 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Representation Disentanglement using Cross Domain Features and Adversarial Learning in Variational Autoencoder based Voice Conversion
Feb 07, 2020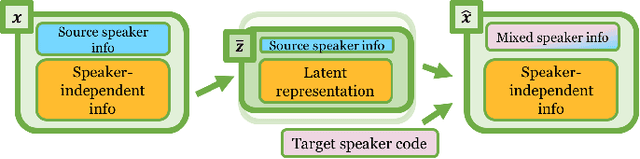

An effective approach for voice conversion (VC) is to disentangle linguistic content from other components in the speech signal. The effectiveness of variational autoencoder (VAE) based VC (VAE-VC), for instance, strongly relies on this principle. In our prior work, we proposed a cross-domain VAE-VC (CDVAE-VC) framework, which utilized acoustic features of different properties, to improve the performance of VAE-VC. We believed that the success came from more disentangled latent representations. In this paper, we extend the CDVAE-VC framework by incorporating the concept of adversarial learning, in order to further increase the degree of disentanglement, thereby improving the quality and similarity of converted speech. More specifically, we first investigate the effectiveness of incorporating the generative adversarial networks (GANs) with CDVAE-VC. Then, we consider the concept of domain adversarial training and add an explicit constraint to the latent representation, realized by a speaker classifier, to explicitly eliminate the speaker information that resides in the latent code. Experimental results confirm that the degree of disentanglement of the learned latent representation can be enhanced by both GANs and the speaker classifier. Meanwhile, subjective evaluation results in terms of quality and similarity scores demonstrate the effectiveness of our proposed methods.
Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion
Nov 27, 2018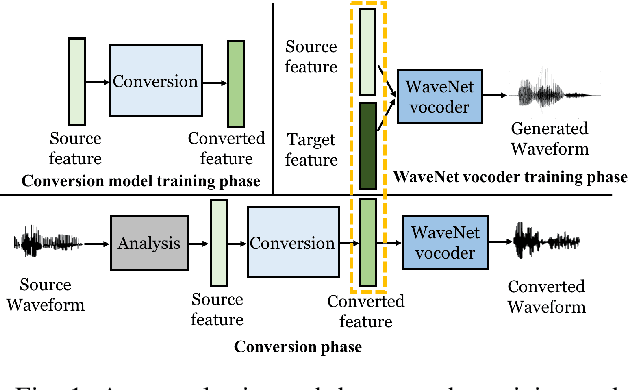
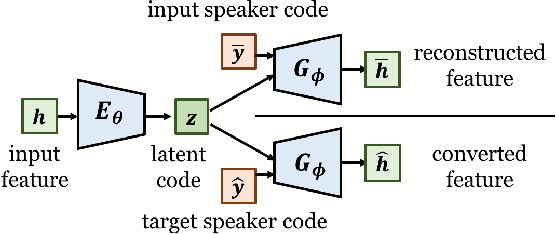
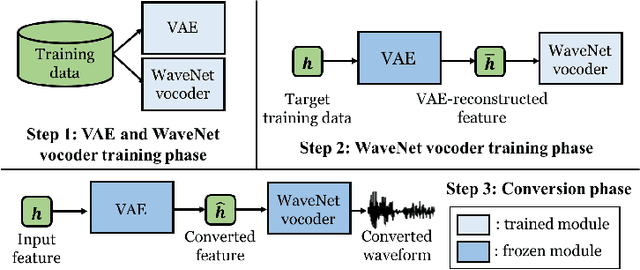
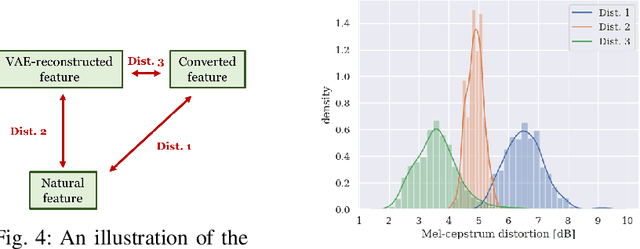
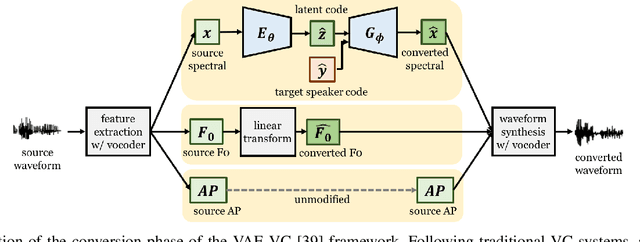
This paper presents a refinement framework of WaveNet vocoders for variational autoencoder (VAE) based voice conversion (VC), which reduces the quality distortion caused by the mismatch between the training data and testing data. Conventional WaveNet vocoders are trained with natural acoustic features but condition on the converted features in the conversion stage for VC, and such mismatch often causes significant quality and similarity degradation. In this work, we take advantage of the particular structure of VAEs to refine WaveNet vocoders with the self-reconstructed features generated by VAE, which are of similar characteristics with the converted features while having the same data length with the target training data. In other words, our proposed method does not require any alignment. Objective and subjective experimental results demonstrate the effectiveness of our proposed framework.
