 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Speaker Representations Using Heterogeneous Training Batch Assembly
Mar 30, 2022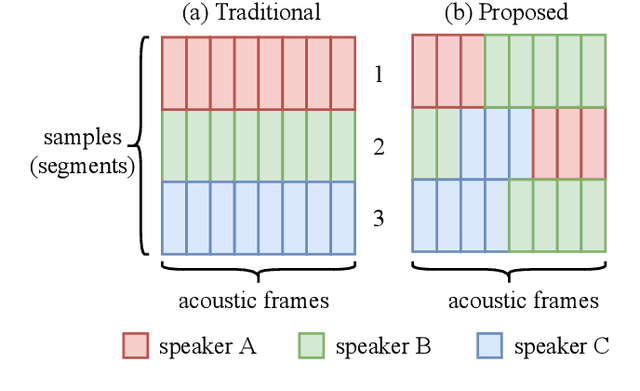
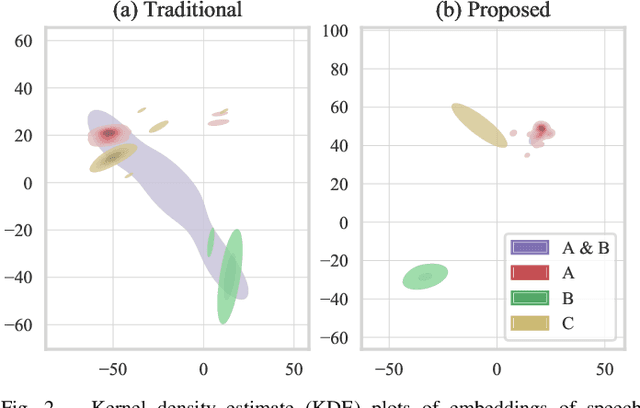
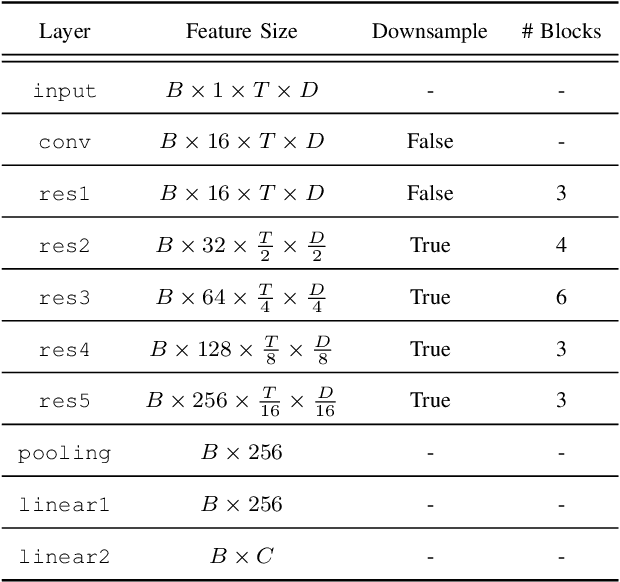
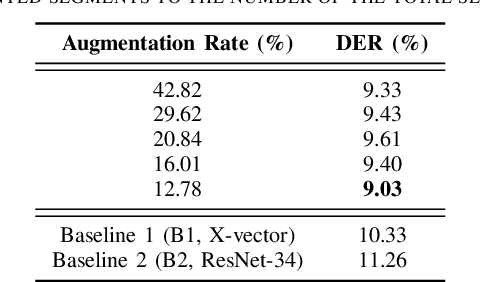
In traditional speaker diarization systems, a well-trained speaker model is a key component to extract representations from consecutive and partially overlapping segments in a long speech session. To be more consistent with the back-end segmentation and clustering, we propose a new CNN-based speaker modeling scheme, which takes into account the heterogeneity of the speakers in each training segment and batch. We randomly and synthetically augment the training data into a set of segments, each of which contains more than one speaker and some overlapping parts. A soft label is imposed on each segment based on its speaker occupation ratio, and the standard cross entropy loss is implemented in model training. In this way, the speaker model should have the ability to generate a geometrically meaningful embedding for each multi-speaker segment. Experimental results show that our system is superior to the baseline system using x-vectors in two speaker diarization tasks. In the CALLHOME task trained on the NIST SRE and Switchboard datasets, our system achieves a relative reduction of 12.93% in DER. In Track 2 of CHiME-6, our system provides 13.24%, 12.60%, and 5.65% relative reductions in DER, JER, and WER, respectively.
