 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordance-Guided Coarse-to-Fine Exploration for Base Placement in Open-Vocabulary Mobile Manipulation
Nov 09, 2025



In open-vocabulary mobile manipulation (OVMM), task success often hinges on the selection of an appropriate base placement for the robot. Existing approaches typically navigate to proximity-based regions without considering affordances, resulting in frequent manipulation failures. We propose Affordance-Guided Coarse-to-Fine Exploration, a zero-shot framework for base placement that integrates semantic understanding from vision-language models (VLMs) with geometric feasibility through an iterative optimization process. Our method constructs cross-modal representations, namely Affordance RGB and Obstacle Map+, to align semantics with spatial context. This enables reasoning that extends beyond the egocentric limitations of RGB perception. To ensure interaction is guided by task-relevant affordances, we leverage coarse semantic priors from VLMs to guide the search toward task-relevant regions and refine placements with geometric constraints, thereby reducing the risk of convergence to local optima. Evaluated on five diverse open-vocabulary mobile manipulation tasks, our system achieves an 85% success rate, significantly outperforming classical geometric planners and VLM-based methods. This demonstrates the promise of affordance-aware and multimodal reasoning for generalizable, instruction-conditioned planning in OVMM.
MovieCORE: COgnitive REasoning in Movies
Aug 26, 2025



This paper introduces MovieCORE, a novel video question answering (VQA) dataset designed to probe deeper cognitive understanding of movie content. Unlike existing datasets that focus on surface-level comprehension, MovieCORE emphasizes questions that engage System-2 thinking while remaining specific to the video material. We present an innovative agentic brainstorming approach, utilizing multiple large language models (LLMs) as thought agents to generate and refine high-quality question-answer pairs. To evaluate dataset quality, we develop a set of cognitive tests assessing depth, thought-provocation potential, and syntactic complexity. We also propose a comprehensive evaluation scheme for assessing VQA model performance on deeper cognitive tasks. To address the limitations of existing video-language models (VLMs), we introduce an agentic enhancement module, Agentic Choice Enhancement (ACE), which improves model reasoning capabilities post-training by up to 25%. Our work contributes to advancing movie understanding in AI systems and provides valuable insights into the capabilities and limitations of current VQA models when faced with more challenging, nuanced questions about cinematic content. Our project page, dataset and code can be found at https://joslefaure.github.io/assets/html/moviecore.html.
Distribution Discrepancy and Feature Heterogeneity for Active 3D Object Detection
Sep 11, 2024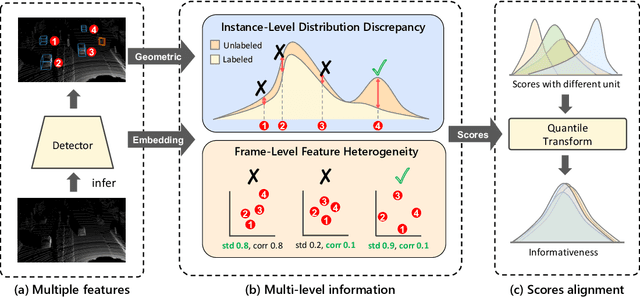

