 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Image Cleaning using Budget-Aware Black-Box Approximation
Jun 22, 2023Recent work has shown that by approximating the behaviour of a non-differentiable black-box function using a neural network, the black-box can be integrated into a differentiable training pipeline for end-to-end training. This methodology is termed "differentiable bypass,'' and a successful application of this method involves training a document preprocessor to improve the performance of a black-box OCR engine. However, a good approximation of an OCR engine requires querying it for all samples throughout the training process, which can be computationally and financially expensive. Several zeroth-order optimization (ZO) algorithms have been proposed in black-box attack literature to find adversarial examples for a black-box model by computing its gradient in a query-efficient manner. However, the query complexity and convergence rate of such algorithms makes them infeasible for our problem. In this work, we propose two sample selection algorithms to train an OCR preprocessor with less than 10% of the original system's OCR engine queries, resulting in more than 60% reduction of the total training time without significant loss of accuracy. We also show an improvement of 4% in the word-level accuracy of a commercial OCR engine with only 2.5% of the total queries and a 32x reduction in monetary cost. Further, we propose a simple ranking technique to prune 30% of the document images from the training dataset without affecting the system's performance.
Can Calibration Improve Sample Prioritization?
Oct 12, 2022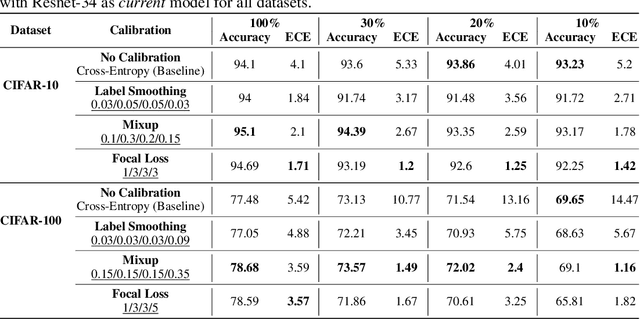
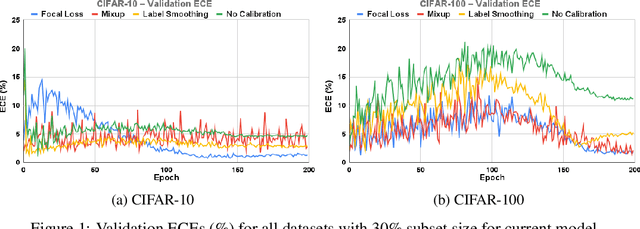
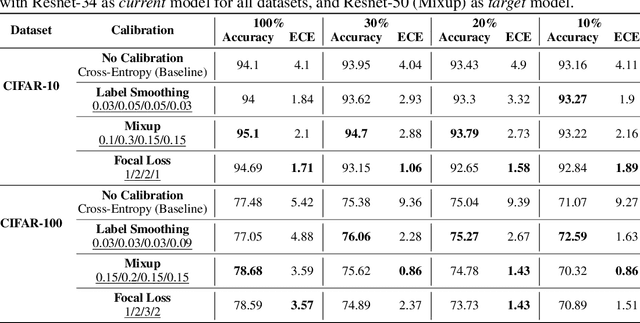
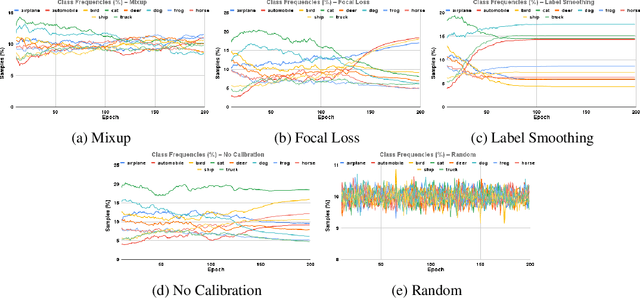
Calibration can reduce overconfident predictions of deep neural networks, but can calibration also accelerate training by selecting the right samples? In this paper, we show that it can. We study the effect of popular calibration techniques in selecting better subsets of samples during training (also called sample prioritization) and observe that calibration can improve the quality of subsets, reduce the number of examples per epoch (by at least 70%), and can thereby speed up the overall training process. We further study the effect of using calibrated pre-trained models coupled with calibration during training to guide sample prioritization, which again seems to improve the quality of samples selected.
Tiny-HR: Towards an interpretable machine learning pipeline for heart rate estimation on edge devices
Aug 16, 2022



The focus of this paper is a proof of concept, machine learning (ML) pipeline that extracts heart rate from pressure sensor data acquired on low-power edge devices. The ML pipeline consists an upsampler neural network, a signal quality classifier, and a 1D-convolutional neural network optimized for efficient and accurate heart rate estimation. The models were designed so the pipeline was less than 40 kB. Further, a hybrid pipeline consisting of the upsampler and classifier, followed by a peak detection algorithm was developed. The pipelines were deployed on ESP32 edge device and benchmarked against signal processing to determine the energy usage, and inference times. The results indicate that the proposed ML and hybrid pipeline reduces energy and time per inference by 82% and 28% compared to traditional algorithms. The main trade-off for ML pipeline was accuracy, with a mean absolute error (MAE) of 3.28, compared to 2.39 and 1.17 for the hybrid and signal processing pipelines. The ML models thus show promise for deployment in energy and computationally constrained devices. Further, the lower sampling rate and computational requirements for the ML pipeline could enable custom hardware solutions to reduce the cost and energy needs of wearable devices.