 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Machine Learning Framework for Efficient Plant Disease Prediction
Sep 08, 2024Recently, Machine Learning (ML) methods are built-in as an important component in many smart agriculture platforms. In this paper, we explore the new combination of advanced ML methods for creating a smart agriculture platform where farmers could reach out for assistance from the public, or a closed circle of experts. Specifically, we focus on an easy way to assist the farmers in understanding plant diseases where the farmers can get help to solve the issues from the members of the community. The proposed system utilizes deep learning techniques for identifying the disease of the plant from the affected image, which acts as an initial identifier. Further, Natural Language Processing techniques are employed for ranking the solutions posted by the user community. In this paper, a message channel is built on top of Twitter, a popular social media platform to establish proper communication among farmers. Since the effect of the solutions can differ based on various other parameters, we extend the use of the concept drift approach and come up with a good solution and propose it to the farmer. We tested the proposed framework on the benchmark dataset, and it produces accurate and reliable results.
Towards Adaptive IMFs -- Generalization of utility functions in Multi-Agent Frameworks
May 14, 2024Intent Management Function (IMF) is an integral part of future-generation networks. In recent years, there has been some work on AI-based IMFs that can handle conflicting intents and prioritize the global objective based on apriori definition of the utility function and accorded priorities for competing intents. Some of the earlier works use Multi-Agent Reinforcement Learning (MARL) techniques with AdHoc Teaming (AHT) approaches for efficient conflict handling in IMF. However, the success of such frameworks in real-life scenarios requires them to be flexible to business situations. The intent priorities can change and the utility function, which measures the extent of intent fulfilment, may also vary in definition. This paper proposes a novel mechanism whereby the IMF can generalize to different forms of utility functions and change of intent priorities at run-time without additional training. Such generalization ability, without additional training requirements, would help to deploy IMF in live networks where customer intents and priorities change frequently. Results on the network emulator demonstrate the efficacy of the approach, scalability for new intents, outperforming existing techniques that require additional training to achieve the same degree of flexibility thereby saving cost, and increasing efficiency and adaptability.
Goals are Enough: Inducing AdHoc cooperation among unseen Multi-Agent systems in IMFs
Oct 26, 2023Intent-based management will play a critical role in achieving customers' expectations in the next-generation mobile networks. Traditional methods cannot perform efficient resource management since they tend to handle each expectation independently. Existing approaches, e.g., based on multi-agent reinforcement learning (MARL) allocate resources in an efficient fashion when there are conflicting expectations on the network slice. However, in reality, systems are often far more complex to be addressed by a standalone MARL formulation. Often there exists a hierarchical structure of intent fulfilment where multiple pre-trained, self-interested agents may need to be further orchestrated by a supervisor or controller agent. Such agents may arrive in the system adhoc, which then needs to be orchestrated along with other available agents. Retraining the whole system every time is often infeasible given the associated time and cost. Given the challenges, such adhoc coordination of pre-trained systems could be achieved through an intelligent supervisor agent which incentivizes pre-trained RL/MARL agents through sets of dynamic contracts (goals or bonuses) and encourages them to act as a cohesive unit towards fulfilling a global expectation. Some approaches use a rule-based supervisor agent and deploy the hierarchical constituent agents sequentially, based on human-coded rules. In the current work, we propose a framework whereby pre-trained agents can be orchestrated in parallel leveraging an AI-based supervisor agent. For this, we propose to use Adhoc-Teaming approaches which assign optimal goals to the MARL agents and incentivize them to exhibit certain desired behaviours. Results on the network emulator show that the proposed approach results in faster and improved fulfilment of expectations when compared to rule-based approaches and even generalizes to changes in environments.
Domain Adaptation of Reinforcement Learning Agents based on Network Service Proximity
Mar 02, 2023The dynamic and evolutionary nature of service requirements in wireless networks has motivated the telecom industry to consider intelligent self-adapting Reinforcement Learning (RL) agents for controlling the growing portfolio of network services. Infusion of many new types of services is anticipated with future adoption of 6G networks, and sometimes these services will be defined by applications that are external to the network. An RL agent trained for managing the needs of a specific service type may not be ideal for managing a different service type without domain adaptation. We provide a simple heuristic for evaluating a measure of proximity between a new service and existing services, and show that the RL agent of the most proximal service rapidly adapts to the new service type through a well defined process of domain adaptation. Our approach enables a trained source policy to adapt to new situations with changed dynamics without retraining a new policy, thereby achieving significant computing and cost-effectiveness. Such domain adaptation techniques may soon provide a foundation for more generalized RL-based service management under the face of rapidly evolving service types.
