 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeak@$k$: Unlearning Does Not Make LLMs Forget Under Probabilistic Decoding
Nov 07, 2025Unlearning in large language models (LLMs) is critical for regulatory compliance and for building ethical generative AI systems that avoid producing private, toxic, illegal, or copyrighted content. Despite rapid progress, in this work we show that \textit{almost all} existing unlearning methods fail to achieve true forgetting in practice. Specifically, while evaluations of these `unlearned' models under deterministic (greedy) decoding often suggest successful knowledge removal using standard benchmarks (as has been done in the literature), we show that sensitive information reliably resurfaces when models are sampled with standard probabilistic decoding. To rigorously capture this vulnerability, we introduce \texttt{leak@$k$}, a new meta-evaluation metric that quantifies the likelihood of forgotten knowledge reappearing when generating $k$ samples from the model under realistic decoding strategies. Using three widely adopted benchmarks, TOFU, MUSE, and WMDP, we conduct the first large-scale, systematic study of unlearning reliability using our newly defined \texttt{leak@$k$} metric. Our findings demonstrate that knowledge leakage persists across methods and tasks, underscoring that current state-of-the-art unlearning techniques provide only limited forgetting and highlighting the urgent need for more robust approaches to LLM unlearning.
LLM Unlearning Reveals a Stronger-Than-Expected Coreset Effect in Current Benchmarks
Apr 16, 2025Large language model unlearning has become a critical challenge in ensuring safety and controlled model behavior by removing undesired data-model influences from the pretrained model while preserving general utility. Significant recent efforts have been dedicated to developing LLM unlearning benchmarks such as WMDP (Weapons of Mass Destruction Proxy) and MUSE (Machine Unlearning Six-way Evaluation), facilitating standardized unlearning performance assessment and method comparison. Despite their usefulness, we uncover for the first time a novel coreset effect within these benchmarks. Specifically, we find that LLM unlearning achieved with the original (full) forget set can be effectively maintained using a significantly smaller subset (functioning as a "coreset"), e.g., as little as 5% of the forget set, even when selected at random. This suggests that LLM unlearning in these benchmarks can be performed surprisingly easily, even in an extremely low-data regime. We demonstrate that this coreset effect remains strong, regardless of the LLM unlearning method used, such as NPO (Negative Preference Optimization) and RMU (Representation Misdirection Unlearning), the popular ones in these benchmarks. The surprisingly strong coreset effect is also robust across various data selection methods, ranging from random selection to more sophisticated heuristic approaches. We explain the coreset effect in LLM unlearning through a keyword-based perspective, showing that keywords extracted from the forget set alone contribute significantly to unlearning effectiveness and indicating that current unlearning is driven by a compact set of high-impact tokens rather than the entire dataset. We further justify the faithfulness of coreset-unlearned models along additional dimensions, such as mode connectivity and robustness to jailbreaking attacks. Codes are available at https://github.com/OPTML-Group/MU-Coreset.
Backdoor Secrets Unveiled: Identifying Backdoor Data with Optimized Scaled Prediction Consistency
Mar 15, 2024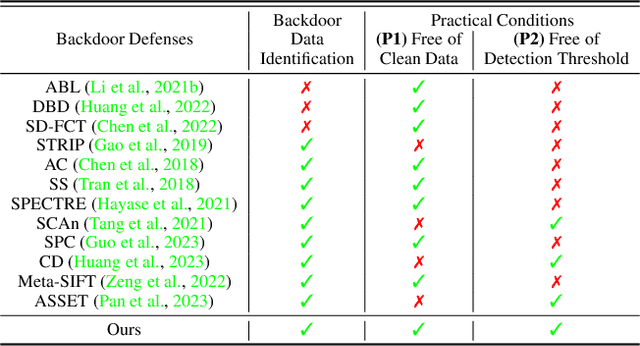


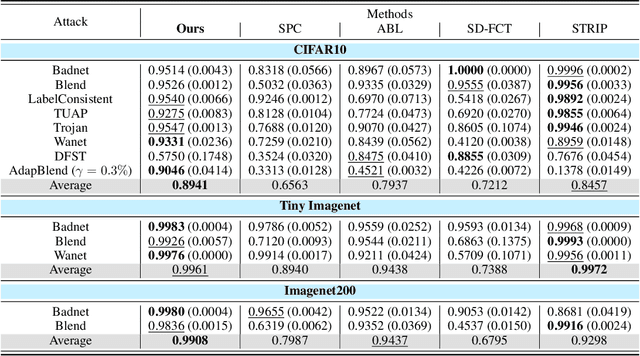
Modern machine learning (ML) systems demand substantial training data, often resorting to external sources. Nevertheless, this practice renders them vulnerable to backdoor poisoning attacks. Prior backdoor defense strategies have primarily focused on the identification of backdoored models or poisoned data characteristics, typically operating under the assumption of access to clean data. In this work, we delve into a relatively underexplored challenge: the automatic identification of backdoor data within a poisoned dataset, all under realistic conditions, i.e., without the need for additional clean data or without manually defining a threshold for backdoor detection. We draw an inspiration from the