 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCT-MARL: Graph-Based Contrastive Transfer for Sample-Efficient Cooperative Multi-Agent Reinforcement Learning
Jun 23, 2026In cooperative multi-agent reinforcement learning (MARL), from a deployment perspective, it is challenging and expensive to train agents from scratch for each new environment or task. In this work, we propose GCT-MARL, a transfer learning framework that builds on the multi-view graph contrastive backbone of MAIL and augments it with a per-view, adaptively weighted alignment loss and a two-phase training protocol specifically designed for transfer across populations of varying sizes and compositions. We empirically demonstrate that the proposed framework markedly accelerates convergence on the target task relative to from-scratch training, in both homogeneous (within-faction, varying N) and heterogeneous (cross-faction and mixed unit-type) transfer scenarios. Furthermore, we show that the framework naturally supports continual learning by sequentially chaining the two-phase transfer protocol across a series of related tasks. Overall, this work provides a unified approach to mitigating key limitations in current MARL transfer methods with new insights at both methodological and empirical levels.
ASALT: Adaptive State Alignment for Lateral Transfer in Multi-agent Reinforcement Learning
Jun 23, 2026Multi-agent reinforcement learning (MARL) addresses the problem of training multiple agents that pursue collaborative, competitive, or mixed objectives. Prior work has investigated transfer learning between source and target domains in MARL; however, the majority of existing approaches impose the constraint that the dimensionalities of the observation space and the global state space must be identical across domains. In this paper, we introduce a method that explicitly accommodates mismatched state-space dimensionalities between source and target domains. The proposed approach, ASALT, incorporates both observation-level and state-level adapters that map the target-domain observations and global states into a shared embedding space, thereby enabling more effective transfer of knowledge across both actors and critics. These adapters can generate embeddings that support efficient strategy transfer across heterogeneous domains. Experimental results on multiple configurations in standard benchmark environments demonstrate that ASALT surpasses existing baselines in terms of sample efficiency and global return in cooperative settings, but its effectiveness depends on the degree of mismatch between source and target domains. Furthermore, our findings indicate that ASALT mitigates negative transfer, which frequently constitutes a major obstacle when transferring policies between domains with differing observation and action spaces.
Towards Adaptive IMFs -- Generalization of utility functions in Multi-Agent Frameworks
May 14, 2024Intent Management Function (IMF) is an integral part of future-generation networks. In recent years, there has been some work on AI-based IMFs that can handle conflicting intents and prioritize the global objective based on apriori definition of the utility function and accorded priorities for competing intents. Some of the earlier works use Multi-Agent Reinforcement Learning (MARL) techniques with AdHoc Teaming (AHT) approaches for efficient conflict handling in IMF. However, the success of such frameworks in real-life scenarios requires them to be flexible to business situations. The intent priorities can change and the utility function, which measures the extent of intent fulfilment, may also vary in definition. This paper proposes a novel mechanism whereby the IMF can generalize to different forms of utility functions and change of intent priorities at run-time without additional training. Such generalization ability, without additional training requirements, would help to deploy IMF in live networks where customer intents and priorities change frequently. Results on the network emulator demonstrate the efficacy of the approach, scalability for new intents, outperforming existing techniques that require additional training to achieve the same degree of flexibility thereby saving cost, and increasing efficiency and adaptability.
Goals are Enough: Inducing AdHoc cooperation among unseen Multi-Agent systems in IMFs
Oct 26, 2023Intent-based management will play a critical role in achieving customers' expectations in the next-generation mobile networks. Traditional methods cannot perform efficient resource management since they tend to handle each expectation independently. Existing approaches, e.g., based on multi-agent reinforcement learning (MARL) allocate resources in an efficient fashion when there are conflicting expectations on the network slice. However, in reality, systems are often far more complex to be addressed by a standalone MARL formulation. Often there exists a hierarchical structure of intent fulfilment where multiple pre-trained, self-interested agents may need to be further orchestrated by a supervisor or controller agent. Such agents may arrive in the system adhoc, which then needs to be orchestrated along with other available agents. Retraining the whole system every time is often infeasible given the associated time and cost. Given the challenges, such adhoc coordination of pre-trained systems could be achieved through an intelligent supervisor agent which incentivizes pre-trained RL/MARL agents through sets of dynamic contracts (goals or bonuses) and encourages them to act as a cohesive unit towards fulfilling a global expectation. Some approaches use a rule-based supervisor agent and deploy the hierarchical constituent agents sequentially, based on human-coded rules. In the current work, we propose a framework whereby pre-trained agents can be orchestrated in parallel leveraging an AI-based supervisor agent. For this, we propose to use Adhoc-Teaming approaches which assign optimal goals to the MARL agents and incentivize them to exhibit certain desired behaviours. Results on the network emulator show that the proposed approach results in faster and improved fulfilment of expectations when compared to rule-based approaches and even generalizes to changes in environments.
Domain Adaptation of Reinforcement Learning Agents based on Network Service Proximity
Mar 02, 2023The dynamic and evolutionary nature of service requirements in wireless networks has motivated the telecom industry to consider intelligent self-adapting Reinforcement Learning (RL) agents for controlling the growing portfolio of network services. Infusion of many new types of services is anticipated with future adoption of 6G networks, and sometimes these services will be defined by applications that are external to the network. An RL agent trained for managing the needs of a specific service type may not be ideal for managing a different service type without domain adaptation. We provide a simple heuristic for evaluating a measure of proximity between a new service and existing services, and show that the RL agent of the most proximal service rapidly adapts to the new service type through a well defined process of domain adaptation. Our approach enables a trained source policy to adapt to new situations with changed dynamics without retraining a new policy, thereby achieving significant computing and cost-effectiveness. Such domain adaptation techniques may soon provide a foundation for more generalized RL-based service management under the face of rapidly evolving service types.
