 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Safer Actions in Policy Optimization for Constrained Reinforcement Learning
Sep 11, 2025Constrained Reinforcement Learning (RL) aims to maximize the return while adhering to predefined constraint limits, which represent domain-specific safety requirements. In continuous control settings, where learning agents govern system actions, balancing the trade-off between reward maximization and constraint satisfaction remains a significant challenge. Policy optimization methods often exhibit instability near constraint boundaries, resulting in suboptimal training performance. To address this issue, we introduce a novel approach that integrates an adaptive incentive mechanism in addition to the reward structure to stay within the constraint bound before approaching the constraint boundary. Building on this insight, we propose Incrementally Penalized Proximal Policy Optimization (IP3O), a practical algorithm that enforces a progressively increasing penalty to stabilize training dynamics. Through empirical evaluation on benchmark environments, we demonstrate the efficacy of IP3O compared to the performance of state-of-the-art Safe RL algorithms. Furthermore, we provide theoretical guarantees by deriving a bound on the worst-case error of the optimality achieved by our algorithm.
Tackling Uncertainties in Multi-Agent Reinforcement Learning through Integration of Agent Termination Dynamics
Jan 21, 2025



Multi-Agent Reinforcement Learning (MARL) has gained significant traction for solving complex real-world tasks, but the inherent stochasticity and uncertainty in these environments pose substantial challenges to efficient and robust policy learning. While Distributional Reinforcement Learning has been successfully applied in single-agent settings to address risk and uncertainty, its application in MARL is substantially limited. In this work, we propose a novel approach that integrates distributional learning with a safety-focused loss function to improve convergence in cooperative MARL tasks. Specifically, we introduce a Barrier Function based loss that leverages safety metrics, identified from inherent faults in the system, into the policy learning process. This additional loss term helps mitigate risks and encourages safer exploration during the early stages of training. We evaluate our method in the StarCraft II micromanagement benchmark, where our approach demonstrates improved convergence and outperforms state-of-the-art baselines in terms of both safety and task completion. Our results suggest that incorporating safety considerations can significantly enhance learning performance in complex, multi-agent environments.
Towards Adaptive IMFs -- Generalization of utility functions in Multi-Agent Frameworks
May 14, 2024Intent Management Function (IMF) is an integral part of future-generation networks. In recent years, there has been some work on AI-based IMFs that can handle conflicting intents and prioritize the global objective based on apriori definition of the utility function and accorded priorities for competing intents. Some of the earlier works use Multi-Agent Reinforcement Learning (MARL) techniques with AdHoc Teaming (AHT) approaches for efficient conflict handling in IMF. However, the success of such frameworks in real-life scenarios requires them to be flexible to business situations. The intent priorities can change and the utility function, which measures the extent of intent fulfilment, may also vary in definition. This paper proposes a novel mechanism whereby the IMF can generalize to different forms of utility functions and change of intent priorities at run-time without additional training. Such generalization ability, without additional training requirements, would help to deploy IMF in live networks where customer intents and priorities change frequently. Results on the network emulator demonstrate the efficacy of the approach, scalability for new intents, outperforming existing techniques that require additional training to achieve the same degree of flexibility thereby saving cost, and increasing efficiency and adaptability.