Multi-agent reinforcement learning for intent-based service assurance in cellular networks
Aug 07, 2022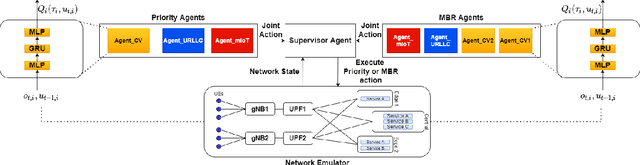
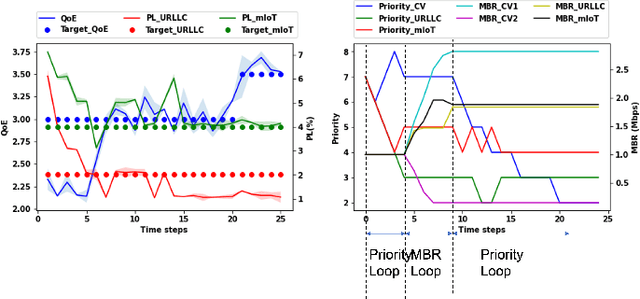
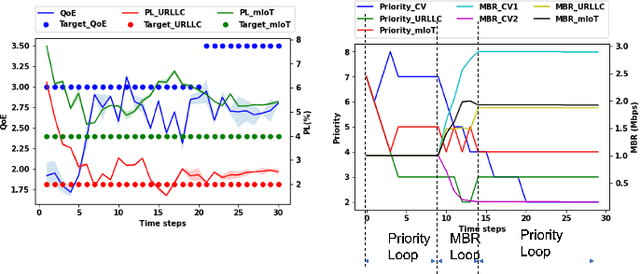
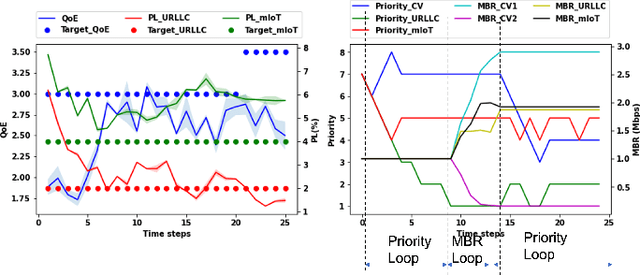
Recently, intent-based management is receiving good attention in telecom networks owing to stringent performance requirements for many of the use cases. Several approaches on the literature employ traditional methods in the telecom domain to fulfill intents on the KPIs, which can be defined as a closed loop. However, these methods consider every closed-loop independent of each other which degrades the combined closed-loop performance. Also, when many closed loops are needed, these methods are not easily scalable. Multi-agent reinforcement learning (MARL) techniques have shown significant promise in many areas in which traditional closed-loop control falls short, typically for complex coordination and conflict management among loops. In this work, we propose a method based on MARL to achieve intent-based management without the requirement of the model of the underlying system. Moreover, when there are conflicting intents, the MARL agents can implicitly incentivize the loops to cooperate, without human interaction, by prioritizing the important KPIs. Experiments have been performed on a network emulator on optimizing KPIs for three services and we observe the proposed system performs well and is able to fulfill all existing intents when there are enough resources or prioritize the KPIs when there are scarce resources.
DSDF: An approach to handle stochastic agents in collaborative multi-agent reinforcement learning
Sep 14, 2021
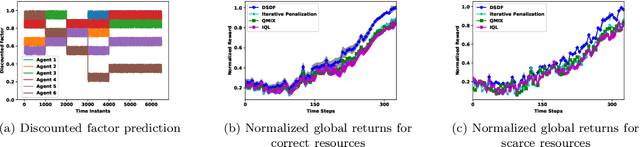

Multi-Agent reinforcement learning has received lot of attention in recent years and have applications in many different areas. Existing methods involving Centralized Training and Decentralized execution, attempts to train the agents towards learning a pattern of coordinated actions to arrive at optimal joint policy. However if some agents are stochastic to varying degrees of stochasticity, the above methods often fail to converge and provides poor coordination among agents. In this paper we show how this stochasticity of agents, which could be a result of malfunction or aging of robots, can add to the uncertainty in coordination and there contribute to unsatisfactory global coordination. In this case, the deterministic agents have to understand the behavior and limitations of the stochastic agents while arriving at optimal joint policy. Our solution, DSDF which tunes the discounted factor for the agents according to uncertainty and use the values to update the utility networks of individual agents. DSDF also helps in imparting an extent of reliability in coordination thereby granting stochastic agents tasks which are immediate and of shorter trajectory with deterministic ones taking the tasks which involve longer planning. Such an method enables joint co-ordinations of agents some of which may be partially performing and thereby can reduce or delay the investment of agent/robot replacement in many circumstances. Results on benchmark environment for different scenarios shows the efficacy of the proposed approach when compared with existing approaches.