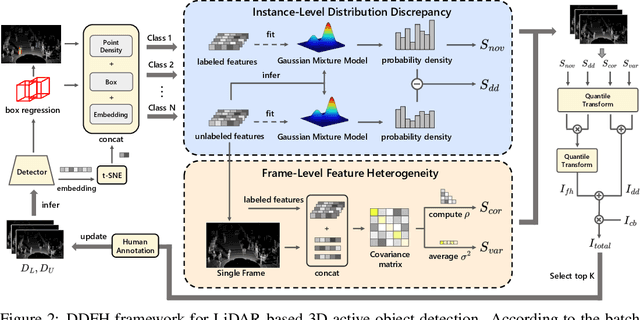
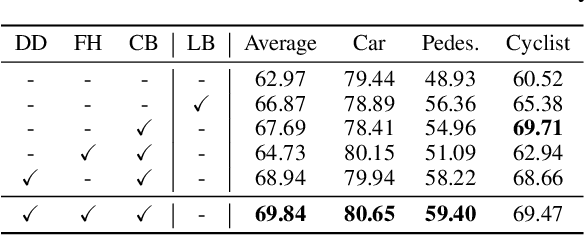
LiDAR-based 3D object detection is a critical technology for the development of autonomous driving and robotics. However, the high cost of data annotation limits its advancement. We propose a novel and effective active learning (AL) method called Distribution Discrepancy and Feature Heterogeneity (DDFH), which simultaneously considers geometric features and model embeddings, assessing information from both the instance-level and frame-level perspectives. Distribution Discrepancy evaluates the difference and novelty of instances within the unlabeled and labeled distributions, enabling the model to learn efficiently with limited data. Feature Heterogeneity ensures the heterogeneity of intra-frame instance features, maintaining feature diversity while avoiding redundant or similar instances, thus minimizing annotation costs. Finally, multiple indicators are efficiently aggregated using Quantile Transform, providing a unified measure of informativeness. Extensive experiments demonstrate that DDFH outperforms the current state-of-the-art (SOTA) methods on the KITTI and Waymo datasets, effectively reducing the bounding box annotation cost by 56.3% and showing robustness when working with both one-stage and two-stage models.
Context-Aware Replanning with Pre-explored Semantic Map for Object Navigation
Sep 07, 2024
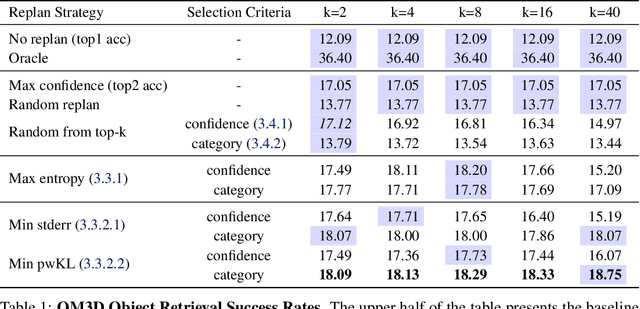
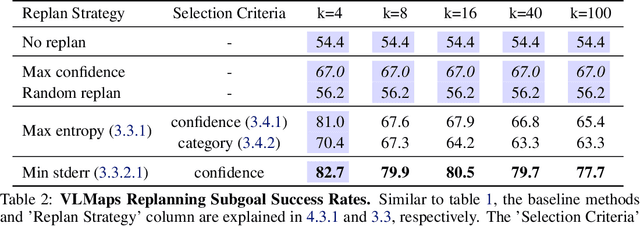
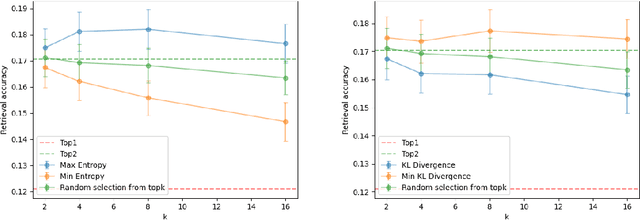
Pre-explored Semantic Maps, constructed through prior exploration using visual language models (VLMs), have proven effective as foundational elements for training-free robotic applications. However, existing approaches assume the map's accuracy and do not provide effective mechanisms for revising decisions based on incorrect maps. To address this, we introduce Context-Aware Replanning (CARe), which estimates map uncertainty through confidence scores and multi-view consistency, enabling the agent to revise erroneous decisions stemming from inaccurate maps without requiring additional labels. We demonstrate the effectiveness of our proposed method by integrating it with two modern mapping backbones, VLMaps and OpenMask3D, and observe significant performance improvements in object navigation tasks. More details can be found on the project page: https://carmaps.github.io/supplements/.
Bridging Episodes and Semantics: A Novel Framework for Long-Form Video Understanding
Aug 30, 2024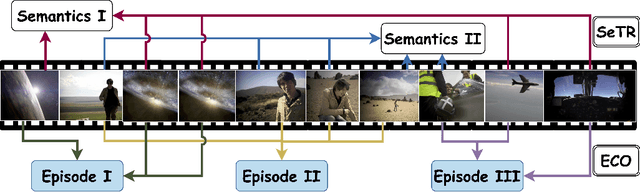
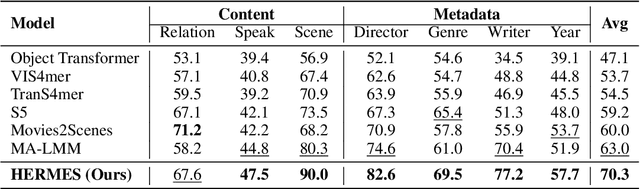
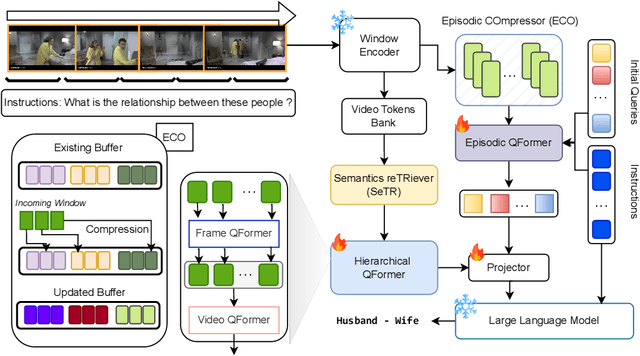

