 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Conversion Based on Cross-Domain Features Using Variational Auto Encoders
Paper and Code
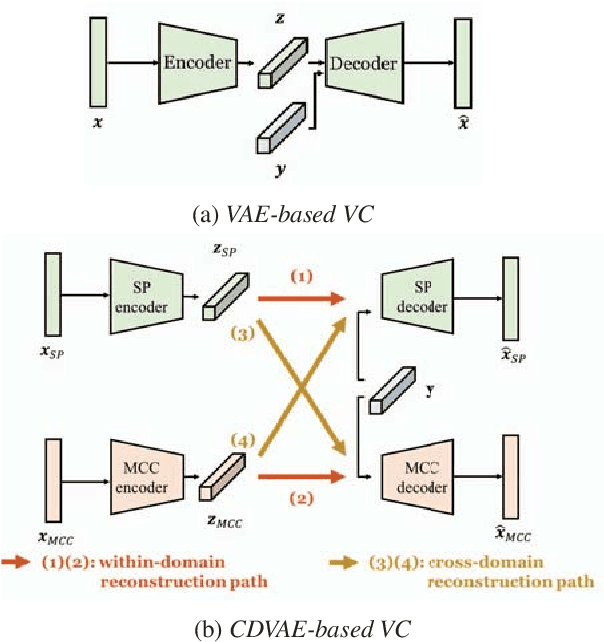



An effective approach to non-parallel voice conversion (VC) is to utilize deep neural networks (DNNs), specifically variational auto encoders (VAEs), to model the latent structure of speech in an unsupervised manner. A previous study has confirmed the ef- fectiveness of VAE using the STRAIGHT spectra for VC. How- ever, VAE using other types of spectral features such as mel- cepstral coefficients (MCCs), which are related to human per- ception and have been widely used in VC, have not been prop- erly investigated. Instead of using one specific type of spectral feature, it is expected that VAE may benefit from using multi- ple types of spectral features simultaneously, thereby improving the capability of VAE for VC. To this end, we propose a novel VAE framework (called cross-domain VAE, CDVAE) for VC. Specifically, the proposed framework utilizes both STRAIGHT spectra and MCCs by explicitly regularizing multiple objectives in order to constrain the behavior of the learned encoder and de- coder. Experimental results demonstrate that the proposed CD- VAE framework outperforms the conventional VAE framework in terms of subjective tests.