 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaskGen: A Task-Based, Memory-Infused Agentic Framework using StrictJSON
Jul 22, 2024TaskGen is an open-sourced agentic framework which uses an Agent to solve an arbitrary task by breaking them down into subtasks. Each subtask is mapped to an Equipped Function or another Agent to execute. In order to reduce verbosity (and hence token usage), TaskGen uses StrictJSON that ensures JSON output from the Large Language Model (LLM), along with additional features such as type checking and iterative error correction. Key to the philosophy of TaskGen is the management of information/memory on a need-to-know basis. We empirically evaluate TaskGen on various environments such as 40x40 dynamic maze navigation with changing obstacle locations (100% solve rate), TextWorld escape room solving with dense rewards and detailed goals (96% solve rate), web browsing (69% of actions successful), solving the MATH dataset (71% solve rate over 100 Level-5 problems), Retrieval Augmented Generation on NaturalQuestions dataset (F1 score of 47.03%)
SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning
Apr 28, 2024



Large Language Models (LLMs) have highlighted the necessity of effective unlearning mechanisms to comply with data regulations and ethical AI practices. LLM unlearning aims at removing undesired data influences and associated model capabilities without compromising utility out of the scope of unlearning. While interest in studying LLM unlearning is growing,the impact of the optimizer choice for LLM unlearning remains under-explored. In this work, we shed light on the significance of optimizer selection in LLM unlearning for the first time, establishing a clear connection between {second-order optimization} and influence unlearning (a classical approach using influence functions to update the model for data influence removal). This insight propels us to develop a second-order unlearning framework, termed SOUL, built upon the second-order clipped stochastic optimization (Sophia)-based LLM training method. SOUL extends the static, one-shot model update using influence unlearning to a dynamic, iterative unlearning process. Our extensive experiments show that SOUL consistently outperforms conventional first-order methods across various unlearning tasks, models, and metrics, suggesting the promise of second-order optimization in providing a scalable and easily implementable solution for LLM unlearning.
From PEFT to DEFT: Parameter Efficient Finetuning for Reducing Activation Density in Transformers
Feb 02, 2024Pretrained Language Models (PLMs) have become the de facto starting point for fine-tuning on downstream tasks. However, as model sizes continue to increase, traditional fine-tuning of all parameters becomes challenging. To address this, parameter-efficient fine-tuning (PEFT) methods have gained popularity as a means to adapt PLMs effectively. In parallel, recent studies have revealed the presence of activation sparsity within the intermediate outputs of the multilayer perception (MLP) blocks in transformers. Low activation density enables efficient model inference on sparsity-aware hardware. Building upon this insight, in this work, we propose a novel density loss that encourages higher activation sparsity (equivalently, lower activation density) in the pre-trained models. We demonstrate the effectiveness of our approach by utilizing mainstream PEFT techniques including QLoRA, LoRA, Adapter, Prompt/Prefix Tuning to facilitate efficient model adaptation across diverse downstream tasks. Experiments show that our proposed method DEFT, Density-Efficient Fine-Tuning, can reduce the activation density consistently and up to $\boldsymbol{50.72\%}$ on RoBERTa$_\mathrm{Large}$, and $\boldsymbol {53.19\%}$ (encoder density) and $\boldsymbol{90.60\%}$ (decoder density) on Flan-T5$_\mathrm{XXL}$ ($\boldsymbol{11B}$) compared to PEFT using GLUE and QA (SQuAD) benchmarks respectively while maintaining competitive performance on downstream tasks. We also showcase that DEFT works complementary with quantized and pruned models
Reprogramming under constraints: Revisiting efficient and reliable transferability of lottery tickets
Aug 29, 2023In the era of foundation models with huge pre-training budgets, the downstream tasks have been shifted to the narrative of efficient and fast adaptation. For classification-based tasks in the domain of computer vision, the two most efficient approaches have been linear probing (LP) and visual prompting/reprogramming (VP); the former aims to learn a classifier in the form of a linear head on the features extracted by the pre-trained model, while the latter maps the input data to the domain of the source data on which the model was originally pre-trained on. Although extensive studies have demonstrated the differences between LP and VP in terms of downstream performance, we explore the capabilities of the two aforementioned methods via the sparsity axis: (a) Data sparsity: the impact of few-shot adaptation and (b) Model sparsity: the impact of lottery tickets (LT). We demonstrate that LT are not universal reprogrammers, i.e., for certain target datasets, reprogramming an LT yields significantly lower performance than the reprogrammed dense model although their corresponding upstream performance is similar. Further, we demonstrate that the calibration of dense models is always superior to that of their lottery ticket counterparts under both LP and VP regimes. Our empirical study opens a new avenue of research into VP for sparse models and encourages further understanding of the performance beyond the accuracy achieved by VP under constraints of sparsity. Code and logs can be accessed at \url{https://github.com/landskape-ai/Reprogram_LT}.
Robust Graph Neural Networks using Weighted Graph Laplacian
Aug 03, 2022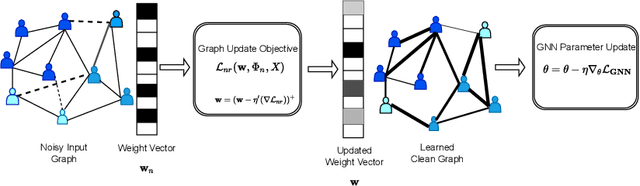

