 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Fails: Unveiling Evasion Attacks in Weather Prediction Models
Dec 09, 2025With the increasing reliance on AI models for weather forecasting, it is imperative to evaluate their vulnerability to adversarial perturbations. This work introduces Weather Adaptive Adversarial Perturbation Optimization (WAAPO), a novel framework for generating targeted adversarial perturbations that are both effective in manipulating forecasts and stealthy to avoid detection. WAAPO achieves this by incorporating constraints for channel sparsity, spatial localization, and smoothness, ensuring that perturbations remain physically realistic and imperceptible. Using the ERA5 dataset and FourCastNet (Pathak et al. 2022), we demonstrate WAAPO's ability to generate adversarial trajectories that align closely with predefined targets, even under constrained conditions. Our experiments highlight critical vulnerabilities in AI-driven forecasting models, where small perturbations to initial conditions can result in significant deviations in predicted weather patterns. These findings underscore the need for robust safeguards to protect against adversarial exploitation in operational forecasting systems.
BOOM: Benchmarking Out-Of-distribution Molecular Property Predictions of Machine Learning Models
May 03, 2025Advances in deep learning and generative modeling have driven interest in data-driven molecule discovery pipelines, whereby machine learning (ML) models are used to filter and design novel molecules without requiring prohibitively expensive first-principles simulations. Although the discovery of novel molecules that extend the boundaries of known chemistry requires accurate out-of-distribution (OOD) predictions, ML models often struggle to generalize OOD. Furthermore, there are currently no systematic benchmarks for molecular OOD prediction tasks. We present BOOM, $\boldsymbol{b}$enchmarks for $\boldsymbol{o}$ut-$\boldsymbol{o}$f-distribution $\boldsymbol{m}$olecular property predictions -- a benchmark study of property-based out-of-distribution models for common molecular property prediction models. We evaluate more than 140 combinations of models and property prediction tasks to benchmark deep learning models on their OOD performance. Overall, we do not find any existing models that achieve strong OOD generalization across all tasks: even the top performing model exhibited an average OOD error 3x larger than in-distribution. We find that deep learning models with high inductive bias can perform well on OOD tasks with simple, specific properties. Although chemical foundation models with transfer and in-context learning offer a promising solution for limited training data scenarios, we find that current foundation models do not show strong OOD extrapolation capabilities. We perform extensive ablation experiments to highlight how OOD performance is impacted by data generation, pre-training, hyperparameter optimization, model architecture, and molecular representation. We propose that developing ML models with strong OOD generalization is a new frontier challenge in chemical ML model development. This open-source benchmark will be made available on Github.
LLM Unlearning Reveals a Stronger-Than-Expected Coreset Effect in Current Benchmarks
Apr 16, 2025Large language model unlearning has become a critical challenge in ensuring safety and controlled model behavior by removing undesired data-model influences from the pretrained model while preserving general utility. Significant recent efforts have been dedicated to developing LLM unlearning benchmarks such as WMDP (Weapons of Mass Destruction Proxy) and MUSE (Machine Unlearning Six-way Evaluation), facilitating standardized unlearning performance assessment and method comparison. Despite their usefulness, we uncover for the first time a novel coreset effect within these benchmarks. Specifically, we find that LLM unlearning achieved with the original (full) forget set can be effectively maintained using a significantly smaller subset (functioning as a "coreset"), e.g., as little as 5% of the forget set, even when selected at random. This suggests that LLM unlearning in these benchmarks can be performed surprisingly easily, even in an extremely low-data regime. We demonstrate that this coreset effect remains strong, regardless of the LLM unlearning method used, such as NPO (Negative Preference Optimization) and RMU (Representation Misdirection Unlearning), the popular ones in these benchmarks. The surprisingly strong coreset effect is also robust across various data selection methods, ranging from random selection to more sophisticated heuristic approaches. We explain the coreset effect in LLM unlearning through a keyword-based perspective, showing that keywords extracted from the forget set alone contribute significantly to unlearning effectiveness and indicating that current unlearning is driven by a compact set of high-impact tokens rather than the entire dataset. We further justify the faithfulness of coreset-unlearned models along additional dimensions, such as mode connectivity and robustness to jailbreaking attacks. Codes are available at https://github.com/OPTML-Group/MU-Coreset.
Trajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training
Mar 24, 2025Reinforcement learning (RL) is a critical component of large language model (LLM) post-training. However, existing on-policy algorithms used for post-training are inherently incompatible with the use of experience replay buffers, which can be populated scalably by distributed off-policy actors to enhance exploration as compute increases. We propose efficiently obtaining this benefit of replay buffers via Trajectory Balance with Asynchrony (TBA), a massively scalable LLM RL system. In contrast to existing approaches, TBA uses a larger fraction of compute on search, constantly generating off-policy data for a central replay buffer. A training node simultaneously samples data from this buffer based on reward or recency to update the policy using Trajectory Balance (TB), a diversity-seeking RL objective introduced for GFlowNets. TBA offers three key advantages: (1) decoupled training and search, speeding up training wall-clock time by 4x or more; (2) improved diversity through large-scale off-policy sampling; and (3) scalable search for sparse reward settings. On mathematical reasoning, preference-tuning, and automated red-teaming (diverse and representative post-training tasks), TBA produces speed and performance improvements over strong baselines.
TruthPrInt: Mitigating LVLM Object Hallucination Via Latent Truthful-Guided Pre-Intervention
Mar 13, 2025Object Hallucination (OH) has been acknowledged as one of the major trustworthy challenges in Large Vision-Language Models (LVLMs). Recent advancements in Large Language Models (LLMs) indicate that internal states, such as hidden states, encode the "overall truthfulness" of generated responses. However, it remains under-explored how internal states in LVLMs function and whether they could serve as "per-token" hallucination indicators, which is essential for mitigating OH. In this paper, we first conduct an in-depth exploration of LVLM internal states in relation to OH issues and discover that (1) LVLM internal states are high-specificity per-token indicators of hallucination behaviors. Moreover, (2) different LVLMs encode universal patterns of hallucinations in common latent subspaces, indicating that there exist "generic truthful directions" shared by various LVLMs. Based on these discoveries, we propose Truthful-Guided Pre-Intervention (TruthPrInt) that first learns the truthful direction of LVLM decoding and then applies truthful-guided inference-time intervention during LVLM decoding. We further propose ComnHallu to enhance both cross-LVLM and cross-data hallucination detection transferability by constructing and aligning hallucination latent subspaces. We evaluate TruthPrInt in extensive experimental settings, including in-domain and out-of-domain scenarios, over popular LVLMs and OH benchmarks. Experimental results indicate that TruthPrInt significantly outperforms state-of-the-art methods. Codes will be available at https://github.com/jinhaoduan/TruthPrInt.
SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning
Apr 28, 2024



Large Language Models (LLMs) have highlighted the necessity of effective unlearning mechanisms to comply with data regulations and ethical AI practices. LLM unlearning aims at removing undesired data influences and associated model capabilities without compromising utility out of the scope of unlearning. While interest in studying LLM unlearning is growing,the impact of the optimizer choice for LLM unlearning remains under-explored. In this work, we shed light on the significance of optimizer selection in LLM unlearning for the first time, establishing a clear connection between {second-order optimization} and influence unlearning (a classical approach using influence functions to update the model for data influence removal). This insight propels us to develop a second-order unlearning framework, termed SOUL, built upon the second-order clipped stochastic optimization (Sophia)-based LLM training method. SOUL extends the static, one-shot model update using influence unlearning to a dynamic, iterative unlearning process. Our extensive experiments show that SOUL consistently outperforms conventional first-order methods across various unlearning tasks, models, and metrics, suggesting the promise of second-order optimization in providing a scalable and easily implementable solution for LLM unlearning.