While existing research often treats long-form videos as extended short videos, we propose a novel approach that more accurately reflects human cognition. This paper introduces BREASE: BRidging Episodes And SEmantics for Long-Form Video Understanding, a model that simulates episodic memory accumulation to capture action sequences and reinforces them with semantic knowledge dispersed throughout the video. Our work makes two key contributions: First, we develop an Episodic COmpressor (ECO) that efficiently aggregates crucial representations from micro to semi-macro levels. Second, we propose a Semantics reTRiever (SeTR) that enhances these aggregated representations with semantic information by focusing on the broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. Extensive experiments demonstrate that BREASE achieves state-of-the-art performance across multiple long video understanding benchmarks in both zero-shot and fully-supervised settings. The project page and code are at: https://joslefaure.github.io/assets/html/hermes.html.
Augmenting Offline RL with Unlabeled Data
Jun 11, 2024Recent advancements in offline Reinforcement Learning (Offline RL) have led to an increased focus on methods based on conservative policy updates to address the Out-of-Distribution (OOD) issue. These methods typically involve adding behavior regularization or modifying the critic learning objective, focusing primarily on states or actions with substantial dataset support. However, we challenge this prevailing notion by asserting that the absence of an action or state from a dataset does not necessarily imply its suboptimality. In this paper, we propose a novel approach to tackle the OOD problem. We introduce an offline RL teacher-student framework, complemented by a policy similarity measure. This framework enables the student policy to gain insights not only from the offline RL dataset but also from the knowledge transferred by a teacher policy. The teacher policy is trained using another dataset consisting of state-action pairs, which can be viewed as practical domain knowledge acquired without direct interaction with the environment. We believe this additional knowledge is key to effectively solving the OOD issue. This research represents a significant advancement in integrating a teacher-student network into the actor-critic framework, opening new avenues for studies on knowledge transfer in offline RL and effectively addressing the OOD challenge.
Integrating Domain Knowledge for handling Limited Data in Offline RL
Jun 11, 2024With the ability to learn from static datasets, Offline Reinforcement Learning (RL) emerges as a compelling avenue for real-world applications. However, state-of-the-art offline RL algorithms perform sub-optimally when confronted with limited data confined to specific regions within the state space. The performance degradation is attributed to the inability of offline RL algorithms to learn appropriate actions for rare or unseen observations. This paper proposes a novel domain knowledge-based regularization technique and adaptively refines the initial domain knowledge to considerably boost performance in limited data with partially omitted states. The key insight is that the regularization term mitigates erroneous actions for sparse samples and unobserved states covered by domain knowledge. Empirical evaluations on standard discrete environment datasets demonstrate a substantial average performance increase of at least 27% compared to existing offline RL algorithms operating on limited data.
Shared-unique Features and Task-aware Prioritized Sampling on Multi-task Reinforcement Learning
Jun 02, 2024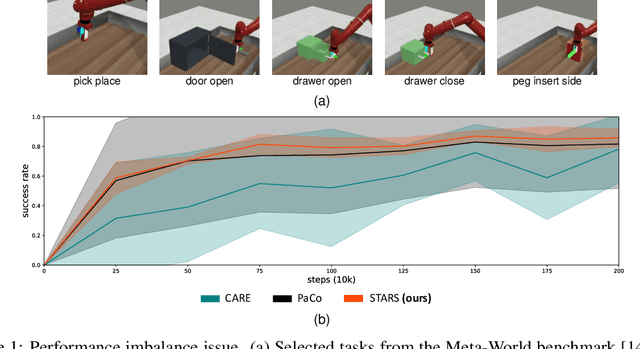
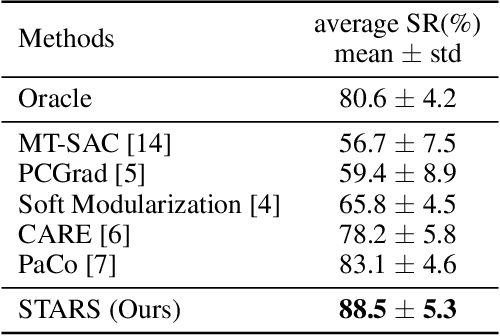
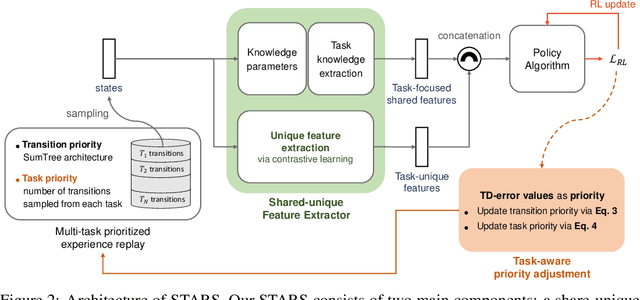

