 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Disentanglement of Disease Effects from Aging in 3D Medical Shapes
Mar 16, 2026Disentangling pathological changes from physiological aging in 3D medical shapes is crucial for developing interpretable biomarkers and patient stratification. However, this separation is challenging when diagnosis labels are limited or unavailable, since disease and aging often produce overlapping effects on shape changes, obscuring clinically relevant shape patterns. To address this challenge, we propose a two-stage framework combining unsupervised disease discovery with self-supervised disentanglement of implicit shape representations. In the first stage, we train an implicit neural model with signed distance functions to learn stable shape embeddings. We then apply clustering on the shape latent space, which yields pseudo disease labels without using ground-truth diagnosis during discovery. In the second stage, we disentangle factors in a compact variational space using pseudo disease labels discovered in the first stage and the ground truth age labels available for all subjects. We enforce separation and controllability with a multi-objective disentanglement loss combining covariance and a supervised contrastive loss. On ADNI hippocampus and OAI distal femur shapes, we achieve near-supervised performance, improving disentanglement and reconstruction over state-of-the-art unsupervised baselines, while enabling high-fidelity reconstruction, controllable synthesis, and factor-based explainability. Code and checkpoints are available at https://github.com/anonymous-submission01/medical-shape-disentanglement
Tokenizing Semantic Segmentation with RLE
Feb 25, 2026This paper presents a new unified approach to semantic segmentation in both images and videos by using language modeling to output the masks as sequences of discrete tokens. We use run length encoding (RLE) to discretize the segmentation masks and then train a modified version of Pix2Seq \cite{p2s} to output these RLE tokens through autoregression. We propose novel tokenization strategies to compress the length of the token sequence to make it practicable to extend this approach to videos. We also show how instance information can be incorporated into the tokenization process to perform panoptic segmentation. We evaluate our proposed models on two datasets to show that they are competitive with the state of the art in spite of being bottlenecked by our limited computational resources.
Learning Instance-Specific Parameters of Black-Box Models Using Differentiable Surrogates
Jul 23, 2024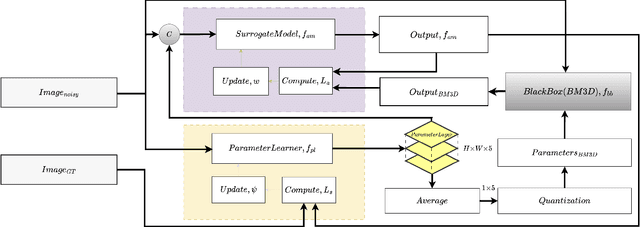
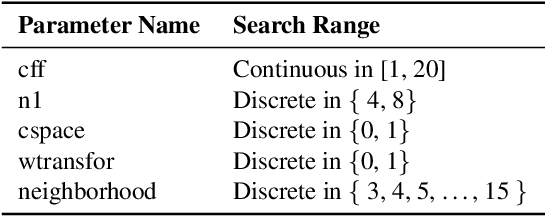
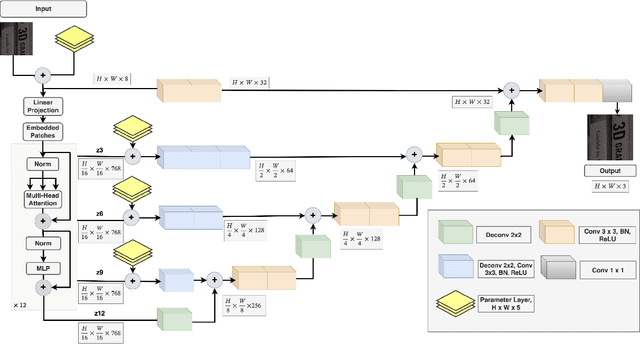

Tuning parameters of a non-differentiable or black-box compute is challenging. Existing methods rely mostly on random sampling or grid sampling from the parameter space. Further, with all the current methods, it is not possible to supply any input specific parameters to the black-box. To the best of our knowledge, for the first time, we are able to learn input-specific parameters for a black box in this work. As a test application we choose a popular image denoising method BM3D as our black-box compute. Then, we use a differentiable surrogate model (a neural network) to approximate the black-box behaviour. Next, another neural network is used in an end-to-end fashion to learn input instance-specific parameters for the black-box. Drawing inspiration from the work of Tseng et al. [1] , we applied our method to the Smartphone Image Denoising Dataset (SIDD) for image denoising. The results are compelling, demonstrating a significant increase in PSNR and a notable improvement in SSIM nearing 0.93. Experimental results underscore the effectiveness of our approach in achieving substantial improvements in both model performance and optimization efficiency. For code and implementation details, please refer to our GitHub repository. [1] Ethan Tseng, Felix Yu, Yuting Yang, Fahim Mannan, Karl St. Arnaud, Derek Nowrouzezahrai, Jean-Francois Lalonde, and Felix Heide. Hyperparameter optimization in black-box image processing using differentiable proxies. ACM Transactions on Graphics (TOG), 38(4), 7 2019.