scaled prediction consistency (SPC) technique, which exploits the prediction invariance of poisoned data to an input scaling factor. Based on this, we pose the backdoor data identification problem as a hierarchical data splitting optimization problem, leveraging a novel SPC-based loss function as the primary optimization objective. Our innovation unfolds in several key aspects. First, we revisit the vanilla SPC method, unveiling its limitations in addressing the proposed backdoor identification problem. Subsequently, we develop a bi-level optimization-based approach to precisely identify backdoor data by minimizing the advanced SPC loss. Finally, we demonstrate the efficacy of our proposal against a spectrum of backdoor attacks, encompassing basic label-corrupted attacks as well as more sophisticated clean-label attacks, evaluated across various benchmark datasets. Experiment results show that our approach often surpasses the performance of current baselines in identifying backdoor data points, resulting in about 4%-36% improvement in average AUROC. Codes are available at https://github.com/OPTML-Group/BackdoorMSPC.
Towards Understanding How Self-training Tolerates Data Backdoor Poisoning
Jan 20, 2023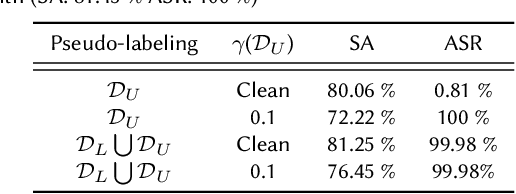



Recent studies on backdoor attacks in model training have shown that polluting a small portion of training data is sufficient to produce incorrect manipulated predictions on poisoned test-time data while maintaining high clean accuracy in downstream tasks. The stealthiness of backdoor attacks has imposed tremendous defense challenges in today's machine learning paradigm. In this paper, we explore the potential of self-training via additional unlabeled data for mitigating backdoor attacks. We begin by making a pilot study to show that vanilla self-training is not effective in backdoor mitigation. Spurred by that, we propose to defend the backdoor attacks by leveraging strong but proper data augmentations in the self-training pseudo-labeling stage. We find that the new self-training regime help in defending against backdoor attacks to a great extent. Its effectiveness is demonstrated through experiments for different backdoor triggers on CIFAR-10 and a combination of CIFAR-10 with an additional unlabeled 500K TinyImages dataset. Finally, we explore the direction of combining self-supervised representation learning with self-training for further improvement in backdoor defense.
Towards Positive Jacobian: Learn to Postprocess Diffeomorphic Image Registration with Matrix Exponential
Feb 01, 2022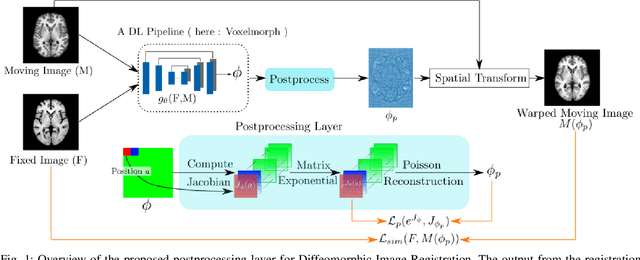



We present a postprocessing layer for deformable image registration to make a registration field more diffeomorphic by encouraging Jacobians of the transformation to be positive. Diffeomorphic image registration is important for medical imaging studies because of the properties like invertibility, smoothness of the transformation, and topology preservation/non-folding of the grid. Violation of these properties can lead to destruction of the neighbourhood and the connectivity of anatomical structures during image registration. Most of the recent deep learning methods do not explicitly address this folding problem and try to solve it with a smoothness regularization on the registration field. In this paper, we propose a differentiable layer, which takes any registration field as its input, computes exponential of the Jacobian matrices of the input and reconstructs a new registration field from the exponentiated Jacobian matrices using Poisson reconstruction. Our proposed Poisson reconstruction loss enforces positive Jacobians for the final registration field. Thus, our method acts as a post-processing layer without any learnable parameters of its own and can be placed at the end of any deep learning pipeline to form an end-to-end learnable framework. We show the effectiveness of our proposed method for a popular deep learning registration method Voxelmorph and evaluate it with a dataset containing 3D brain MRI scans. Our results show that our post-processing can effectively decrease the number of non-positive Jacobians by a significant amount without any noticeable deterioration of the registration accuracy, thus making the registration field more diffeomorphic. Our code is available online at https://github.com/Soumyadeep-Pal/Diffeomorphic-Image-Registration-Postprocess.
