 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Adaptation for Continual Learning in Human Activity Recognition
Mar 08, 2026Wearable sensors in Internet of Things (IoT) ecosystems increasingly support applications such as remote health monitoring, elderly care, and smart home automation, all of which rely on robust human activity recognition (HAR). Continual learning systems must balance plasticity (learning new tasks) with stability (retaining prior knowledge), yet AI models often exhibit catastrophic forgetting, where learning new tasks degrades performance on earlier ones. This challenge is especially acute in domain-incremental HAR, where on-device models must adapt to new subjects with distinct movement patterns while maintaining accuracy on prior subjects without transmitting sensitive data to the cloud. We propose a parameter-efficient continual learning framework based on channel-wise gated modulation of frozen pretrained representations. Our key insight is that adaptation should operate through feature selection rather than feature generation: by restricting learned transformations to diagonal scaling of existing features, we preserve the geometry of pretrained representations while enabling subject-specific modulation. We provide a theoretical analysis showing that gating implements a bounded diagonal operator that limits representational drift compared to unconstrained linear transformations. Empirically, freezing the backbone substantially reduces forgetting, and lightweight gates restore lost adaptation capacity, achieving stability and plasticity simultaneously. On PAMAP2 with 8 sequential subjects, our approach reduces forgetting from 39.7% to 16.2% and improves final accuracy from 56.7% to 77.7%, while training less than 2% of parameters. Our method matches or exceeds standard continual learning baselines without replay buffers or task-specific regularization, confirming that structured diagonal operators are effective and efficient under distribution shift.
SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
May 30, 2024



Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights \(W\) and inject learnable matrices \(\Delta W\). These \(\Delta W\) matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically show a performance gap compared to full fine-tuning. Although recent PEFT methods have narrowed this gap, they do so at the cost of additional learnable parameters. We propose SVFT, a simple approach that fundamentally differs from existing methods: the structure imposed on \(\Delta W\) depends on the specific weight matrix \(W\). Specifically, SVFT updates \(W\) as a sparse combination of outer products of its singular vectors, training only the coefficients (scales) of these sparse combinations. This approach allows fine-grained control over expressivity through the number of coefficients. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that only recover up to 85% performance using 0.03 to 0.8% of the trainable parameter budget.
Can Calibration Improve Sample Prioritization?
Oct 12, 2022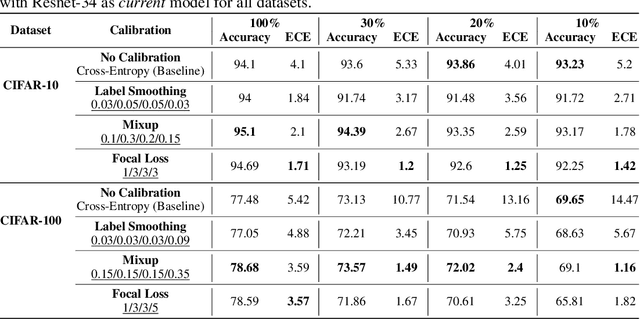
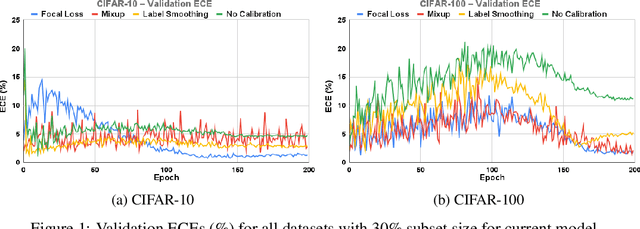
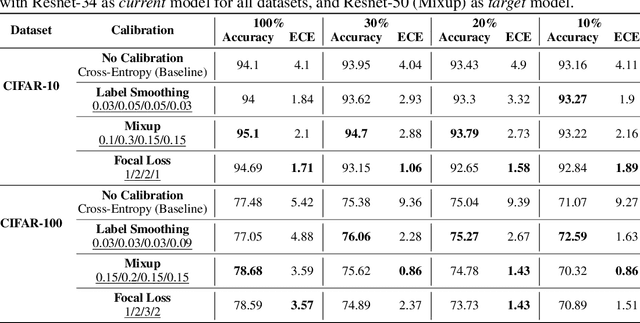
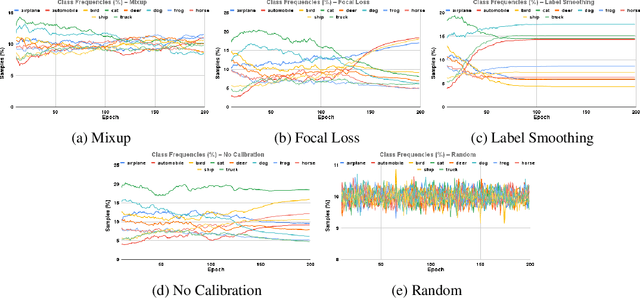
Calibration can reduce overconfident predictions of deep neural networks, but can calibration also accelerate training by selecting the right samples? In this paper, we show that it can. We study the effect of popular calibration techniques in selecting better subsets of samples during training (also called sample prioritization) and observe that calibration can improve the quality of subsets, reduce the number of examples per epoch (by at least 70%), and can thereby speed up the overall training process. We further study the effect of using calibrated pre-trained models coupled with calibration during training to guide sample prioritization, which again seems to improve the quality of samples selected.
Zero-Shot Federated Learning with New Classes for Audio Classification
Jun 18, 2021
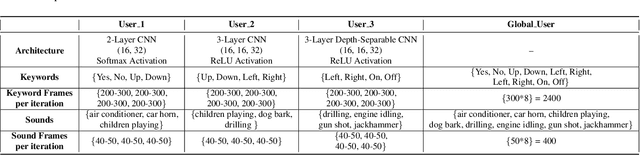