Learning Diffeomorphism for Image Registration with Time-Continuous Networks using Semigroup Regularization
May 29, 2024



Diffeomorphic image registration (DIR) is a critical task in 3D medical image analysis, aimed at finding topology preserving deformations between pairs of images. Focusing on the solution of the flow map differential equation as the diffeomorphic deformation, recent methods use discrete timesteps along with various regularization terms to penalize the negative determinant of Jacobian and impose smoothness of the solution vector field. In this paper, we propose a novel learning-based approach for diffeomorphic 3D-image registration which finds the diffeomorphisms in the time continuum with fewer regularization terms and no additional integration. As one of the fundamental properties of flow maps, we exploit the semigroup property as the only form of regularization, ensuring temporally continuous diffeomorphic flows between pairs of images. Leveraging this property, our method alleviates the need for additional regularization terms and scaling and squaring integration during both training and evaluation. To achieve time-continuous diffeomorphisms, we employ time-embedded UNets, a technique commonly utilized in diffusion models. The proposed method reveals that ensuring diffeomorphism in a continuous time interval leads to better registration results. Experimental results on two public datasets (OASIS and CANDI) demonstrate the superiority of our model over both learning-based and optimization-based methods.
Disentangling Hippocampal Shape Variations: A Study of Neurological Disorders Using Graph Variational Autoencoder with Contrastive Learning
Mar 31, 2024
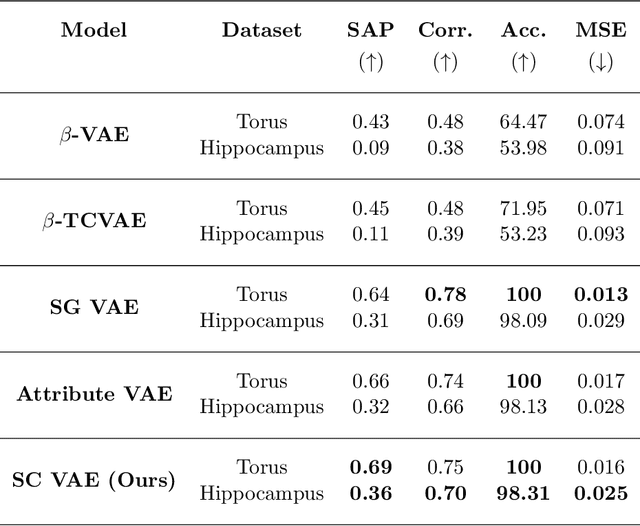
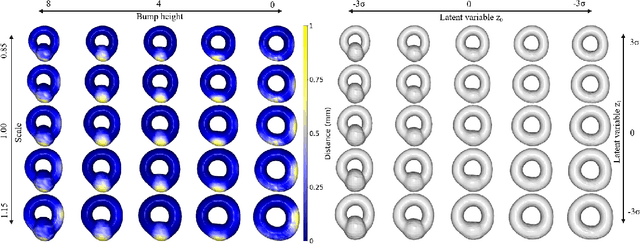
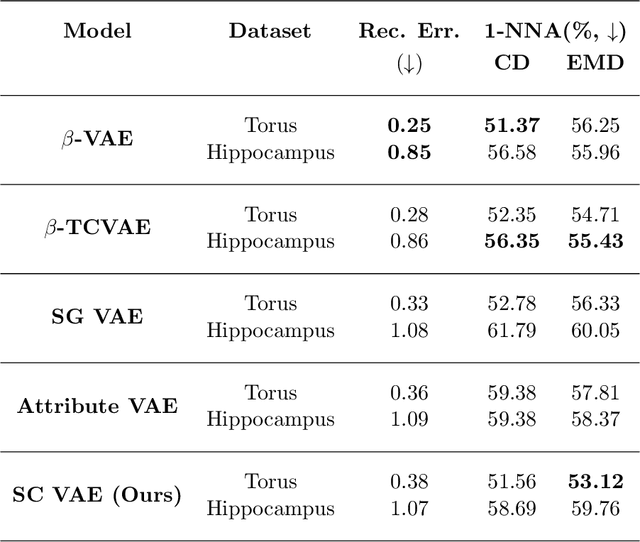
This paper presents a comprehensive study focused on disentangling hippocampal shape variations from diffusion tensor imaging (DTI) datasets within the context of neurological disorders. Leveraging a Graph Variational Autoencoder (VAE) enhanced with Supervised Contrastive Learning, our approach aims to improve interpretability by disentangling two distinct latent variables corresponding to age and the presence of diseases. In our ablation study, we investigate a range of VAE architectures and contrastive loss functions, showcasing the enhanced disentanglement capabilities of our approach. This evaluation uses synthetic 3D torus mesh data and real 3D hippocampal mesh datasets derived from the DTI hippocampal dataset. Our supervised disentanglement model outperforms several state-of-the-art (SOTA) methods like attribute and guided VAEs in terms of disentanglement scores. Our model distinguishes between age groups and disease status in patients with Multiple Sclerosis (MS) using the hippocampus data. Our Graph VAE with Supervised Contrastive Learning shows the volume changes of the hippocampus of MS populations at different ages, and the result is consistent with the current neuroimaging literature. This research provides valuable insights into the relationship between neurological disorder and hippocampal shape changes in different age groups of MS populations using a Graph VAE with Supervised Contrastive loss.