Voice Conversion Based on Cross-Domain Features Using Variational Auto Encoders
Aug 29, 2018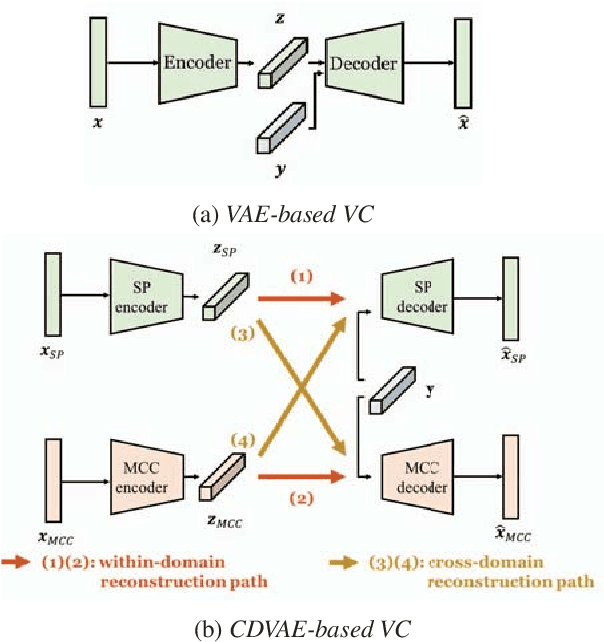



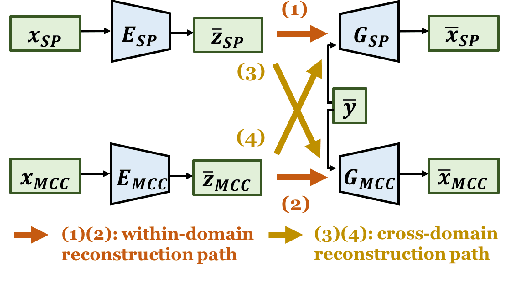
An effective approach to non-parallel voice conversion (VC) is to utilize deep neural networks (DNNs), specifically variational auto encoders (VAEs), to model the latent structure of speech in an unsupervised manner. A previous study has confirmed the ef- fectiveness of VAE using the STRAIGHT spectra for VC. How- ever, VAE using other types of spectral features such as mel- cepstral coefficients (MCCs), which are related to human per- ception and have been widely used in VC, have not been prop- erly investigated. Instead of using one specific type of spectral feature, it is expected that VAE may benefit from using multi- ple types of spectral features simultaneously, thereby improving the capability of VAE for VC. To this end, we propose a novel VAE framework (called cross-domain VAE, CDVAE) for VC. Specifically, the proposed framework utilizes both STRAIGHT spectra and MCCs by explicitly regularizing multiple objectives in order to constrain the behavior of the learned encoder and de- coder. Experimental results demonstrate that the proposed CD- VAE framework outperforms the conventional VAE framework in terms of subjective tests.
