 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxHakka: A Dialectally Diverse Multi-speaker Text-to-Speech System for Taiwanese Hakka
Paper and Code
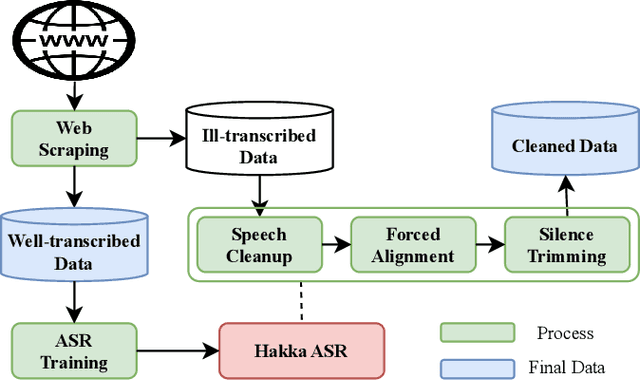
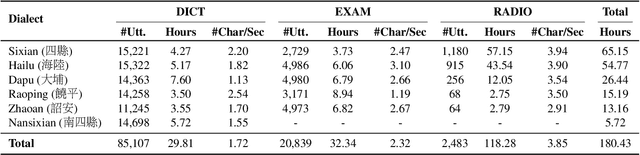
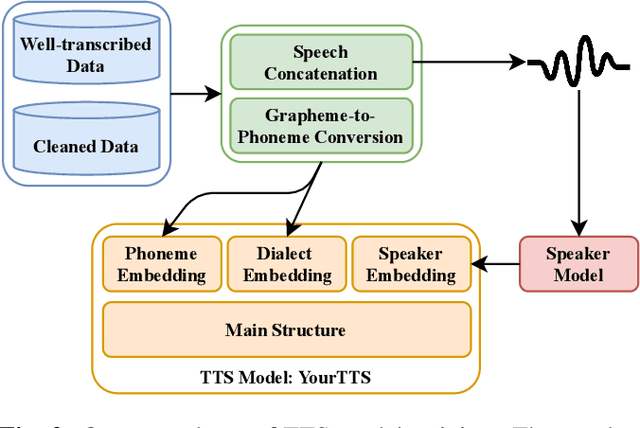
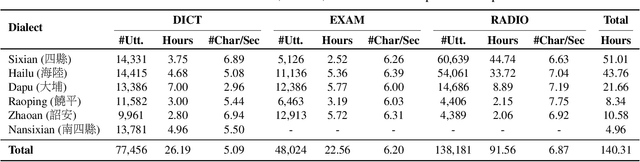
This paper introduces VoxHakka, a text-to-speech (TTS) system designed for Taiwanese Hakka, a critically under-resourced language spoken in Taiwan. Leveraging the YourTTS framework, VoxHakka achieves high naturalness and accuracy and low real-time factor in speech synthesis while supporting six distinct Hakka dialects. This is achieved by training the model with dialect-specific data, allowing for the generation of speaker-aware Hakka speech. To address the scarcity of publicly available Hakka speech corpora, we employed a cost-effective approach utilizing a web scraping pipeline coupled with automatic speech recognition (ASR)-based data cleaning techniques. This process ensured the acquisition of a high-quality, multi-speaker, multi-dialect dataset suitable for TTS training. Subjective listening tests conducted using comparative mean opinion scores (CMOS) demonstrate that VoxHakka significantly outperforms existing publicly available Hakka TTS systems in terms of pronunciation accuracy, tone correctness, and overall naturalness. This work represents a significant advancement in Hakka language technology and provides a valuable resource for language preservation and revitalization efforts.