We observe that current state-of-the-art (SOTA) methods suffer from the performance imbalance issue when performing multi-task reinforcement learning (MTRL) tasks. While these methods may achieve impressive performance on average, they perform extremely poorly on a few tasks. To address this, we propose a new and effective method called STARS, which consists of two novel strategies: a shared-unique feature extractor and task-aware prioritized sampling. First, the shared-unique feature extractor learns both shared and task-specific features to enable better synergy of knowledge between different tasks. Second, the task-aware sampling strategy is combined with the prioritized experience replay for efficient learning on tasks with poor performance. The effectiveness and stability of our STARS are verified through experiments on the mainstream Meta-World benchmark. From the results, our STARS statistically outperforms current SOTA methods and alleviates the performance imbalance issue. Besides, we visualize the learned features to support our claims and enhance the interpretability of STARS.
VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation
May 26, 2024
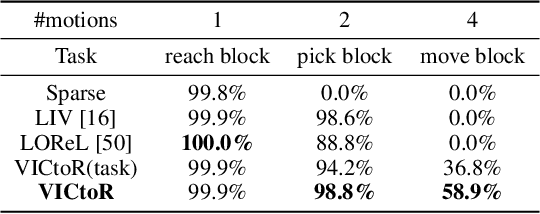
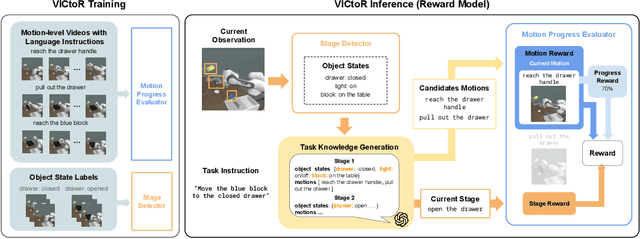
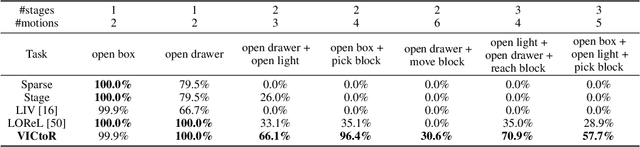
We study reward models for long-horizon manipulation tasks by learning from action-free videos and language instructions, which we term the visual-instruction correlation (VIC) problem. Recent advancements in cross-modality modeling have highlighted the potential of reward modeling through visual and language correlations. However, existing VIC methods face challenges in learning rewards for long-horizon tasks due to their lack of sub-stage awareness, difficulty in modeling task complexities, and inadequate object state estimation. To address these challenges, we introduce VICtoR, a novel hierarchical VIC reward model capable of providing effective reward signals for long-horizon manipulation tasks. VICtoR precisely assesses task progress at various levels through a novel stage detector and motion progress evaluator, offering insightful guidance for agents learning the task effectively. To validate the effectiveness of VICtoR, we conducted extensive experiments in both simulated and real-world environments. The results suggest that VICtoR outperformed the best existing VIC methods, achieving a 43% improvement in success rates for long-horizon tasks.
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024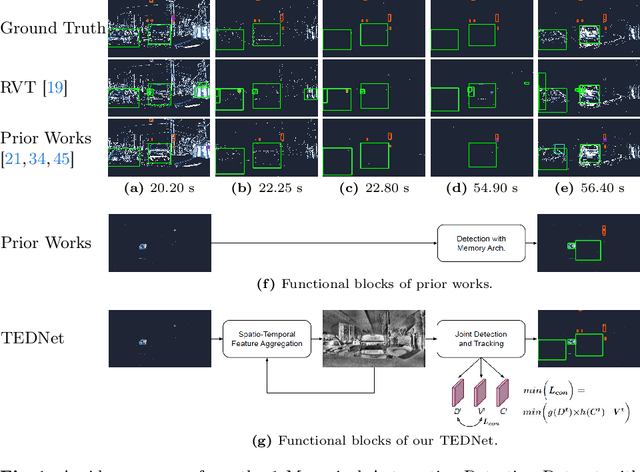

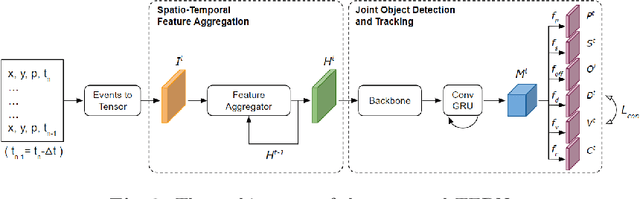

Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.