Speaker Recognition in Bengali Language from Nonlinear Features
Apr 15, 2020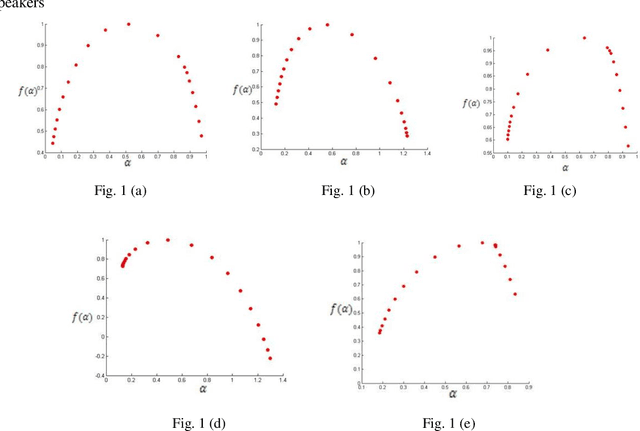

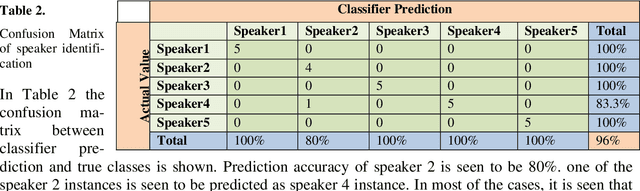
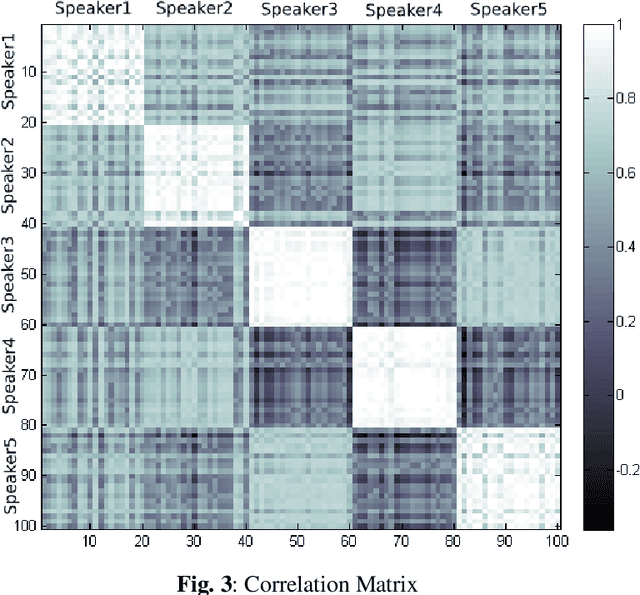
At present Automatic Speaker Recognition system is a very important issue due to its diverse applications. Hence, it becomes absolutely necessary to obtain models that take into consideration the speaking style of a person, vocal tract information, timbral qualities of his voice and other congenital information regarding his voice. The study of Bengali speech recognition and speaker identification is scarce in the literature. Hence the need arises for involving Bengali subjects in modelling our speaker identification engine. In this work, we have extracted some acoustic features of speech using non linear multifractal analysis. The Multifractal Detrended Fluctuation Analysis reveals essentially the complexity associated with the speech signals taken. The source characteristics have been quantified with the help of different techniques like Correlation Matrix, skewness of MFDFA spectrum etc. The Results obtained from this study gives a good recognition rate for Bengali Speakers.