 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Robust Speech Adaptation for Cross-Domain Speech Recognition and Enhancement
Feb 04, 2026Pre-trained models for automatic speech recognition (ASR) and speech enhancement (SE) have exhibited remarkable capabilities under matched noise and channel conditions. However, these models often suffer from severe performance degradation when confronted with domain shifts, particularly in the presence of unseen noise and channel distortions. In view of this, we in this paper present URSA-GAN, a unified and domain-aware generative framework specifically designed to mitigate mismatches in both noise and channel conditions. URSA-GAN leverages a dual-embedding architecture that consists of a noise encoder and a channel encoder, each pre-trained with limited in-domain data to capture domain-relevant representations. These embeddings condition a GAN-based speech generator, facilitating the synthesis of speech that is acoustically aligned with the target domain while preserving phonetic content. To enhance generalization further, we propose dynamic stochastic perturbation, a novel regularization technique that introduces controlled variability into the embeddings during generation, promoting robustness to unseen domains. Empirical results demonstrate that URSA-GAN effectively reduces character error rates in ASR and improves perceptual metrics in SE across diverse noisy and mismatched channel scenarios. Notably, evaluations on compound test conditions with both channel and noise degradations confirm the generalization ability of URSA-GAN, yielding relative improvements of 16.16% in ASR performance and 15.58% in SE metrics.
SCENE: Semantic-aware Codec Enhancement with Neural Embeddings
Jan 29, 2026Compression artifacts from standard video codecs often degrade perceptual quality. We propose a lightweight, semantic-aware pre-processing framework that enhances perceptual fidelity by selectively addressing these distortions. Our method integrates semantic embeddings from a vision-language model into an efficient convolutional architecture, prioritizing the preservation of perceptually significant structures. The model is trained end-to-end with a differentiable codec proxy, enabling it to mitigate artifacts from various standard codecs without modifying the existing video pipeline. During inference, the codec proxy is discarded, and SCENE operates as a standalone pre-processor, enabling real-time performance. Experiments on high-resolution benchmarks show improved performance over baselines in both objective (MS-SSIM) and perceptual (VMAF) metrics, with notable gains in preserving detailed textures within salient regions. Our results show that semantic-guided, codec-aware pre-processing is an effective approach for enhancing compressed video streams.
Revealing the Role of Audio Channels in ASR Performance Degradation
Aug 12, 2025
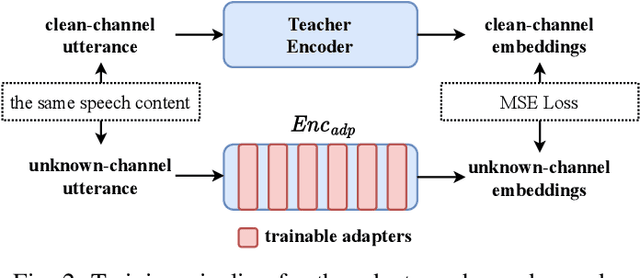


Pre-trained automatic speech recognition (ASR) models have demonstrated strong performance on a variety of tasks. However, their performance can degrade substantially when the input audio comes from different recording channels. While previous studies have demonstrated this phenomenon, it is often attributed to the mismatch between training and testing corpora. This study argues that variations in speech characteristics caused by different recording channels can fundamentally harm ASR performance. To address this limitation, we propose a normalization technique designed to mitigate the impact of channel variation by aligning internal feature representations in the ASR model with those derived from a clean reference channel. This approach significantly improves ASR performance on previously unseen channels and languages, highlighting its ability to generalize across channel and language differences.
QAMRO: Quality-aware Adaptive Margin Ranking Optimization for Human-aligned Assessment of Audio Generation Systems
Aug 12, 2025Evaluating audio generation systems, including text-to-music (TTM), text-to-speech (TTS), and text-to-audio (TTA), remains challenging due to the subjective and multi-dimensional nature of human perception. Existing methods treat mean opinion score (MOS) prediction as a regression problem, but standard regression losses overlook the relativity of perceptual judgments. To address this limitation, we introduce QAMRO, a novel Quality-aware Adaptive Margin Ranking Optimization framework that seamlessly integrates regression objectives from different perspectives, aiming to highlight perceptual differences and prioritize accurate ratings. Our framework leverages pre-trained audio-text models such as CLAP and Audiobox-Aesthetics, and is trained exclusively on the official AudioMOS Challenge 2025 dataset. It demonstrates superior alignment with human evaluations across all dimensions, significantly outperforming robust baseline models.
Enhancing Low-Resource Minority Language Translation with LLMs and Retrieval-Augmented Generation for Cultural Nuances
May 16, 2025This study investigates the challenges of translating low-resource languages by integrating Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG). Various model configurations were tested on Hakka translations, with BLEU scores ranging from 12% (dictionary-only) to 31% (RAG with Gemini 2.0). The best-performing model (Model 4) combined retrieval and advanced language modeling, improving lexical coverage, particularly for specialized or culturally nuanced terms, and enhancing grammatical coherence. A two-stage method (Model 3) using dictionary outputs refined by Gemini 2.0 achieved a BLEU score of 26%, highlighting iterative correction's value and the challenges of domain-specific expressions. Static dictionary-based approaches struggled with context-sensitive content, demonstrating the limitations of relying solely on predefined resources. These results emphasize the need for curated resources, domain knowledge, and ethical collaboration with local communities, offering a framework that improves translation accuracy and fluency while supporting cultural preservation.