Time Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021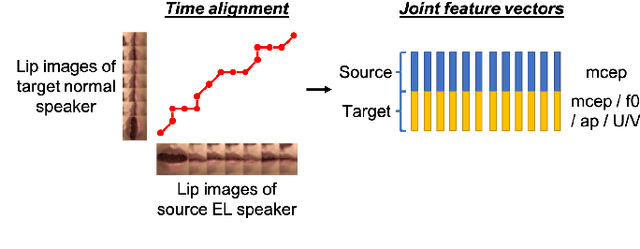
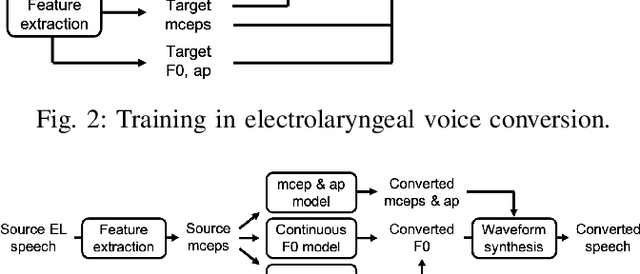
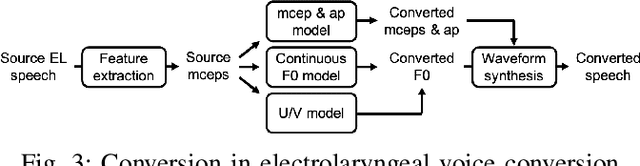
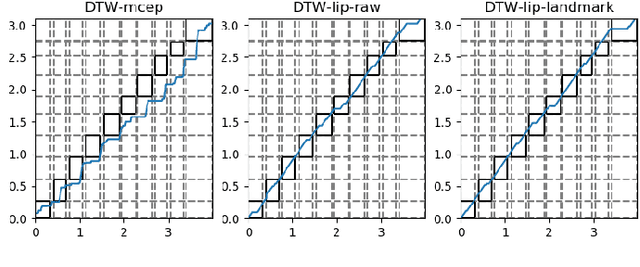
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021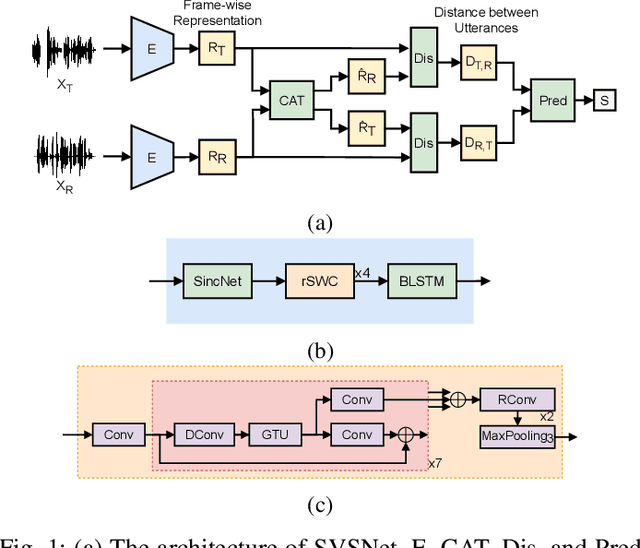



Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
Dual-Path Filter Network: Speaker-Aware Modeling for Speech Separation
Jun 14, 2021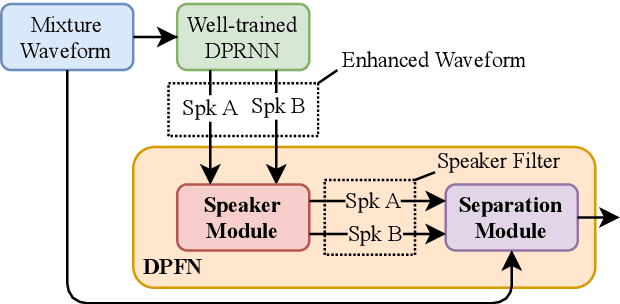



Speech separation has been extensively studied to deal with the cocktail party problem in recent years. All related approaches can be divided into two categories: time-frequency domain methods and time domain methods. In addition, some methods try to generate speaker vectors to support source separation. In this study, we propose a new model called dual-path filter network (DPFN). Our model focuses on the post-processing of speech separation to improve speech separation performance. DPFN is composed of two parts: the speaker module and the separation module. First, the speaker module infers the identities of the speakers. Then, the separation module uses the speakers' information to extract the voices of individual speakers from the mixture. DPFN constructed based on DPRNN-TasNet is not only superior to DPRNN-TasNet, but also avoids the problem of permutation-invariant training (PIT).
