 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD$^2$: Analysis and Detection of Adversarial Threats in Visual Perception for End-to-End Autonomous Driving Systems
Feb 10, 2026End-to-end autonomous driving systems have achieved significant progress, yet their adversarial robustness remains largely underexplored. In this work, we conduct a closed-loop evaluation of state-of-the-art autonomous driving agents under black-box adversarial threat models in CARLA. Specifically, we consider three representative attack vectors on the visual perception pipeline: (i) a physics-based blur attack induced by acoustic waves, (ii) an electromagnetic interference attack that distorts captured images, and (iii) a digital attack that adds ghost objects as carefully crafted bounded perturbations on images. Our experiments on two advanced agents, Transfuser and Interfuser, reveal severe vulnerabilities to such attacks, with driving scores dropping by up to 99% in the worst case, raising valid safety concerns. To help mitigate such threats, we further propose a lightweight Attack Detection model for Autonomous Driving systems (AD$^2$) based on attention mechanisms that capture spatial-temporal consistency. Comprehensive experiments across multi-camera inputs on CARLA show that our detector achieves superior detection capability and computational efficiency compared to existing approaches.
Incentivizing Safer Actions in Policy Optimization for Constrained Reinforcement Learning
Sep 11, 2025Constrained Reinforcement Learning (RL) aims to maximize the return while adhering to predefined constraint limits, which represent domain-specific safety requirements. In continuous control settings, where learning agents govern system actions, balancing the trade-off between reward maximization and constraint satisfaction remains a significant challenge. Policy optimization methods often exhibit instability near constraint boundaries, resulting in suboptimal training performance. To address this issue, we introduce a novel approach that integrates an adaptive incentive mechanism in addition to the reward structure to stay within the constraint bound before approaching the constraint boundary. Building on this insight, we propose Incrementally Penalized Proximal Policy Optimization (IP3O), a practical algorithm that enforces a progressively increasing penalty to stabilize training dynamics. Through empirical evaluation on benchmark environments, we demonstrate the efficacy of IP3O compared to the performance of state-of-the-art Safe RL algorithms. Furthermore, we provide theoretical guarantees by deriving a bound on the worst-case error of the optimality achieved by our algorithm.
Tackling Uncertainties in Multi-Agent Reinforcement Learning through Integration of Agent Termination Dynamics
Jan 21, 2025



Multi-Agent Reinforcement Learning (MARL) has gained significant traction for solving complex real-world tasks, but the inherent stochasticity and uncertainty in these environments pose substantial challenges to efficient and robust policy learning. While Distributional Reinforcement Learning has been successfully applied in single-agent settings to address risk and uncertainty, its application in MARL is substantially limited. In this work, we propose a novel approach that integrates distributional learning with a safety-focused loss function to improve convergence in cooperative MARL tasks. Specifically, we introduce a Barrier Function based loss that leverages safety metrics, identified from inherent faults in the system, into the policy learning process. This additional loss term helps mitigate risks and encourages safer exploration during the early stages of training. We evaluate our method in the StarCraft II micromanagement benchmark, where our approach demonstrates improved convergence and outperforms state-of-the-art baselines in terms of both safety and task completion. Our results suggest that incorporating safety considerations can significantly enhance learning performance in complex, multi-agent environments.
Co-designing Intelligent Control of Building HVACs and Microgrids
Jul 18, 2021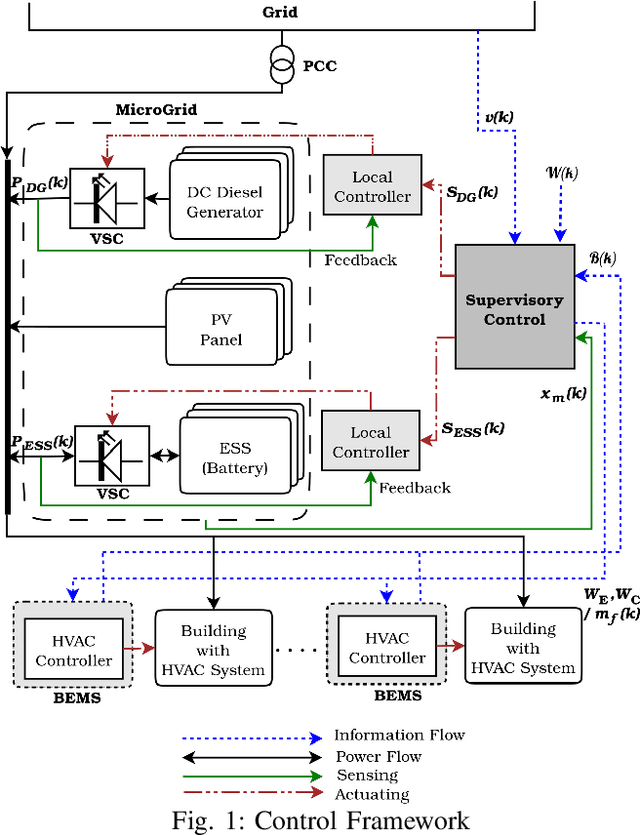