ShadowSense: Unsupervised Domain Adaptation and Feature Fusion for Shadow-Agnostic Tree Crown Detection from RGB-Thermal Drone Imagery
Oct 24, 2023Accurate detection of individual tree crowns from remote sensing data poses a significant challenge due to the dense nature of forest canopy and the presence of diverse environmental variations, e.g., overlapping canopies, occlusions, and varying lighting conditions. Additionally, the lack of data for training robust models adds another limitation in effectively studying complex forest conditions. This paper presents a novel method for detecting shadowed tree crowns and provides a challenging dataset comprising roughly 50k paired RGB-thermal images to facilitate future research for illumination-invariant detection. The proposed method (ShadowSense) is entirely self-supervised, leveraging domain adversarial training without source domain annotations for feature extraction and foreground feature alignment for feature pyramid networks to adapt domain-invariant representations by focusing on visible foreground regions, respectively. It then fuses complementary information of both modalities to effectively improve upon the predictions of an RGB-trained detector and boost the overall accuracy. Extensive experiments demonstrate the superiority of the proposed method over both the baseline RGB-trained detector and state-of-the-art techniques that rely on unsupervised domain adaptation or early image fusion. Our code and data are available: https://github.com/rudrakshkapil/ShadowSense
Predicting Ki67, ER, PR, and HER2 Statuses from H&E-stained Breast Cancer Images
Aug 03, 2023



Despite the advances in machine learning and digital pathology, it is not yet clear if machine learning methods can accurately predict molecular information merely from histomorphology. In a quest to answer this question, we built a large-scale dataset (185538 images) with reliable measurements for Ki67, ER, PR, and HER2 statuses. The dataset is composed of mirrored images of H\&E and corresponding images of immunohistochemistry (IHC) assays (Ki67, ER, PR, and HER2. These images are mirrored through registration. To increase reliability, individual pairs were inspected and discarded if artifacts were present (tissue folding, bubbles, etc). Measurements for Ki67, ER and PR were determined by calculating H-Score from image analysis. HER2 measurement is based on binary classification: 0 and 1+ (IHC scores representing a negative subset) vs 3+ (IHC score positive subset). Cases with IHC equivocal score (2+) were excluded. We show that a standard ViT-based pipeline can achieve prediction performances around 90% in terms of Area Under the Curve (AUC) when trained with a proper labeling protocol. Finally, we shed light on the ability of the trained classifiers to localize relevant regions, which encourages future work to improve the localizations. Our proposed dataset is publicly available: https://ihc4bc.github.io/
TMR-RD: Training-based Model Refinement and Representation Disagreement for Semi-Supervised Object Detection
Jul 25, 2023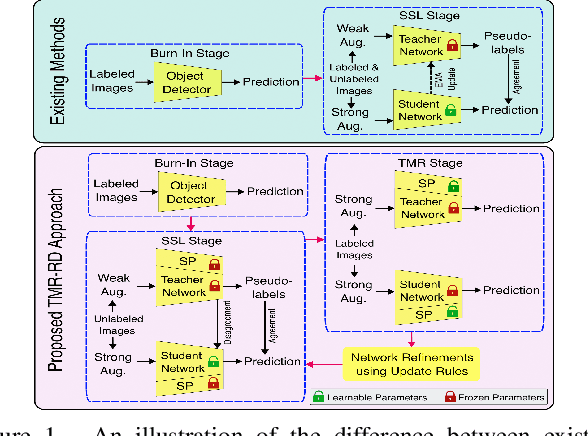
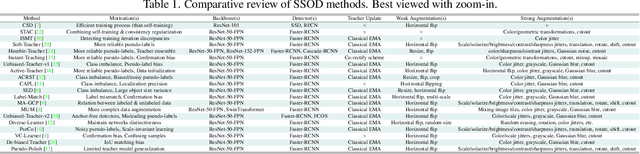
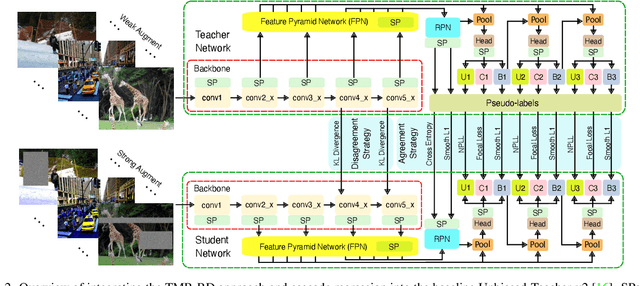
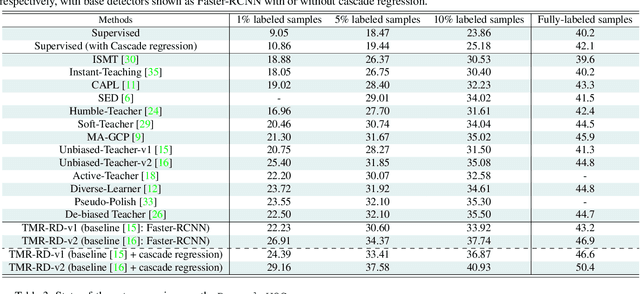
Semi-supervised object detection (SSOD) can incorporate limited labeled data and large amounts of unlabeled data to improve the performance and generalization of existing object detectors. Despite many advances, recent SSOD methods are still challenged by noisy/misleading pseudo-labels, classical exponential moving average (EMA) strategy, and the consensus of Teacher-Student models in the latter stages of training. This paper proposes a novel training-based model refinement (TMR) stage and a simple yet effective representation disagreement (RD) strategy to address the limitations of classical EMA and the consensus