 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Replanning with Pre-explored Semantic Map for Object Navigation
Sep 07, 2024
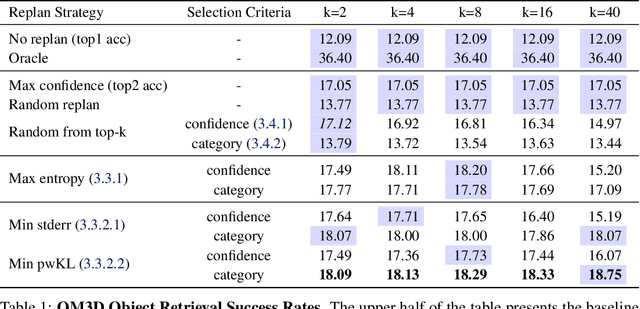
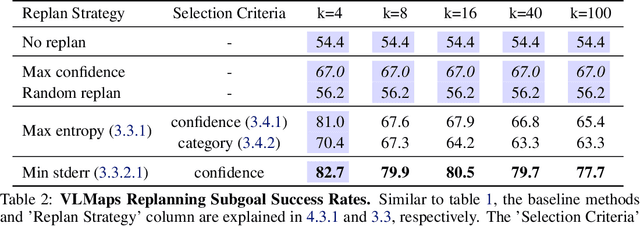
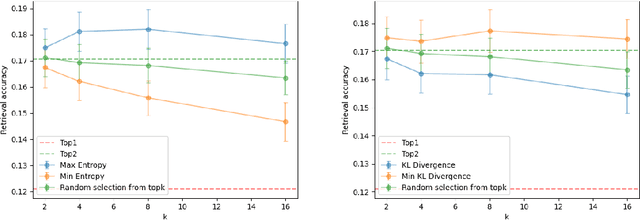
Pre-explored Semantic Maps, constructed through prior exploration using visual language models (VLMs), have proven effective as foundational elements for training-free robotic applications. However, existing approaches assume the map's accuracy and do not provide effective mechanisms for revising decisions based on incorrect maps. To address this, we introduce Context-Aware Replanning (CARe), which estimates map uncertainty through confidence scores and multi-view consistency, enabling the agent to revise erroneous decisions stemming from inaccurate maps without requiring additional labels. We demonstrate the effectiveness of our proposed method by integrating it with two modern mapping backbones, VLMaps and OpenMask3D, and observe significant performance improvements in object navigation tasks. More details can be found on the project page: https://carmaps.github.io/supplements/.
Benchmarking Cognitive Domains for LLMs: Insights from Taiwanese Hakka Culture
Sep 03, 2024This study introduces a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in understanding and processing cultural knowledge, with a specific focus on Hakka culture as a case study. Leveraging Bloom's Taxonomy, the study develops a multi-dimensional framework that systematically assesses LLMs across six cognitive domains: Remembering, Understanding, Applying, Analyzing, Evaluating, and Creating. This benchmark extends beyond traditional single-dimensional evaluations by providing a deeper analysis of LLMs' abilities to handle culturally specific content, ranging from basic recall of facts to higher-order cognitive tasks such as creative synthesis. Additionally, the study integrates Retrieval-Augmented Generation (RAG) technology to address the challenges of minority cultural knowledge representation in LLMs, demonstrating how RAG enhances the models' performance by dynamically incorporating relevant external information. The results highlight the effectiveness of RAG in improving accuracy across all cognitive domains, particularly in tasks requiring precise retrieval and application of cultural knowledge. However, the findings also reveal the limitations of RAG in creative tasks, underscoring the need for further optimization. This benchmark provides a robust tool for evaluating and comparing LLMs in culturally diverse contexts, offering valuable insights for future research and development in AI-driven cultural knowledge preservation and dissemination.