Relational Data Selection for Data Augmentation of Speaker-dependent Multi-band MelGAN Vocoder
Jun 10, 2021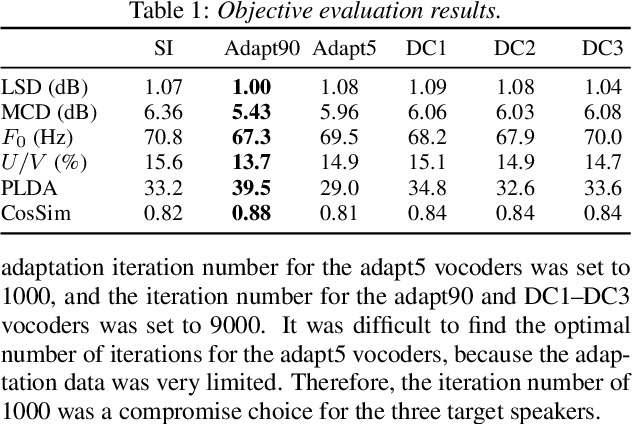
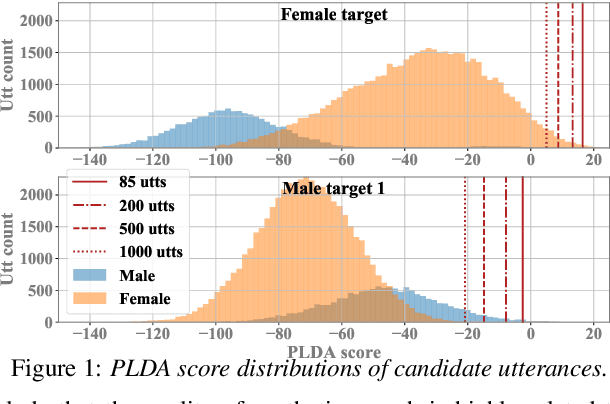
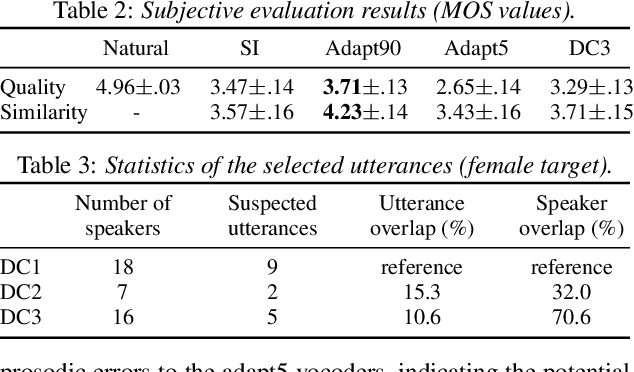
Nowadays, neural vocoders can generate very high-fidelity speech when a bunch of training data is available. Although a speaker-dependent (SD) vocoder usually outperforms a speaker-independent (SI) vocoder, it is impractical to collect a large amount of data of a specific target speaker for most real-world applications. To tackle the problem of limited target data, a data augmentation method based on speaker representation and similarity measurement of speaker verification is proposed in this paper. The proposed method selects utterances that have similar speaker identity to the target speaker from an external corpus, and then combines the selected utterances with the limited target data for SD vocoder adaptation. The evaluation results show that, compared with the vocoder adapted using only limited target data, the vocoder adapted using augmented data improves both the quality and similarity of synthesized speech.