Quality-Net: An End-to-End Non-intrusive Speech Quality Assessment Model based on BLSTM
Aug 17, 2018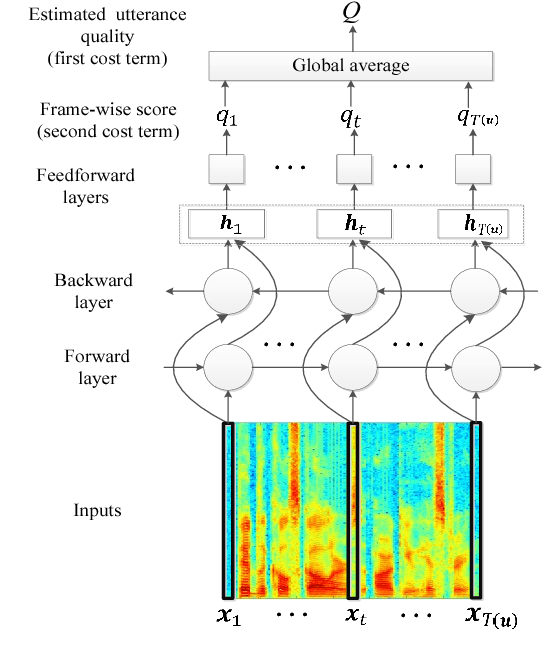

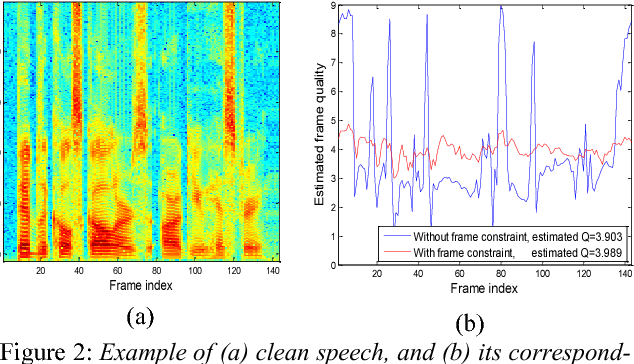
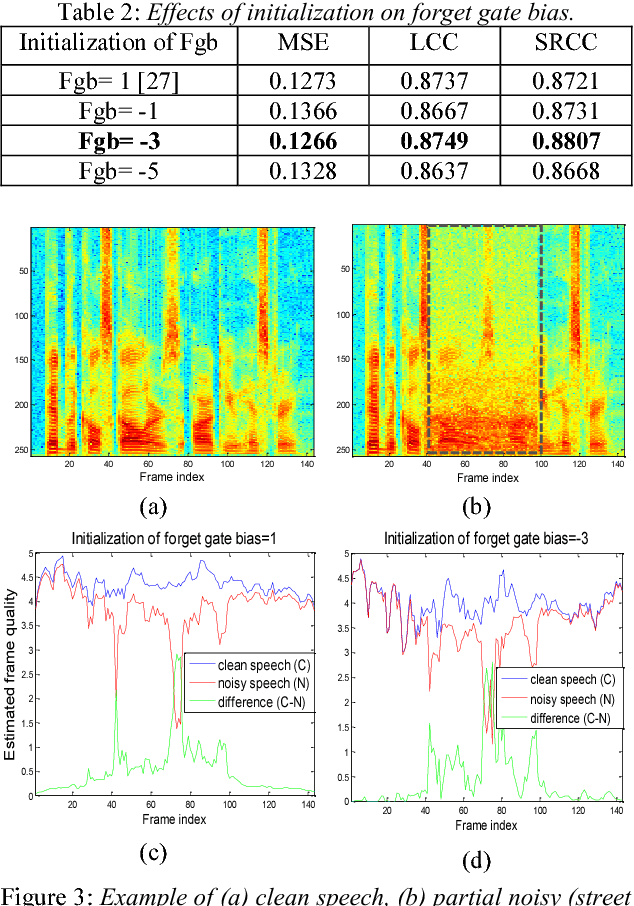
Nowadays, most of the objective speech quality assessment tools (e.g., perceptual evaluation of speech quality (PESQ)) are based on the comparison of the degraded/processed speech with its clean counterpart. The need of a "golden" reference considerably restricts the practicality of such assessment tools in real-world scenarios since the clean reference usually cannot be accessed. On the other hand, human beings can readily evaluate the speech quality without any reference (e.g., mean opinion score (MOS) tests), implying the existence of an objective and non-intrusive (no clean reference needed) quality assessment mechanism. In this study, we propose a novel end-to-end, non-intrusive speech quality evaluation model, termed Quality-Net, based on bidirectional long short-term memory. The evaluation of utterance-level quality in Quality-Net is based on the frame-level assessment. Frame constraints and sensible initializations of forget gate biases are applied to learn meaningful frame-level quality assessment from the utterance-level quality label. Experimental results show that Quality-Net can yield high correlation to PESQ (0.9 for the noisy speech and 0.84 for the speech processed by speech enhancement). We believe that Quality-Net has potential to be used in a wide variety of applications of speech signal processing.
Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks
Jun 08, 2017
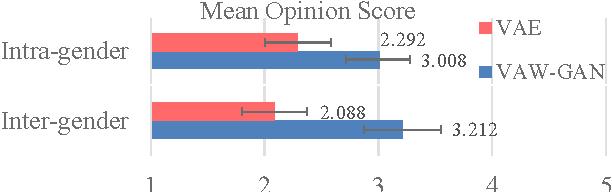

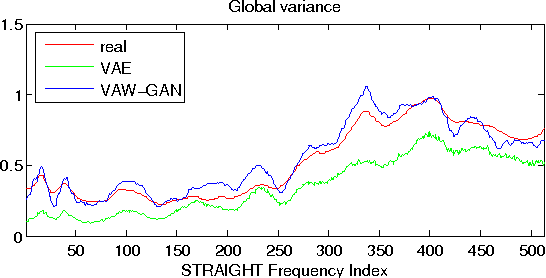
Building a voice conversion (VC) system from non-parallel speech corpora is challenging but highly valuable in real application scenarios. In most situations, the source and the target speakers do not repeat the same texts or they may even speak different languages. In this case, one possible, although indirect, solution is to build a generative model for speech. Generative models focus on explaining the observations with latent variables instead of learning a pairwise transformation function, thereby bypassing the requirement of speech frame alignment. In this paper, we propose a non-parallel VC framework with a variational autoencoding Wasserstein generative adversarial network (VAW-GAN) that explicitly considers a VC objective when building the speech model. Experimental results corroborate the capability of our framework for building a VC system from unaligned data, and demonstrate improved conversion quality.
Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder
Oct 13, 2016

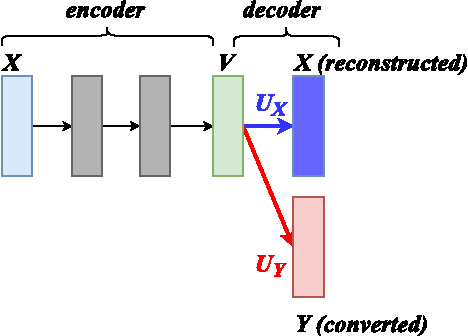
We propose a flexible framework for spectral conversion (SC) that facilitates training with unaligned corpora. Many SC frameworks require parallel corpora, phonetic alignments, or explicit frame-wise correspondence for learning conversion functions or for synthesizing a target spectrum with the aid of alignments. However, these requirements gravely limit the scope of practical applications of SC due to scarcity or even unavailability of parallel corpora. We propose an SC framework based on variational auto-encoder which enables us to exploit non-parallel corpora. The framework comprises an encoder that learns speaker-independent phonetic representations and a decoder that learns to reconstruct the designated speaker. It removes the requirement of parallel corpora or phonetic alignments to train a spectral conversion system. We report objective and subjective evaluations to validate our proposed method and compare it to SC methods that have access to aligned corpora.
Dictionary Update for NMF-based Voice Conversion Using an Encoder-Decoder Network
Oct 13, 2016
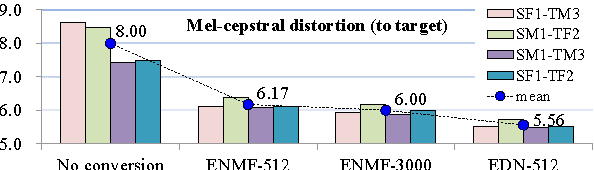
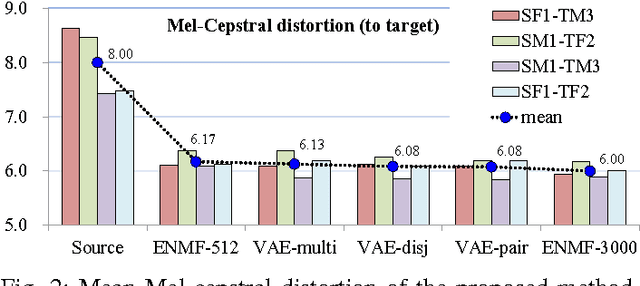
In this paper, we propose a dictionary update method for Nonnegative Matrix Factorization (NMF) with high dimensional data in a spectral conversion (SC) task. Voice conversion has been widely studied due to its potential applications such as personalized speech synthesis and speech enhancement. Exemplar-based NMF (ENMF) emerges as an effective and probably the simplest choice among all techniques for SC, as long as a source-target parallel speech corpus is given. ENMF-based SC systems usually need a large amount of bases (exemplars) to ensure the quality of the converted speech. However, a small and effective dictionary is desirable but hard to obtain via dictionary update, in particular when high-dimensional features such as STRAIGHT spectra are used. Therefore, we propose a dictionary update framework for NMF by means of an encoder-decoder reformulation. Regarding NMF as an encoder-decoder network makes it possible to exploit the whole parallel corpus more effectively and efficiently when applied to SC. Our experiments demonstrate significant gains of the proposed system with small dictionaries over conventional ENMF-based systems with dictionaries of same or much larger size.