DietCNN: Multiplication-free Inference for Quantized CNNs
May 09, 2023



The rising demand for networked embedded systems with machine intelligence has been a catalyst for sustained attempts by the research community to implement Convolutional Neural Networks (CNN) based inferencing on embedded resource-limited devices. Redesigning a CNN by removing costly multiplication operations has already shown promising results in terms of reducing inference energy usage. This paper proposes a new method for replacing multiplications in a CNN by table look-ups. Unlike existing methods that completely modify the CNN operations, the proposed methodology preserves the semantics of the major CNN operations. Conforming to the existing mechanism of the CNN layer operations ensures that the reliability of a standard CNN is preserved. It is shown that the proposed multiplication-free CNN, based on a single activation codebook, can achieve 4.7x, 5.6x, and 3.5x reduction in energy per inference in an FPGA implementation of MNIST-LeNet-5, CIFAR10-VGG-11, and Tiny ImageNet-ResNet-18 respectively. Our results show that the DietCNN approach significantly improves the resource consumption and latency of deep inference for smaller models, often used in embedded systems. Our code is available at: https://github.com/swadeykgp/DietCNN
Domain Adaptation of Reinforcement Learning Agents based on Network Service Proximity
Mar 02, 2023The dynamic and evolutionary nature of service requirements in wireless networks has motivated the telecom industry to consider intelligent self-adapting Reinforcement Learning (RL) agents for controlling the growing portfolio of network services. Infusion of many new types of services is anticipated with future adoption of 6G networks, and sometimes these services will be defined by applications that are external to the network. An RL agent trained for managing the needs of a specific service type may not be ideal for managing a different service type without domain adaptation. We provide a simple heuristic for evaluating a measure of proximity between a new service and existing services, and show that the RL agent of the most proximal service rapidly adapts to the new service type through a well defined process of domain adaptation. Our approach enables a trained source policy to adapt to new situations with changed dynamics without retraining a new policy, thereby achieving significant computing and cost-effectiveness. Such domain adaptation techniques may soon provide a foundation for more generalized RL-based service management under the face of rapidly evolving service types.
Penalizing Proposals using Classifiers for Semi-Supervised Object Detection
Jun 02, 2022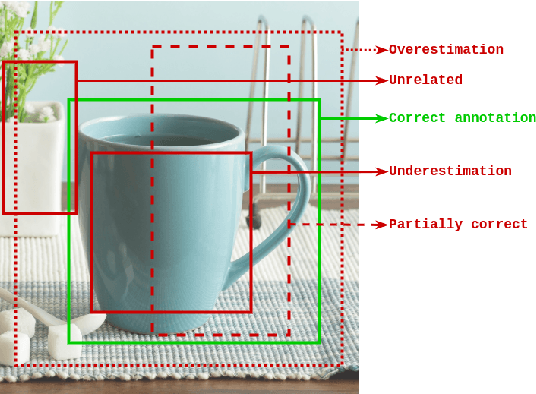

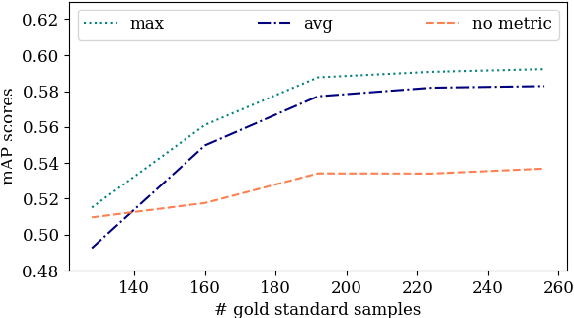

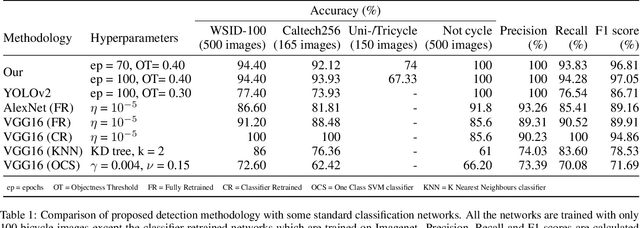
Obtaining gold standard annotated data for object detection is often costly, involving human-level effort. Semi-supervised object detection algorithms solve the problem with a small amount of gold-standard labels and a large unlabelled dataset used to generate silver-standard labels. But training on the silver standard labels does not produce good results, because they are machine-generated annotations. In this work, we design a modified loss function to train on large silver standard annotated sets generated by a weak annotator. We include a confidence metric associated with the annotation as an additional term in the loss function, signifying the quality of the annotation. We test the effectiveness of our approach on various test sets and use numerous variations to compare the results with some of the current approaches to object detection. In comparison with the baseline where no confidence metric is used, we achieved a 4% gain in mAP with 25% labeled data and 10% gain in mAP with 50% labeled data by using the proposed confidence metric.