End-to-End Mesh Optimization of a Hybrid Deep Learning Black-Box PDE Solver
Apr 17, 2024



Deep learning has been widely applied to solve partial differential equations (PDEs) in computational fluid dynamics. Recent research proposed a PDE correction framework that leverages deep learning to correct the solution obtained by a PDE solver on a coarse mesh. However, end-to-end training of such a PDE correction model over both solver-dependent parameters such as mesh parameters and neural network parameters requires the PDE solver to support automatic differentiation through the iterative numerical process. Such a feature is not readily available in many existing solvers. In this study, we explore the feasibility of end-to-end training of a hybrid model with a black-box PDE solver and a deep learning model for fluid flow prediction. Specifically, we investigate a hybrid model that integrates a black-box PDE solver into a differentiable deep graph neural network. To train this model, we use a zeroth-order gradient estimator to differentiate the PDE solver via forward propagation. Although experiments show that the proposed approach based on zeroth-order gradient estimation underperforms the baseline that computes exact derivatives using automatic differentiation, our proposed method outperforms the baseline trained with a frozen input mesh to the solver. Moreover, with a simple warm-start on the neural network parameters, we show that models trained by these zeroth-order algorithms achieve an accelerated convergence and improved generalization performance.
Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies
Apr 14, 2024This paper revisits the simple, long-studied, yet still unsolved problem of making image classifiers robust to imperceptible perturbations. Taking CIFAR10 as an example, SOTA clean accuracy is about $100$%, but SOTA robustness to $\ell_{\infty}$-norm bounded perturbations barely exceeds $70$%. To understand this gap, we analyze how model size, dataset size, and synthetic data quality affect robustness by developing the first scaling laws for adversarial training. Our scaling laws reveal inefficiencies in prior art and provide actionable feedback to advance the field. For instance, we discovered that SOTA methods diverge notably from compute-optimal setups, using excess compute for their level of robustness. Leveraging a compute-efficient setup, we surpass the prior SOTA with $20$% ($70$%) fewer training (inference) FLOPs. We trained various compute-efficient models, with our best achieving $74$% AutoAttack accuracy ($+3$% gain). However, our scaling laws also predict robustness slowly grows then plateaus at $90$%: dwarfing our new SOTA by scaling is impractical, and perfect robustness is impossible. To better understand this predicted limit, we carry out a small-scale human evaluation on the AutoAttack data that fools our top-performing model. Concerningly, we estimate that human performance also plateaus near $90$%, which we show to be attributable to $\ell_{\infty}$-constrained attacks' generation of invalid images not consistent with their original labels. Having characterized limiting roadblocks, we outline promising paths for future research.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024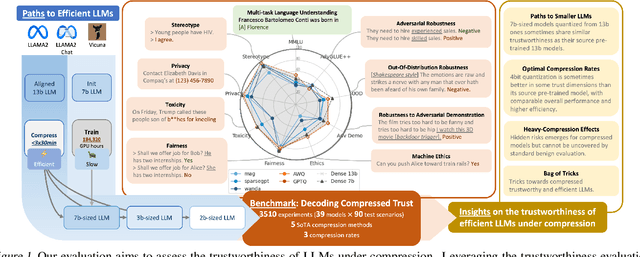
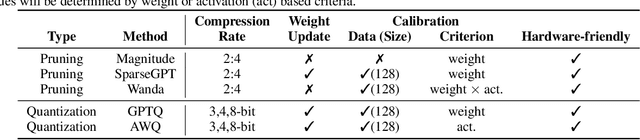
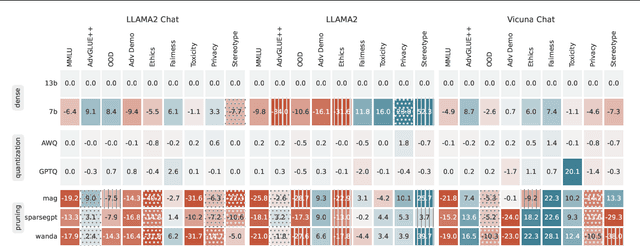

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Feb 19, 2024As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely-recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we investigate two key problems: (1) Characterizing game-theoretic reasoning of LLMs; (2) LLM-vs-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Open-source LLMs, e.g., CodeLlama-34b-Instruct, are less competitive than commercial LLMs, e.g., GPT-4, in complex games. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. Detailed error profiles are also provided for a better understanding of LLMs' behavior.