Leveraging Retrieval-Augmented Generation for Culturally Inclusive Hakka Chatbots: Design Insights and User Perceptions
Oct 21, 2024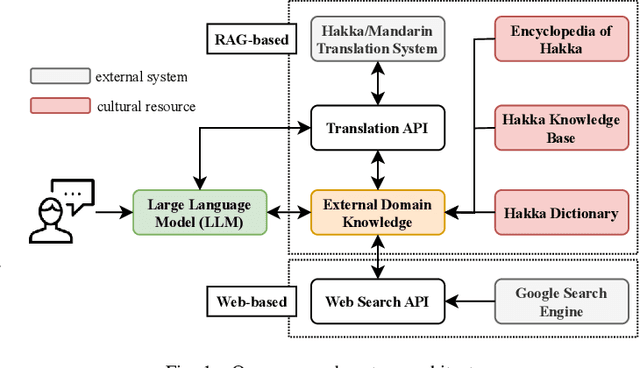
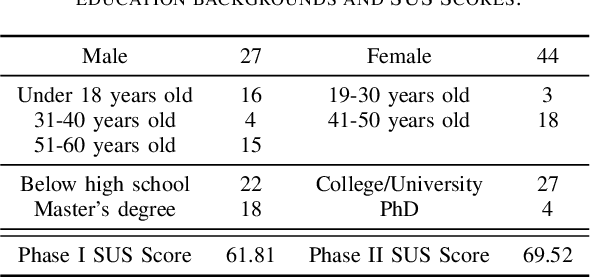
In an era where cultural preservation is increasingly intertwined with technological innovation, this study introduces a groundbreaking approach to promoting and safeguarding the rich heritage of Taiwanese Hakka culture through the development of a Retrieval-Augmented Generation (RAG)-enhanced chatbot. Traditional large language models (LLMs), while powerful, often fall short in delivering accurate and contextually rich responses, particularly in culturally specific domains. By integrating external databases with generative AI models, RAG technology bridges this gap, empowering chatbots to not only provide precise answers but also resonate deeply with the cultural nuances that are crucial for authentic interactions. This study delves into the intricate process of augmenting the chatbot's knowledge base with targeted cultural data, specifically curated to reflect the unique aspects of Hakka traditions, language, and practices. Through dynamic information retrieval, the RAG-enhanced chatbot becomes a versatile tool capable of handling complex inquiries that demand an in-depth understanding of Hakka cultural context. This is particularly significant in an age where digital platforms often dilute cultural identities, making the role of culturally aware AI systems more critical than ever. System usability studies conducted as part of our research reveal a marked improvement in both user satisfaction and engagement, highlighting the chatbot's effectiveness in fostering a deeper connection with Hakka culture. The feedback underscores the potential of RAG technology to not only enhance user experience but also to serve as a vital instrument in the broader mission of ethnic mainstreaming and cultural celebration.
Exploring the Impact of Data Quantity on ASR in Extremely Low-resource Languages
Sep 13, 2024This study investigates the efficacy of data augmentation techniques for low-resource automatic speech recognition (ASR), focusing on two endangered Austronesian languages, Amis and Seediq. Recognizing the potential of self-supervised learning (SSL) in low-resource settings, we explore the impact of data volume on the continued pre-training of SSL models. We propose a novel data-selection scheme leveraging a multilingual corpus to augment the limited target language data. This scheme utilizes a language classifier to extract utterance embeddings and employs one-class classifiers to identify utterances phonetically and phonologically proximate to the target languages. Utterances are ranked and selected based on their decision scores, ensuring the inclusion of highly relevant data in the SSL-ASR pipeline. Our experimental results demonstrate the effectiveness of this approach, yielding substantial improvements in ASR performance for both Amis and Seediq. These findings underscore the feasibility and promise of data augmentation through cross-lingual transfer learning for low-resource language ASR.