Federated learning is an effective way of extracting insights from different user devices while preserving the privacy of users. However, new classes with completely unseen data distributions can stream across any device in a federated learning setting, whose data cannot be accessed by the global server or other users. To this end, we propose a unified zero-shot framework to handle these aforementioned challenges during federated learning. We simulate two scenarios here -- 1) when the new class labels are not reported by the user, the traditional FL setting is used; 2) when new class labels are reported by the user, we synthesize Anonymized Data Impressions by calculating class similarity matrices corresponding to each device's new classes followed by unsupervised clustering to distinguish between new classes across different users. Moreover, our proposed framework can also handle statistical heterogeneities in both labels and models across the participating users. We empirically evaluate our framework on-device across different communication rounds (FL iterations) with new classes in both local and global updates, along with heterogeneous labels and models, on two widely used audio classification applications -- keyword spotting and urban sound classification, and observe an average deterministic accuracy increase of ~4.041% and ~4.258% respectively.
Bayesian Active Learning for Wearable Stress and Affect Detection
Dec 04, 2020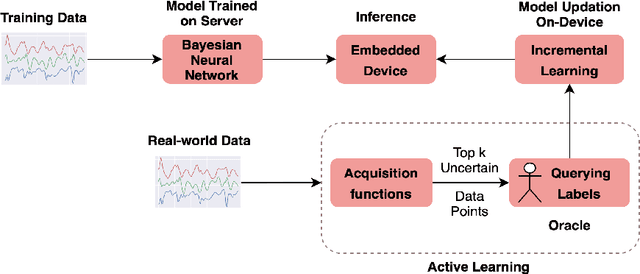


In the recent past, psychological stress has been increasingly observed in humans, and early detection is crucial to prevent health risks. Stress detection using on-device deep learning algorithms has been on the rise owing to advancements in pervasive computing. However, an important challenge that needs to be addressed is handling unlabeled data in real-time via suitable ground truthing techniques (like Active Learning), which should help establish affective states (labels) while also selecting only the most informative data points to query from an oracle. In this paper, we propose a framework with capabilities to represent model uncertainties through approximations in Bayesian Neural Networks using Monte-Carlo (MC) Dropout. This is combined with suitable acquisition functions for active learning. Empirical results on a popular stress and affect detection dataset experimented on a Raspberry Pi 2 indicate that our proposed framework achieves a considerable efficiency boost during inference, with a substantially low number of acquired pool points during active learning across various acquisition functions. Variation Ratios achieves an accuracy of 90.38% which is comparable to the maximum test accuracy achieved while training on about 40% lesser data.
Federated Learning with Heterogeneous Labels and Models for Mobile Activity Monitoring
Dec 04, 2020



Various health-care applications such as assisted living, fall detection, etc., require modeling of user behavior through Human Activity Recognition (HAR). Such applications demand characterization of insights from multiple resource-constrained user devices using machine learning techniques for effective personalized activity monitoring. On-device Federated Learning proves to be an effective approach for distributed and collaborative machine learning. However, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities across users. In addition, in this paper, we explore a new challenge of interest -- to handle heterogeneities in labels (activities) across users during federated learning. To this end, we propose a framework for federated label-based aggregation, which leverages overlapping information gain across activities using Model Distillation Update. We also propose that federated transfer of model scores is sufficient rather than model weight transfer from device to server. Empirical evaluation with the Heterogeneity Human Activity Recognition (HHAR) dataset (with four activities for effective elucidation of results) on Raspberry Pi 2 indicates an average deterministic accuracy increase of at least ~11.01%, thus demonstrating the on-device capabilities of our proposed framework.
Resource-Constrained Federated Learning with Heterogeneous Labels and Models
Nov 06, 2020