Zero-Shot Federated Learning with New Classes for Audio Classification
Jun 18, 2021
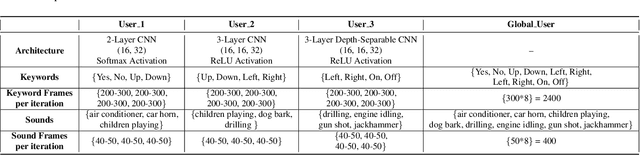


Federated learning is an effective way of extracting insights from different user devices while preserving the privacy of users. However, new classes with completely unseen data distributions can stream across any device in a federated learning setting, whose data cannot be accessed by the global server or other users. To this end, we propose a unified zero-shot framework to handle these aforementioned challenges during federated learning. We simulate two scenarios here -- 1) when the new class labels are not reported by the user, the traditional FL setting is used; 2) when new class labels are reported by the user, we synthesize Anonymized Data Impressions by calculating class similarity matrices corresponding to each device's new classes followed by unsupervised clustering to distinguish between new classes across different users. Moreover, our proposed framework can also handle statistical heterogeneities in both labels and models across the participating users. We empirically evaluate our framework on-device across different communication rounds (FL iterations) with new classes in both local and global updates, along with heterogeneous labels and models, on two widely used audio classification applications -- keyword spotting and urban sound classification, and observe an average deterministic accuracy increase of ~4.041% and ~4.258% respectively.
Federated Learning with Heterogeneous Labels and Models for Mobile Activity Monitoring
Dec 04, 2020



Various health-care applications such as assisted living, fall detection, etc., require modeling of user behavior through Human Activity Recognition (HAR). Such applications demand characterization of insights from multiple resource-constrained user devices using machine learning techniques for effective personalized activity monitoring. On-device Federated Learning proves to be an effective approach for distributed and collaborative machine learning. However, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities across users. In addition, in this paper, we explore a new challenge of interest -- to handle heterogeneities in labels (activities) across users during federated learning. To this end, we propose a framework for federated label-based aggregation, which leverages overlapping information gain across activities using Model Distillation Update. We also propose that federated transfer of model scores is sufficient rather than model weight transfer from device to server. Empirical evaluation with the Heterogeneity Human Activity Recognition (HHAR) dataset (with four activities for effective elucidation of results) on Raspberry Pi 2 indicates an average deterministic accuracy increase of at least ~11.01%, thus demonstrating the on-device capabilities of our proposed framework.
Resource-Constrained Federated Learning with Heterogeneous Labels and Models
Nov 06, 2020

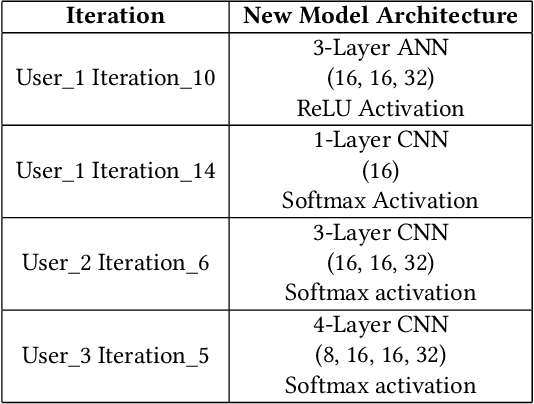

Various IoT applications demand resource-constrained machine learning mechanisms for different applications such as pervasive healthcare, activity monitoring, speech recognition, real-time computer vision, etc. This necessitates us to leverage information from multiple devices with few communication overheads. Federated Learning proves to be an extremely viable option for distributed and collaborative machine learning. Particularly, on-device federated learning is an active area of research, however, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities. In addition, in this paper we explore a new challenge of interest -- to handle label heterogeneities in federated learning. To this end, we propose a framework with simple $\alpha$-weighted federated aggregation of scores which leverages overlapping information gain across labels, while saving bandwidth costs in the process. Empirical evaluation on Animals-10 dataset (with 4 labels for effective elucidation of results) indicates an average deterministic accuracy increase of at least ~16.7%. We also demonstrate the on-device capabilities of our proposed framework by experimenting with federated learning and inference across different iterations on a Raspberry Pi 2, a single-board computing platform.
