unlearning aims at removing undesired data influences and associated model capabilities without compromising utility out of the scope of unlearning. While interest in studying LLM unlearning is growing,the impact of the optimizer choice for LLM unlearning remains under-explored. In this work, we shed light on the significance of optimizer selection in LLM unlearning for the first time, establishing a clear connection between {second-order optimization} and influence unlearning (a classical approach using influence functions to update the model for data influence removal). This insight propels us to develop a second-order unlearning framework, termed SOUL, built upon the second-order clipped stochastic optimization (Sophia)-based LLM training method. SOUL extends the static, one-shot model update using influence unlearning to a dynamic, iterative unlearning process. Our extensive experiments show that SOUL consistently outperforms conventional first-order methods across various unlearning tasks, models, and metrics, suggesting the promise of second-order optimization in providing a scalable and easily implementable solution for LLM unlearning.
Challenging Forgets: Unveiling the Worst-Case Forget Sets in Machine Unlearning
Mar 12, 2024The trustworthy machine learning (ML) community is increasingly recognizing the crucial need for models capable of selectively 'unlearning' data points after training. This leads to the problem of machine unlearning (MU), aiming to eliminate the influence of chosen data points on model performance, while still maintaining the model's utility post-unlearning. Despite various MU methods for data influence erasure, evaluations have largely focused on random data forgetting, ignoring the vital inquiry into which subset should be chosen to truly gauge the authenticity of unlearning performance. To tackle this issue, we introduce a new evaluative angle for MU from an adversarial viewpoint. We propose identifying the data subset that presents the most significant challenge for influence erasure, i.e., pinpointing the worst-case forget set. Utilizing a bi-level optimization principle, we amplify unlearning challenges at the upper optimization level to emulate worst-case scenarios, while simultaneously engaging in standard training and unlearning at the lower level, achieving a balance between data influence erasure and model utility. Our proposal offers a worst-case evaluation of MU's resilience and effectiveness. Through extensive experiments across different datasets (including CIFAR-10, 100, CelebA, Tiny ImageNet, and ImageNet) and models (including both image classifiers and generative models), we expose critical pros and cons in existing (approximate) unlearning strategies. Our results illuminate the complex challenges of MU in practice, guiding the future development of more accurate and robust unlearning algorithms. The code is available at https://github.com/OPTML-Group/Unlearn-WorstCase.
UnlearnCanvas: A Stylized Image Dataset to Benchmark Machine Unlearning for Diffusion Models
Feb 26, 2024The rapid advancement of diffusion models (DMs) has not only transformed various real-world industries but has also introduced negative societal concerns, including the generation of harmful content, copyright disputes, and the rise of stereotypes and biases. To mitigate these issues, machine unlearning (MU) has emerged as a potential solution, demonstrating its ability to remove undesired generative capabilities of DMs in various applications. However, by examining existing MU evaluation methods, we uncover several key challenges that can result in incomplete, inaccurate, or biased evaluations for MU in DMs. To address them, we enhance the evaluation metrics for MU, including the introduction of an often-overlooked retainability measurement for DMs post-unlearning. Additionally, we introduce UnlearnCanvas, a comprehensive high-resolution stylized image dataset that facilitates us to evaluate the unlearning of artistic painting styles in conjunction with associated image objects. We show that this dataset plays a pivotal role in establishing a standardized and automated evaluation framework for MU techniques on DMs, featuring 7 quantitative metrics to address various aspects of unlearning effectiveness. Through extensive experiments, we benchmark 5 state-of-the-art MU methods, revealing novel insights into their pros and cons, and the underlying unlearning mechanisms. Furthermore, we demonstrate the potential of UnlearnCanvas to benchmark other generative modeling tasks, such as style transfer. The UnlearnCanvas dataset, benchmark, and the codes to reproduce all the results in this work can be found at https://github.com/OPTML-Group/UnlearnCanvas.