problem. The TMR stage of Teacher-Student models optimizes the lightweight scaling operation to refine the model's weights and prevent overfitting or forgetting learned patterns from unlabeled data. Meanwhile, the RD strategy helps keep these models diverged to encourage the student model to explore complementary representations. In addition, we use cascade regression to generate more reliable pseudo-labels for supervising the student model. Extensive experiments demonstrate the superior performance of our approach over state-of-the-art SSOD methods. Specifically, the proposed approach outperforms the Unbiased-Teacher method by an average mAP margin of 4.6% and 5.3% when using partially-labeled and fully-labeled data on the MS-COCO dataset, respectively.
Document Image Cleaning using Budget-Aware Black-Box Approximation
Jun 22, 2023Recent work has shown that by approximating the behaviour of a non-differentiable black-box function using a neural network, the black-box can be integrated into a differentiable training pipeline for end-to-end training. This methodology is termed "differentiable bypass,'' and a successful application of this method involves training a document preprocessor to improve the performance of a black-box OCR engine. However, a good approximation of an OCR engine requires querying it for all samples throughout the training process, which can be computationally and financially expensive. Several zeroth-order optimization (ZO) algorithms have been proposed in black-box attack literature to find adversarial examples for a black-box model by computing its gradient in a query-efficient manner. However, the query complexity and convergence rate of such algorithms makes them infeasible for our problem. In this work, we propose two sample selection algorithms to train an OCR preprocessor with less than 10% of the original system's OCR engine queries, resulting in more than 60% reduction of the total training time without significant loss of accuracy. We also show an improvement of 4% in the word-level accuracy of a commercial OCR engine with only 2.5% of the total queries and a 32x reduction in monetary cost. Further, we propose a simple ranking technique to prune 30% of the document images from the training dataset without affecting the system's performance.
Towards Early Prediction of Human iPSC Reprogramming Success
May 23, 2023

This paper presents advancements in automated early-stage prediction of the success of reprogramming human induced pluripotent stem cells (iPSCs) as a potential source for regenerative cell therapies.The minuscule success rate of iPSC-reprogramming of around $ 0.01% $ to $ 0.1% $ makes it labor-intensive, time-consuming, and exorbitantly expensive to generate a stable iPSC line. Since that requires culturing of millions of cells and intense biological scrutiny of multiple clones to identify a single optimal clone. The ability to reliably predict which cells are likely to establish as an optimal iPSC line at an early stage of pluripotency would therefore be ground-breaking in rendering this a practical and cost-effective approach to personalized medicine. Temporal information about changes in cellular appearance over time is crucial for predicting its future growth outcomes. In order to generate this data, we first performed continuous time-lapse imaging of iPSCs in culture using an ultra-high resolution microscope. We then annotated the locations and identities of cells in late-stage images where reliable manual identification is possible. Next, we propagated these labels backwards in time using a semi-automated tracking system to obtain labels for early stages of growth. Finally, we used this data to train deep neural networks to perform automatic cell segmentation and classification. Our code and data are available at https://github.com/abhineet123/ipsc_prediction.