Reinforcement Learning based dynamic weighing of Ensemble Models for Time Series Forecasting
Aug 20, 2020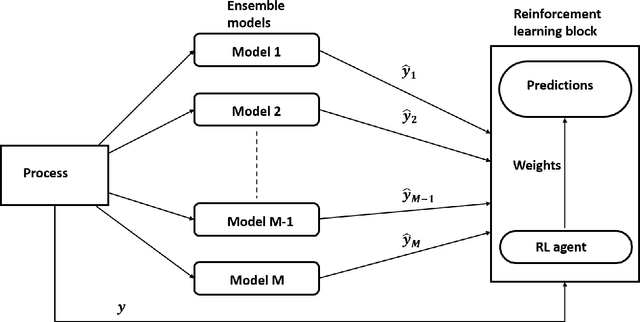
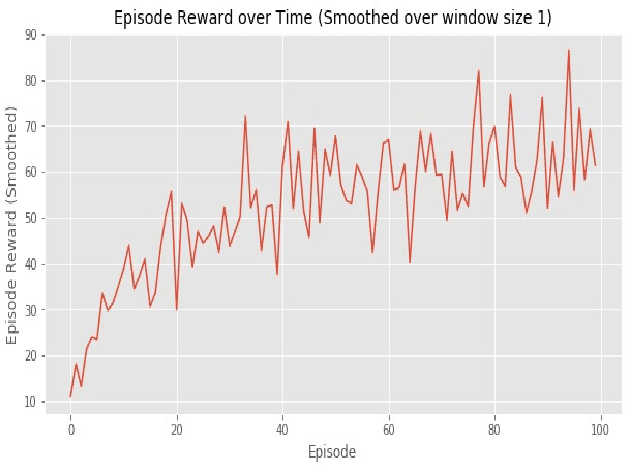
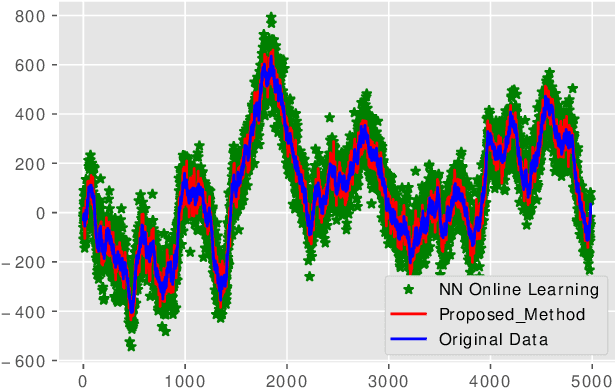
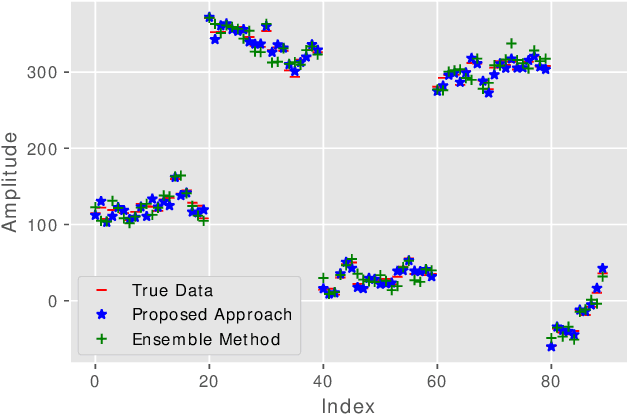
Ensemble models are powerful model building tools that are developed with a focus to improve the accuracy of model predictions. They find applications in time series forecasting in varied scenarios including but not limited to process industries, health care, and economics where a single model might not provide optimal performance. It is known that if models selected for data modelling are distinct (linear/non-linear, static/dynamic) and independent (minimally correlated models), the accuracy of the predictions is improved. Various approaches suggested in the literature to weigh the ensemble models use a static set of weights. Due to this limitation, approaches using a static set of weights for weighing ensemble models cannot capture the dynamic changes or local features of the data effectively. To address this issue, a Reinforcement Learning (RL) approach to dynamically assign and update weights of each of the models at different time instants depending on the nature of data and the individual model predictions is proposed in this work. The RL method implemented online, essentially learns to update the weights and reduce the errors as the time progresses. Simulation studies on time series data showed that the dynamic weighted approach using RL learns the weight better than existing approaches. The accuracy of the proposed method is compared with an existing approach of online Neural Network tuning quantitatively through normalized mean square error(NMSE) values.