A Preliminary Study of a Two-Stage Paradigm for Preserving Speaker Identity in Dysarthric Voice Conversion
Jun 02, 2021


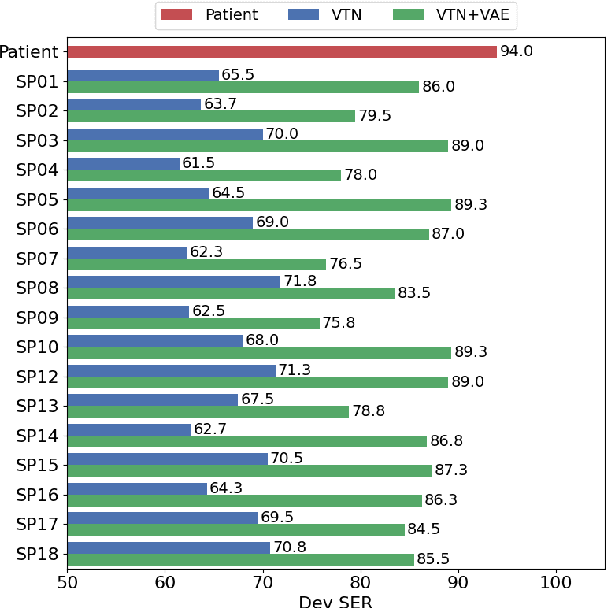
We propose a new paradigm for maintaining speaker identity in dysarthric voice conversion (DVC). The poor quality of dysarthric speech can be greatly improved by statistical VC, but as the normal speech utterances of a dysarthria patient are nearly impossible to collect, previous work failed to recover the individuality of the patient. In light of this, we suggest a novel, two-stage approach for DVC, which is highly flexible in that no normal speech of the patient is required. First, a powerful parallel sequence-to-sequence model converts the input dysarthric speech into a normal speech of a reference speaker as an intermediate product, and a nonparallel, frame-wise VC model realized with a variational autoencoder then converts the speaker identity of the reference speech back to that of the patient while assumed to be capable of preserving the enhanced quality. We investigate several design options. Experimental evaluation results demonstrate the potential of our approach to improving the quality of the dysarthric speech while maintaining the speaker identity.