Multi-agent reinforcement learning for intent-based service assurance in cellular networks
Aug 07, 2022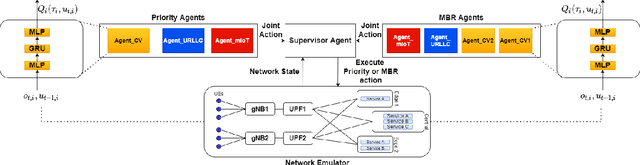
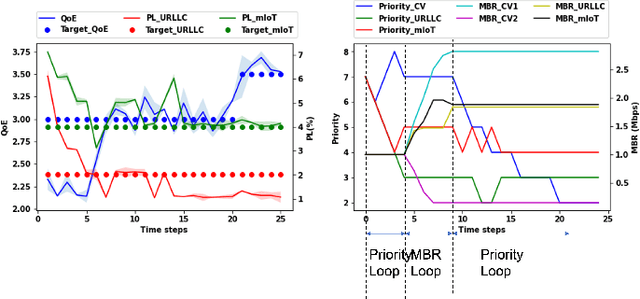
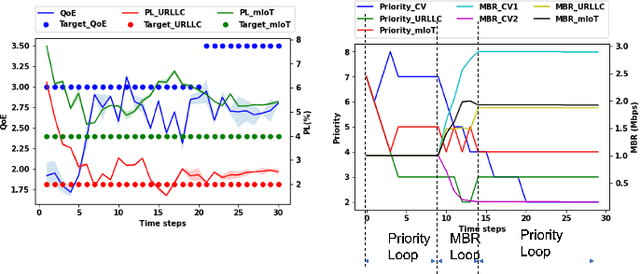
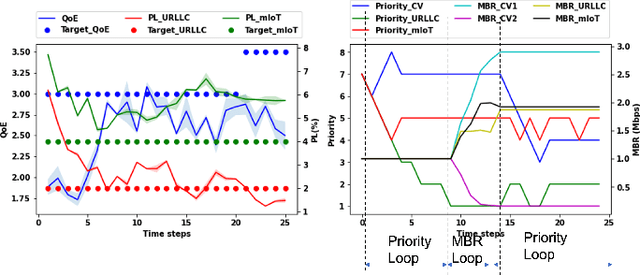
Recently, intent-based management is receiving good attention in telecom networks owing to stringent performance requirements for many of the use cases. Several approaches on the literature employ traditional methods in the telecom domain to fulfill intents on the KPIs, which can be defined as a closed loop. However, these methods consider every closed-loop independent of each other which degrades the combined closed-loop performance. Also, when many closed loops are needed, these methods are not easily scalable. Multi-agent reinforcement learning (MARL) techniques have shown significant promise in many areas in which traditional closed-loop control falls short, typically for complex coordination and conflict management among loops. In this work, we propose a method based on MARL to achieve intent-based management without the requirement of the model of the underlying system. Moreover, when there are conflicting intents, the MARL agents can implicitly incentivize the loops to cooperate, without human interaction, by prioritizing the important KPIs. Experiments have been performed on a network emulator on optimizing KPIs for three services and we observe the proposed system performs well and is able to fulfill all existing intents when there are enough resources or prioritize the KPIs when there are scarce resources.
DSDF: An approach to handle stochastic agents in collaborative multi-agent reinforcement learning
Sep 14, 2021
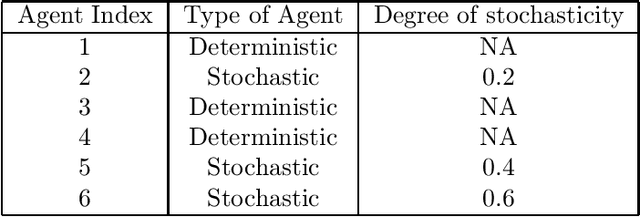
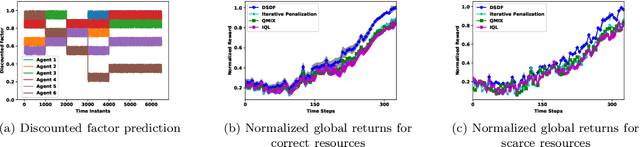

Multi-Agent reinforcement learning has received lot of attention in recent years and have applications in many different areas. Existing methods involving Centralized Training and Decentralized execution, attempts to train the agents towards learning a pattern of coordinated actions to arrive at optimal joint policy. However if some agents are stochastic to varying degrees of stochasticity, the above methods often fail to converge and provides poor coordination among agents. In this paper we show how this stochasticity of agents, which could be a result of malfunction or aging of robots, can add to the uncertainty in coordination and there contribute to unsatisfactory global coordination. In this case, the deterministic agents have to understand the behavior and limitations of the stochastic agents while arriving at optimal joint policy. Our solution, DSDF which tunes the discounted factor for the agents according to uncertainty and use the values to update the utility networks of individual agents. DSDF also helps in imparting an extent of reliability in coordination thereby granting stochastic agents tasks which are immediate and of shorter trajectory with deterministic ones taking the tasks which involve longer planning. Such an method enables joint co-ordinations of agents some of which may be partially performing and thereby can reduce or delay the investment of agent/robot replacement in many circumstances. Results on benchmark environment for different scenarios shows the efficacy of the proposed approach when compared with existing approaches.