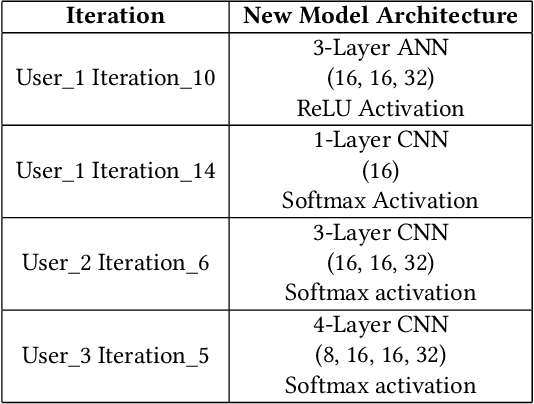

Various IoT applications demand resource-constrained machine learning mechanisms for different applications such as pervasive healthcare, activity monitoring, speech recognition, real-time computer vision, etc. This necessitates us to leverage information from multiple devices with few communication overheads. Federated Learning proves to be an extremely viable option for distributed and collaborative machine learning. Particularly, on-device federated learning is an active area of research, however, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities. In addition, in this paper we explore a new challenge of interest -- to handle label heterogeneities in federated learning. To this end, we propose a framework with simple $\alpha$-weighted federated aggregation of scores which leverages overlapping information gain across labels, while saving bandwidth costs in the process. Empirical evaluation on Animals-10 dataset (with 4 labels for effective elucidation of results) indicates an average deterministic accuracy increase of at least ~16.7%. We also demonstrate the on-device capabilities of our proposed framework by experimenting with federated learning and inference across different iterations on a Raspberry Pi 2, a single-board computing platform.
ActiveHARNet: Towards On-Device Deep Bayesian Active Learning for Human Activity Recognition
May 31, 2019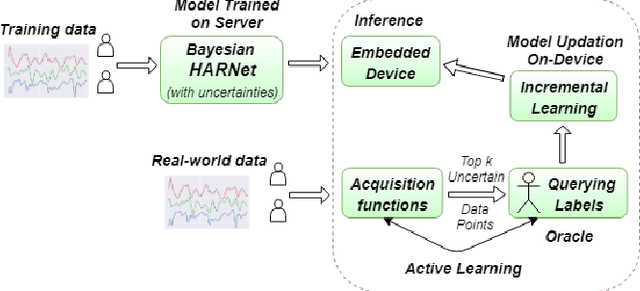

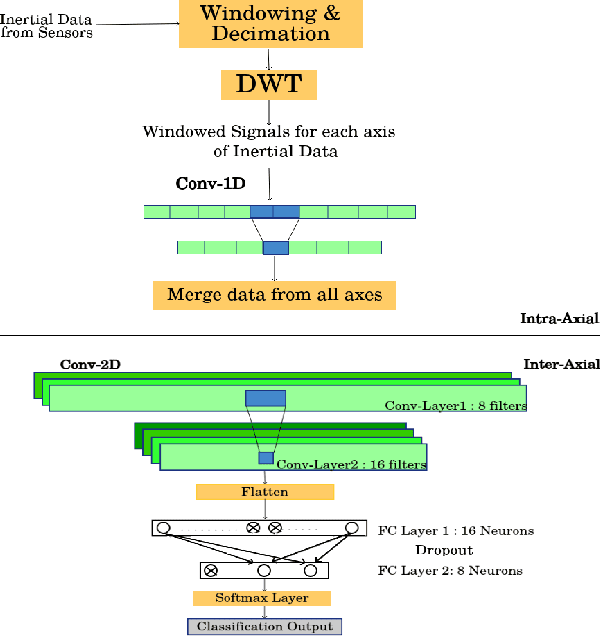
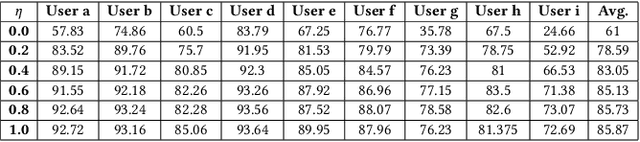
Various health-care applications such as assisted living, fall detection etc., require modeling of user behavior through Human Activity Recognition (HAR). HAR using mobile- and wearable-based deep learning algorithms have been on the rise owing to the advancements in pervasive computing. However, there are two other challenges that need to be addressed: first, the deep learning model should support on-device incremental training (model updation) from real-time incoming data points to learn user behavior over time, while also being resource-friendly; second, a suitable ground truthing technique (like Active Learning) should help establish labels on-the-fly while also selecting only the most informative data points to query from an oracle. Hence, in this paper, we propose ActiveHARNet, a resource-efficient deep ensembled model which supports on-device Incremental Learning and inference, with capabilities to represent model uncertainties through approximations in Bayesian Neural Networks using dropout. This is combined with suitable acquisition functions for active learning. Empirical results on two publicly available wrist-worn HAR and fall detection datasets indicate that ActiveHARNet achieves considerable efficiency boost during inference across different users, with a substantially low number of acquired pool points (at least 60% reduction) during incremental learning on both datasets experimented with various acquisition functions, thus demonstrating deployment and Incremental Learning feasibility.