The AS-NU System for the M2VoC Challenge
Apr 07, 2021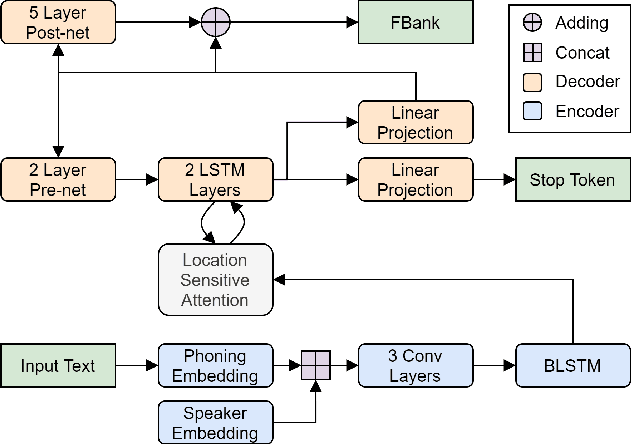
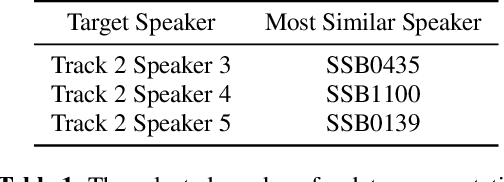
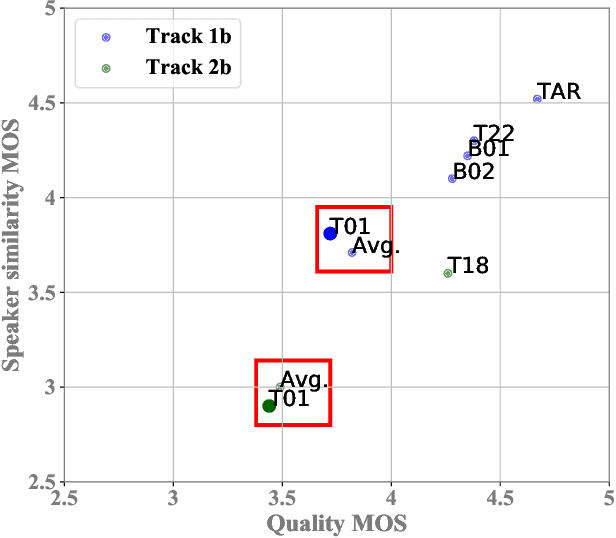
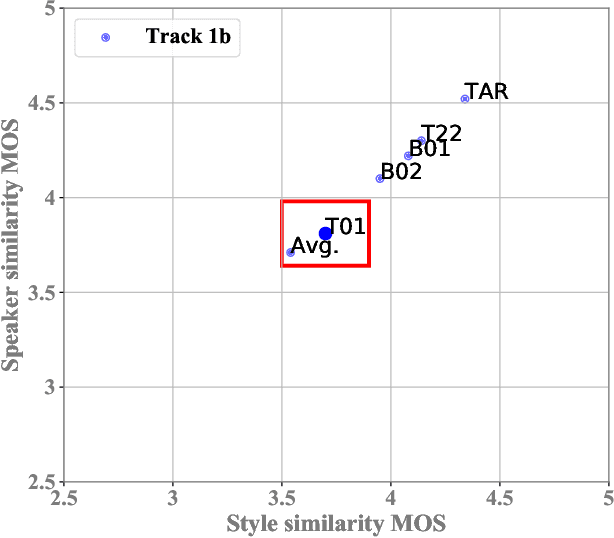
This paper describes the AS-NU systems for two tracks in MultiSpeaker Multi-Style Voice Cloning Challenge (M2VoC). The first track focuses on using a small number of 100 target utterances for voice cloning, while the second track focuses on using only 5 target utterances for voice cloning. Due to the serious lack of data in the second track, we selected the speaker most similar to the target speaker from the training data of the TTS system, and used the speaker's utterances and the given 5 target utterances to fine-tune our model. The evaluation results show that our systems on the two tracks perform similarly in terms of quality, but there is still a clear gap between the similarity score of the second track and the similarity score of the first track.
