 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Budget Optimization for Multichannel Advertising Using Combinatorial Bandits
Feb 05, 2025Effective budget allocation is crucial for optimizing the performance of digital advertising campaigns. However, the development of practical budget allocation algorithms remain limited, primarily due to the lack of public datasets and comprehensive simulation environments capable of verifying the intricacies of real-world advertising. While multi-armed bandit (MAB) algorithms have been extensively studied, their efficacy diminishes in non-stationary environments where quick adaptation to changing market dynamics is essential. In this paper, we advance the field of budget allocation in digital advertising by introducing three key contributions. First, we develop a simulation environment designed to mimic multichannel advertising campaigns over extended time horizons, incorporating logged real-world data. Second, we propose an enhanced combinatorial bandit budget allocation strategy that leverages a saturating mean function and a targeted exploration mechanism with change-point detection. This approach dynamically adapts to changing market conditions, improving allocation efficiency by filtering target regions based on domain knowledge. Finally, we present both theoretical analysis and empirical results, demonstrating that our method consistently outperforms baseline strategies, achieving higher rewards and lower regret across multiple real-world campaigns.
Auto-bidding in real-time auctions via Oracle Imitation Learning (OIL)
Dec 17, 2024Online advertising has become one of the most successful business models of the internet era. Impression opportunities are typically allocated through real-time auctions, where advertisers bid to secure advertisement slots. Deciding the best bid for an impression opportunity is challenging, due to the stochastic nature of user behavior and the variability of advertisement traffic over time. In this work, we propose a framework for training auto-bidding agents in multi-slot second-price auctions to maximize acquisitions (e.g., clicks, conversions) while adhering to budget and cost-per-acquisition (CPA) constraints. We exploit the insight that, after an advertisement campaign concludes, determining the optimal bids for each impression opportunity can be framed as a multiple-choice knapsack problem (MCKP) with a nonlinear objective. We propose an "oracle" algorithm that identifies a near-optimal combination of impression opportunities and advertisement slots, considering both past and future advertisement traffic data. This oracle solution serves as a training target for a student network which bids having access only to real-time information, a method we term Oracle Imitation Learning (OIL). Through numerical experiments, we demonstrate that OIL achieves superior performance compared to both online and offline reinforcement learning algorithms, offering improved sample efficiency. Notably, OIL shifts the complexity of training auto-bidding agents from crafting sophisticated learning algorithms to solving a nonlinear constrained optimization problem efficiently.
Integrating Domain Knowledge for handling Limited Data in Offline RL
Jun 11, 2024With the ability to learn from static datasets, Offline Reinforcement Learning (RL) emerges as a compelling avenue for real-world applications. However, state-of-the-art offline RL algorithms perform sub-optimally when confronted with limited data confined to specific regions within the state space. The performance degradation is attributed to the inability of offline RL algorithms to learn appropriate actions for rare or unseen observations. This paper proposes a novel domain knowledge-based regularization technique and adaptively refines the initial domain knowledge to considerably boost performance in limited data with partially omitted states. The key insight is that the regularization term mitigates erroneous actions for sparse samples and unobserved states covered by domain knowledge. Empirical evaluations on standard discrete environment datasets demonstrate a substantial average performance increase of at least 27% compared to existing offline RL algorithms operating on limited data.
Augmenting Offline RL with Unlabeled Data
Jun 11, 2024Recent advancements in offline Reinforcement Learning (Offline RL) have led to an increased focus on methods based on conservative policy updates to address the Out-of-Distribution (OOD) issue. These methods typically involve adding behavior regularization or modifying the critic learning objective, focusing primarily on states or actions with substantial dataset support. However, we challenge this prevailing notion by asserting that the absence of an action or state from a dataset does not necessarily imply its suboptimality. In this paper, we propose a novel approach to tackle the OOD problem. We introduce an offline RL teacher-student framework, complemented by a policy similarity measure. This framework enables the student policy to gain insights not only from the offline RL dataset but also from the knowledge transferred by a teacher policy. The teacher policy is trained using another dataset consisting of state-action pairs, which can be viewed as practical domain knowledge acquired without direct interaction with the environment. We believe this additional knowledge is key to effectively solving the OOD issue. This research represents a significant advancement in integrating a teacher-student network into the actor-critic framework, opening new avenues for studies on knowledge transfer in offline RL and effectively addressing the OOD challenge.