Hierarchical Program-Triggered Reinforcement Learning Agents For Automated Driving
Mar 25, 2021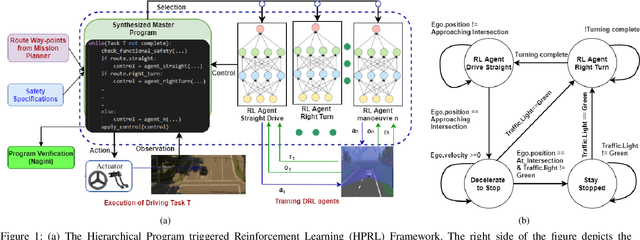
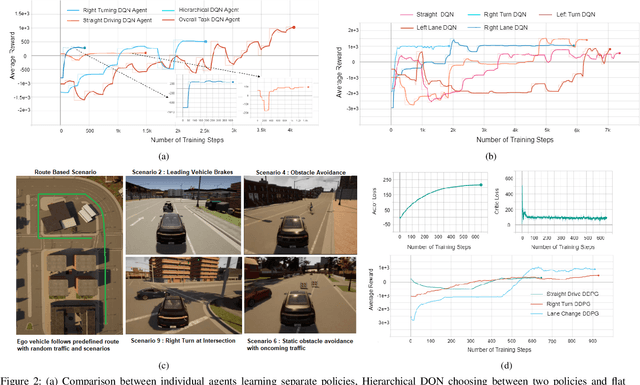

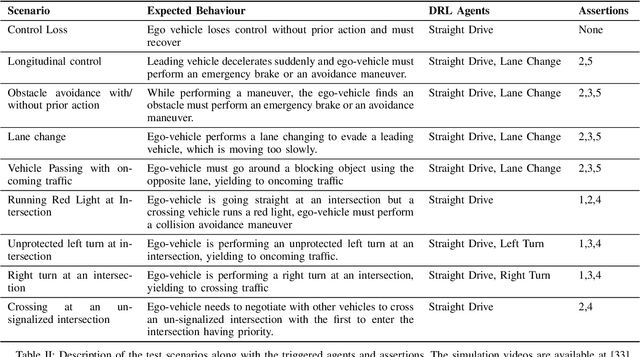
Recent advances in Reinforcement Learning (RL) combined with Deep Learning (DL) have demonstrated impressive performance in complex tasks, including autonomous driving. The use of RL agents in autonomous driving leads to a smooth human-like driving experience, but the limited interpretability of Deep Reinforcement Learning (DRL) creates a verification and certification bottleneck. Instead of relying on RL agents to learn complex tasks, we propose HPRL - Hierarchical Program-triggered Reinforcement Learning, which uses a hierarchy consisting of a structured program along with multiple RL agents, each trained to perform a relatively simple task. The focus of verification shifts to the master program under simple guarantees from the RL agents, leading to a significantly more interpretable and verifiable implementation as compared to a complex RL agent. The evaluation of the framework is demonstrated on different driving tasks, and NHTSA precrash scenarios using CARLA, an open-source dynamic urban simulation environment.
Semi-Lexical Languages -- A Formal Basis for Unifying Machine Learning and Symbolic Reasoning in Computer Vision
Apr 25, 2020

Human vision is able to compensate imperfections in sensory inputs from the real world by reasoning based on prior knowledge about the world. Machine learning has had a significant impact on computer vision due to its inherent ability in handling imprecision, but the absence of a reasoning framework based on domain knowledge limits its ability to interpret complex scenarios. We propose semi-lexical languages as a formal basis for dealing with imperfect tokens provided by the real world. The power of machine learning is used to map the imperfect tokens into the alphabet of the language and symbolic reasoning is used to determine the membership of input in the language. Semi-lexical languages also have bindings that prevent the variations in which a semi-lexical token is interpreted in different parts of the input, thereby leaning on deduction to enhance the quality of recognition of individual tokens. We present case studies that demonstrate the advantage of using such a framework over pure machine learning and pure symbolic methods.