Unsupervised Representation Disentanglement using Cross Domain Features and Adversarial Learning in Variational Autoencoder based Voice Conversion
Feb 07, 2020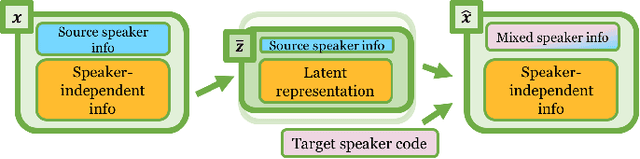
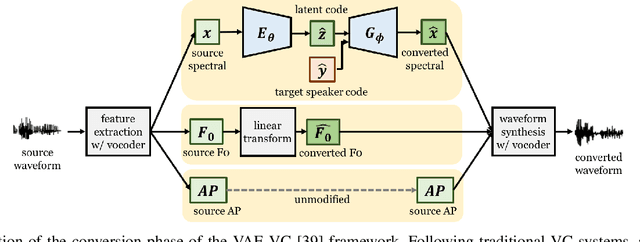
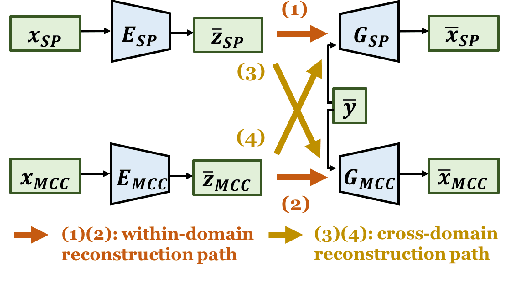

An effective approach for voice conversion (VC) is to disentangle linguistic content from other components in the speech signal. The effectiveness of variational autoencoder (VAE) based VC (VAE-VC), for instance, strongly relies on this principle. In our prior work, we proposed a cross-domain VAE-VC (CDVAE-VC) framework, which utilized acoustic features of different properties, to improve the performance of VAE-VC. We believed that the success came from more disentangled latent representations. In this paper, we extend the CDVAE-VC framework by incorporating the concept of adversarial learning, in order to further increase the degree of disentanglement, thereby improving the quality and similarity of converted speech. More specifically, we first investigate the effectiveness of incorporating the generative adversarial networks (GANs) with CDVAE-VC. Then, we consider the concept of domain adversarial training and add an explicit constraint to the latent representation, realized by a speaker classifier, to explicitly eliminate the speaker information that resides in the latent code. Experimental results confirm that the degree of disentanglement of the learned latent representation can be enhanced by both GANs and the speaker classifier. Meanwhile, subjective evaluation results in terms of quality and similarity scores demonstrate the effectiveness of our proposed methods.
Voice Conversion Based on Cross-Domain Features Using Variational Auto Encoders
Aug 29, 2018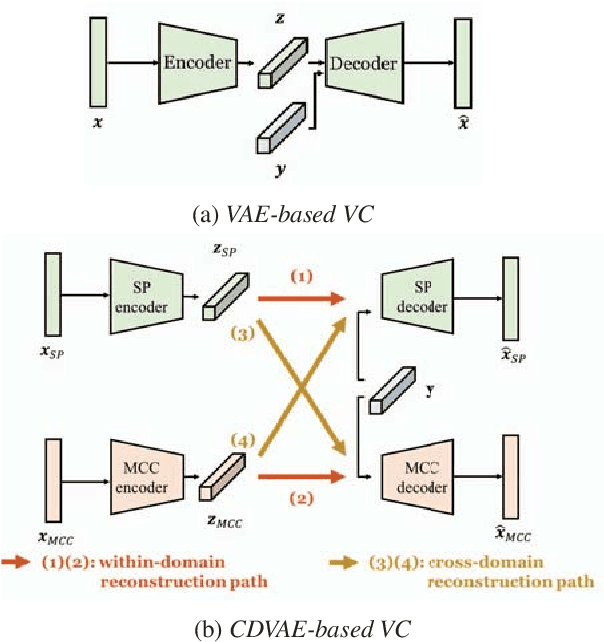



An effective approach to non-parallel voice conversion (VC) is to utilize deep neural networks (DNNs), specifically variational auto encoders (VAEs), to model the latent structure of speech in an unsupervised manner. A previous study has confirmed the ef- fectiveness of VAE using the STRAIGHT spectra for VC. How- ever, VAE using other types of spectral features such as mel- cepstral coefficients (MCCs), which are related to human per- ception and have been widely used in VC, have not been prop- erly investigated. Instead of using one specific type of spectral feature, it is expected that VAE may benefit from using multi- ple types of spectral features simultaneously, thereby improving the capability of VAE for VC. To this end, we propose a novel VAE framework (called cross-domain VAE, CDVAE) for VC. Specifically, the proposed framework utilizes both STRAIGHT spectra and MCCs by explicitly regularizing multiple objectives in order to constrain the behavior of the learned encoder and de- coder. Experimental results demonstrate that the proposed CD- VAE framework outperforms the conventional VAE framework in terms of subjective tests.