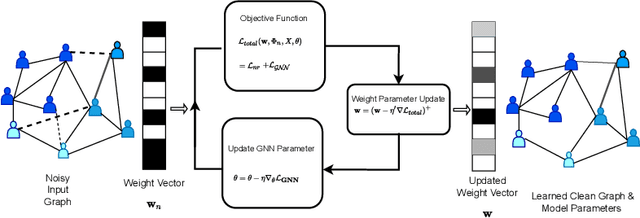
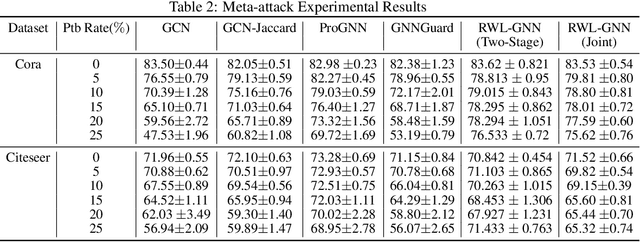
Graph neural network (GNN) is achieving remarkable performances in a variety of application domains. However, GNN is vulnerable to noise and adversarial attacks in input data. Making GNN robust against noises and adversarial attacks is an important problem. The existing defense methods for GNNs are computationally demanding and are not scalable. In this paper, we propose a generic framework for robustifying GNN known as Weighted Laplacian GNN (RWL-GNN). The method combines Weighted Graph Laplacian learning with the GNN implementation. The proposed method benefits from the positive semi-definiteness property of Laplacian matrix, feature smoothness, and latent features via formulating a unified optimization framework, which ensures the adversarial/noisy edges are discarded and connections in the graph are appropriately weighted. For demonstration, the experiments are conducted with Graph convolutional neural network(GCNN) architecture, however, the proposed framework is easily amenable to any existing GNN architecture. The simulation results with benchmark dataset establish the efficacy of the proposed method, both in accuracy and computational efficiency. Code can be accessed at https://github.com/Bharat-Runwal/RWL-GNN.
APP: Anytime Progressive Pruning
Apr 04, 2022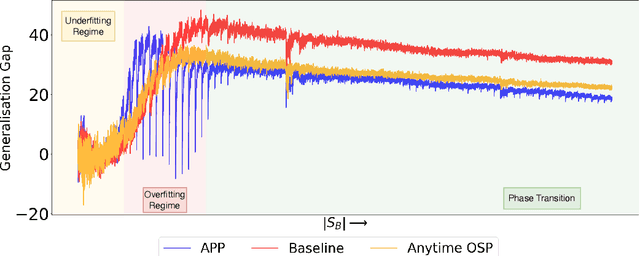

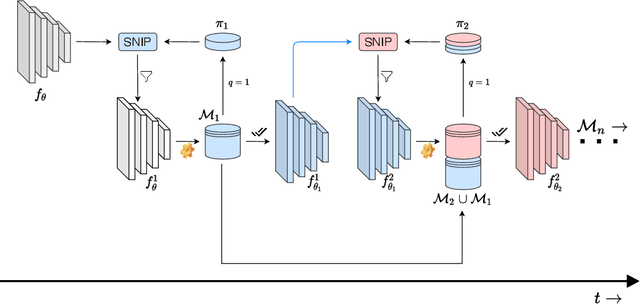

With the latest advances in deep learning, there has been a lot of focus on the online learning paradigm due to its relevance in practical settings. Although many methods have been investigated for optimal learning settings in scenarios where the data stream is continuous over time, sparse networks training in such settings have often been overlooked. In this paper, we explore the problem of training a neural network with a target sparsity in a particular case of online learning: the anytime learning at macroscale paradigm (ALMA). We propose a novel way of progressive pruning, referred to as \textit{Anytime Progressive Pruning} (APP); the proposed approach significantly outperforms the baseline dense and Anytime OSP models across multiple architectures and datasets under short, moderate, and long-sequence training. Our method, for example, shows an improvement in accuracy of $\approx 7\%$ and a reduction in the generalization gap by $\approx 22\%$, while being $\approx 1/3$ rd the size of the dense baseline model in few-shot restricted imagenet training. We further observe interesting nonmonotonic transitions in the generalization gap in the high number of megabatches-based ALMA. The code and experiment dashboards can be accessed at \url{https://github.com/landskape-ai/Progressive-Pruning} and \url{https://wandb.ai/landskape/APP}, respectively.