Flexible Mining of Prefix Sequences from Time-Series Traces
May 29, 2019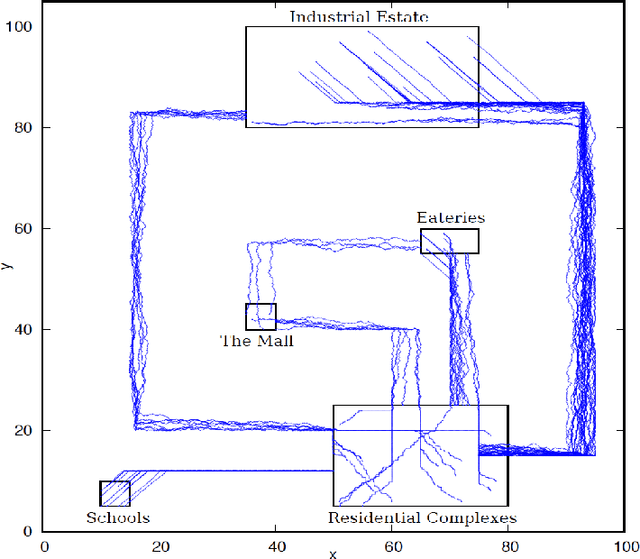
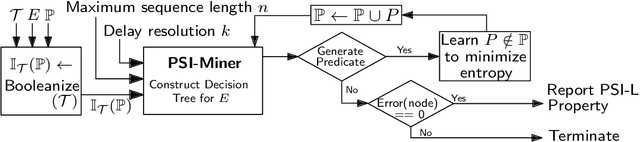
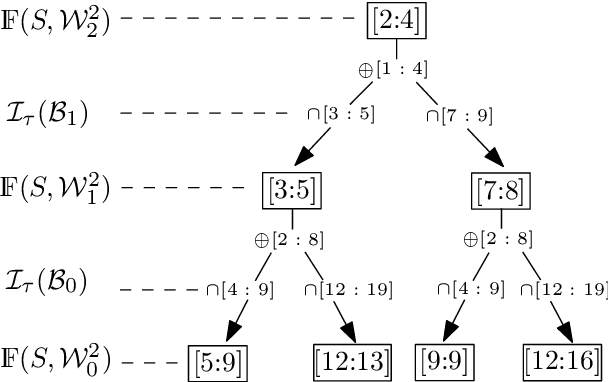
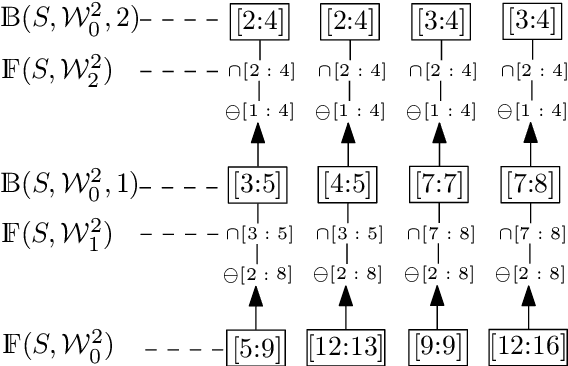
Mining temporal assertions from time-series data using information theory to filter real properties from incidental ones is a practically significant challenge. The problem is complex for continuous or hybrid systems because the degrees of influence on a consequent from a timed-sequence of predicates (called its prefix sequence), varies continuously over dense time intervals. We propose a parameterized method that uses interval arithmetic for flexibly learning prefix sequences having influence on a defined consequent over various time scales and predicates over system variables.