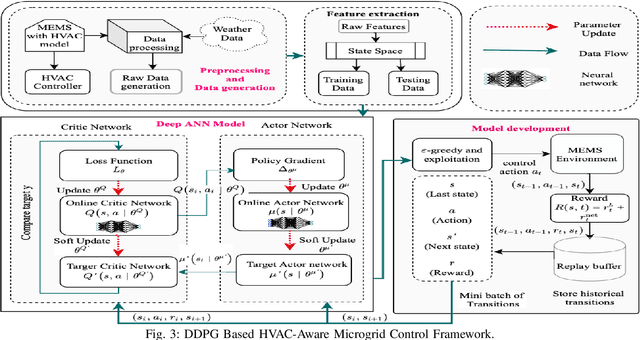
Building loads consume roughly 40% of the energy produced in developed countries, a significant part of which is invested towards building temperature-control infrastructure. Therein, renewable resource-based microgrids offer a greener and cheaper alternative. This communication explores the possible co-design of microgrid power dispatch and building HVAC (heating, ventilation and air conditioning system) actuations with the objective of effective temperature control under minimised operating cost. For this, we attempt control designs with various levels of abstractions based on information available about microgrid and HVAC system models using the Deep Reinforcement Learning (DRL) technique. We provide control architectures that consider model information ranging from completely determined system models to systems with fully unknown parameter settings and illustrate the advantages of DRL for the design prescriptions.
An RL-Based Adaptive Detection Strategy to Secure Cyber-Physical Systems
Mar 04, 2021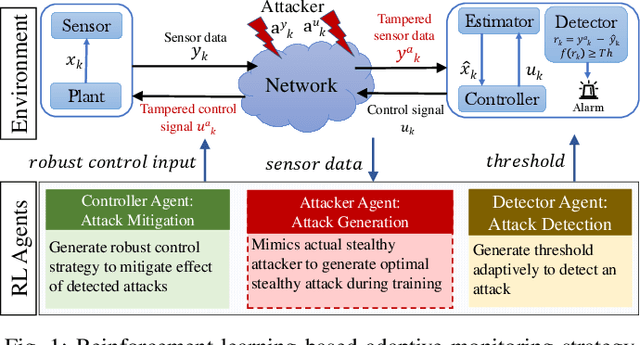


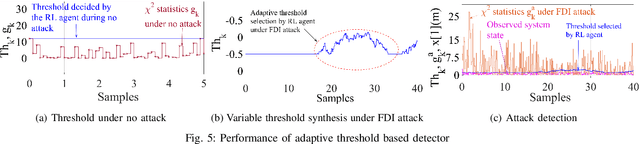
Increased dependence on networked, software based control has escalated the vulnerabilities of Cyber Physical Systems (CPSs). Detection and monitoring components developed leveraging dynamical systems theory are often employed as lightweight security measures for protecting such safety critical CPSs against false data injection attacks. However, existing approaches do not correlate attack scenarios with parameters of detection systems. In the present work, we propose a Reinforcement Learning (RL) based framework which adaptively sets the parameters of such detectors based on experience learned from attack scenarios, maximizing detection rate and minimizing false alarms in the process while attempting performance preserving control actions.