VoxHakka: A Dialectally Diverse Multi-speaker Text-to-Speech System for Taiwanese Hakka
Sep 03, 2024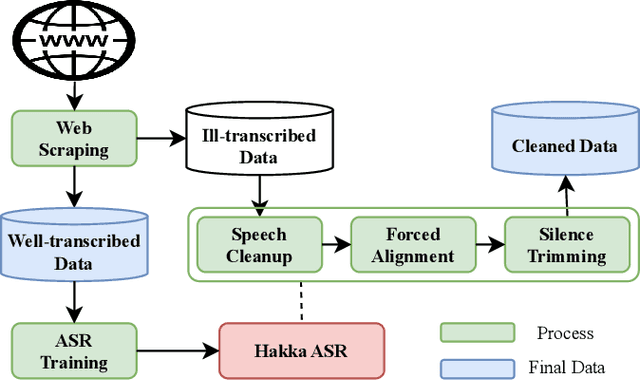
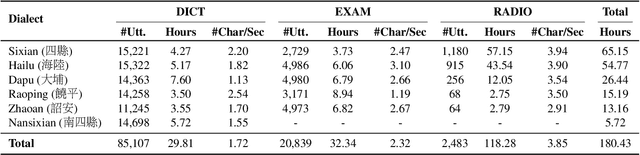
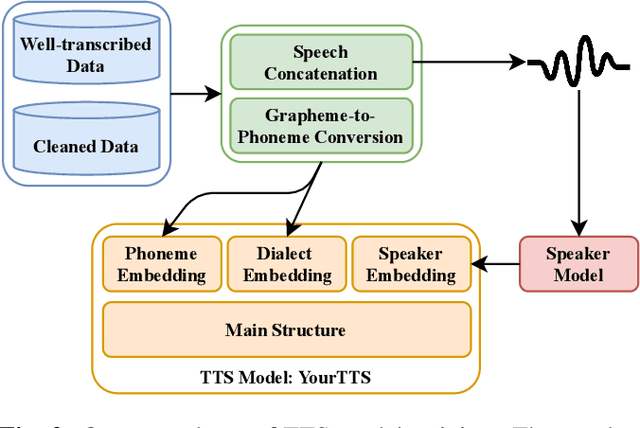
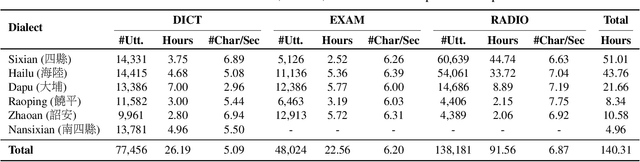
This paper introduces VoxHakka, a text-to-speech (TTS) system designed for Taiwanese Hakka, a critically under-resourced language spoken in Taiwan. Leveraging the YourTTS framework, VoxHakka achieves high naturalness and accuracy and low real-time factor in speech synthesis while supporting six distinct Hakka dialects. This is achieved by training the model with dialect-specific data, allowing for the generation of speaker-aware Hakka speech. To address the scarcity of publicly available Hakka speech corpora, we employed a cost-effective approach utilizing a web scraping pipeline coupled with automatic speech recognition (ASR)-based data cleaning techniques. This process ensured the acquisition of a high-quality, multi-speaker, multi-dialect dataset suitable for TTS training. Subjective listening tests conducted using comparative mean opinion scores (CMOS) demonstrate that VoxHakka significantly outperforms existing publicly available Hakka TTS systems in terms of pronunciation accuracy, tone correctness, and overall naturalness. This work represents a significant advancement in Hakka language technology and provides a valuable resource for language preservation and revitalization efforts.
Benchmarking Cognitive Domains for LLMs: Insights from Taiwanese Hakka Culture
Sep 03, 2024This study introduces a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in understanding and processing cultural knowledge, with a specific focus on Hakka culture as a case study. Leveraging Bloom's Taxonomy, the study develops a multi-dimensional framework that systematically assesses LLMs across six cognitive domains: Remembering, Understanding, Applying, Analyzing, Evaluating, and Creating. This benchmark extends beyond traditional single-dimensional evaluations by providing a deeper analysis of LLMs' abilities to handle culturally specific content, ranging from basic recall of facts to higher-order cognitive tasks such as creative synthesis. Additionally, the study integrates Retrieval-Augmented Generation (RAG) technology to address the challenges of minority cultural knowledge representation in LLMs, demonstrating how RAG enhances the models' performance by dynamically incorporating relevant external information. The results highlight the effectiveness of RAG in improving accuracy across all cognitive domains, particularly in tasks requiring precise retrieval and application of cultural knowledge. However, the findings also reveal the limitations of RAG in creative tasks, underscoring the need for further optimization. This benchmark provides a robust tool for evaluating and comparing LLMs in culturally diverse contexts, offering valuable insights for future research and development in AI-driven cultural knowledge preservation and dissemination.
Effective Noise-aware Data Simulation for Domain-adaptive Speech Enhancement Leveraging Dynamic Stochastic Perturbation
Sep 03, 2024Cross-domain speech enhancement (SE) is often faced with severe challenges due to the scarcity of noise and background information in an unseen target domain, leading to a mismatch between training and test conditions. This study puts forward a novel data simulation method to address this issue, leveraging noise-extractive techniques and generative adversarial networks (GANs) with only limited target noisy speech data. Notably, our method employs a noise encoder to extract noise embeddings from target-domain data. These embeddings aptly guide the generator to synthesize utterances acoustically fitted to the target domain while authentically preserving the phonetic content of the input clean speech. Furthermore, we introduce the notion of dynamic stochastic perturbation, which can inject controlled perturbations into the noise embeddings during inference, thereby enabling the model to generalize well to unseen noise conditions. Experiments on the VoiceBank-DEMAND benchmark dataset demonstrate that our domain-adaptive SE method outperforms an existing strong baseline based on data simulation.