Hierarchical Program-Triggered Reinforcement Learning Agents For Automated Driving
Mar 25, 2021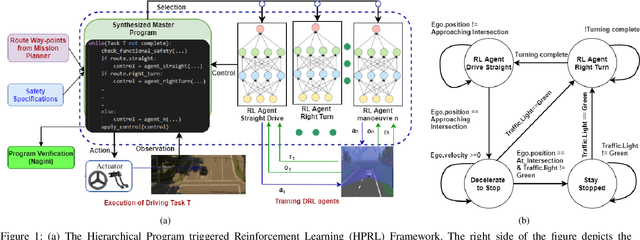
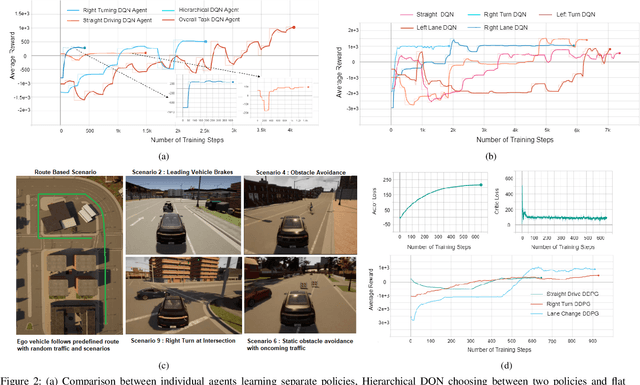

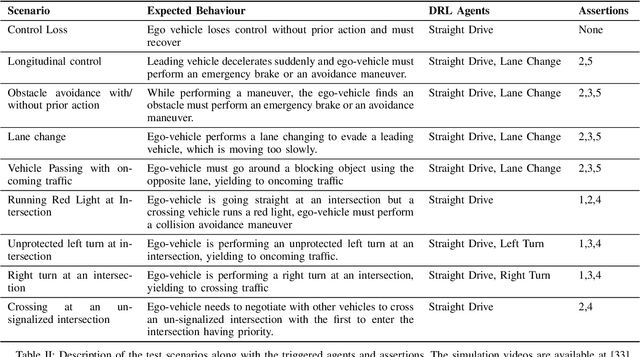
Recent advances in Reinforcement Learning (RL) combined with Deep Learning (DL) have demonstrated impressive performance in complex tasks, including autonomous driving. The use of RL agents in autonomous driving leads to a smooth human-like driving experience, but the limited interpretability of Deep Reinforcement Learning (DRL) creates a verification and certification bottleneck. Instead of relying on RL agents to learn complex tasks, we propose HPRL - Hierarchical Program-triggered Reinforcement Learning, which uses a hierarchy consisting of a structured program along with multiple RL agents, each trained to perform a relatively simple task. The focus of verification shifts to the master program under simple guarantees from the RL agents, leading to a significantly more interpretable and verifiable implementation as compared to a complex RL agent. The evaluation of the framework is demonstrated on different driving tasks, and NHTSA precrash scenarios using CARLA, an open-source dynamic urban simulation environment.
Semi-Lexical Languages -- A Formal Basis for Unifying Machine Learning and Symbolic Reasoning in Computer Vision
Apr 25, 2020

Human vision is able to compensate imperfections in sensory inputs from the real world by reasoning based on prior knowledge about the world. Machine learning has had a significant impact on computer vision due to its inherent ability in handling imprecision, but the absence of a reasoning framework based on domain knowledge limits its ability to interpret complex scenarios. We propose semi-lexical languages as a formal basis for dealing with imperfect tokens provided by the real world. The power of machine learning is used to map the imperfect tokens into the alphabet of the language and symbolic reasoning is used to determine the membership of input in the language. Semi-lexical languages also have bindings that prevent the variations in which a semi-lexical token is interpreted in different parts of the input, thereby leaning on deduction to enhance the quality of recognition of individual tokens. We present case studies that demonstrate the advantage of using such a framework over pure machine learning and pure symbolic methods.