Algorithms for Generating Ordered Solutions for Explicit AND/OR Structures
Jan 23, 2014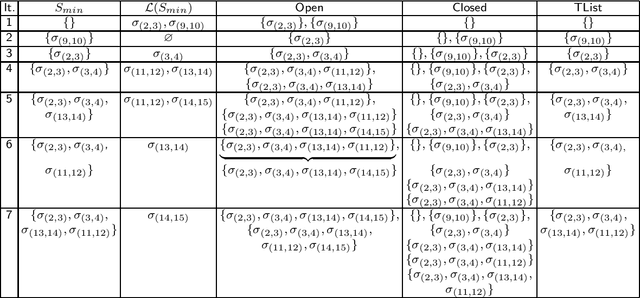
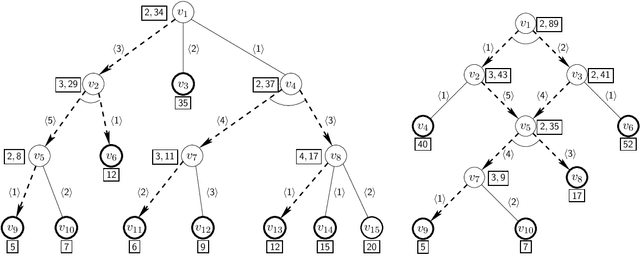
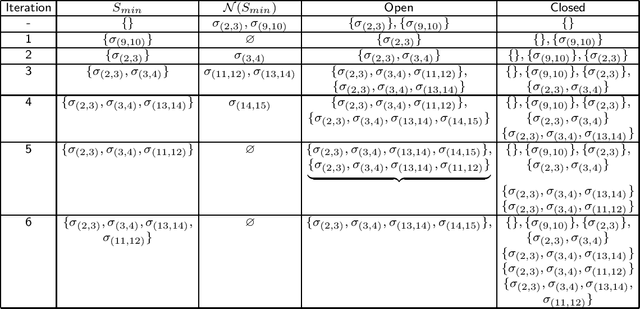
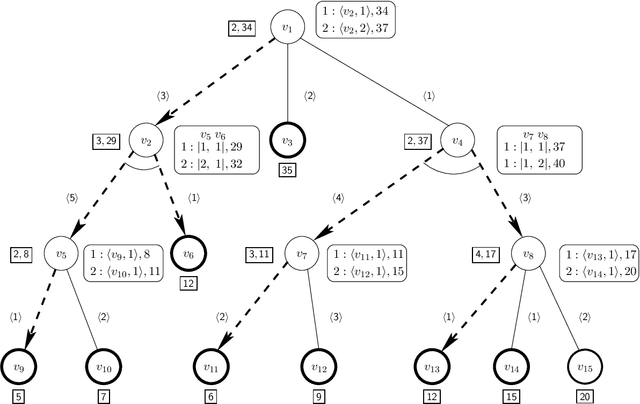
We present algorithms for generating alternative solutions for explicit acyclic AND/OR structures in non-decreasing order of cost. The proposed algorithms use a best first search technique and report the solutions using an implicit representation ordered by cost. In this paper, we present two versions of the search algorithm -- (a) an initial version of the best first search algorithm, ASG, which may present one solution more than once while generating the ordered solutions, and (b) another version, LASG, which avoids the construction of the duplicate solutions. The actual solutions can be reconstructed quickly from the implicit compact representation used. We have applied the methods on a few test domains, some of them are synthetic while the others are based on well known problems including the search space of the 5-peg Tower of Hanoi problem, the matrix-chain multiplication problem and the problem of finding secondary structure of RNA. Experimental results show the efficacy of the proposed algorithms over the existing approach. Our proposed algorithms have potential use in various domains ranging from knowledge based frameworks to service composition, where the AND/OR structure is widely used for representing problems.