 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Machine Dubbing Through Phrase-level Cross-lingual Prosody Transfer
Jun 21, 2023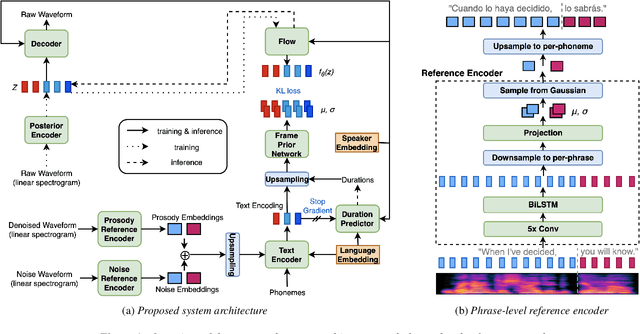
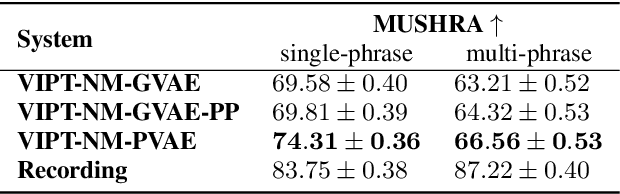
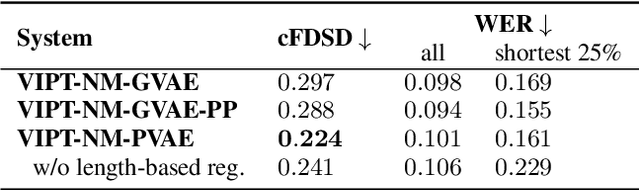
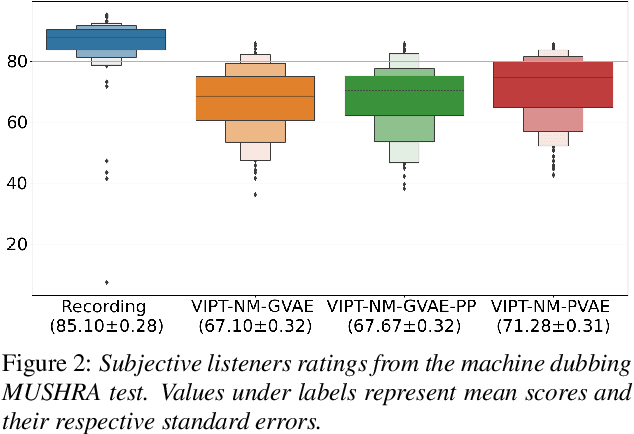
Speech generation for machine dubbing adds complexity to conventional Text-To-Speech solutions as the generated output is required to match the expressiveness, emotion and speaking rate of the source content. Capturing and transferring details and variations in prosody is a challenge. We introduce phrase-level cross-lingual prosody transfer for expressive multi-lingual machine dubbing. The proposed phrase-level prosody transfer delivers a significant 6.2% MUSHRA score increase over a baseline with utterance-level global prosody transfer, thereby closing the gap between the baseline and expressive human dubbing by 23.2%, while preserving intelligibility of the synthesised speech.
Cross-lingual Prosody Transfer for Expressive Machine Dubbing
Jun 20, 2023



Prosody transfer is well-studied in the context of expressive speech synthesis. Cross-lingual prosody transfer, however, is challenging and has been under-explored to date. In this paper, we present a novel solution to learn prosody representations that are transferable across languages and speakers for machine dubbing of expressive multimedia contents. Multimedia contents often contain field recordings. To enable prosody transfer from noisy audios, we introduce a novel noise modelling module that disentangles noise conditioning from prosody conditioning, and thereby gains independent control of noise levels in the synthesised speech. We augment noisy training data with clean data to improve the ability of the model to map the denoised reference audio to clean speech. Our proposed system can generate speech with context-matching prosody and closes the gap between a strong baseline and human expressive dialogs by 11.2%.
A Cyclical Approach to Synthetic and Natural Speech Mismatch Refinement of Neural Post-filter for Low-cost Text-to-speech System
Jul 13, 2022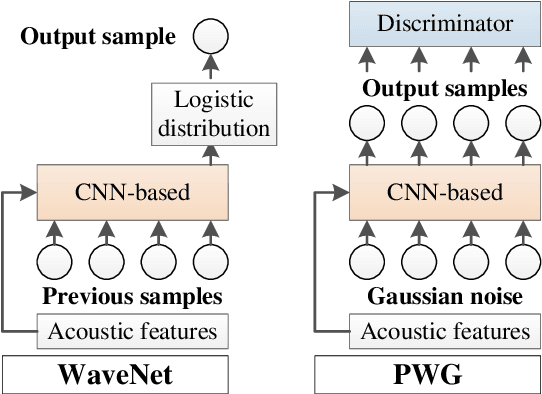
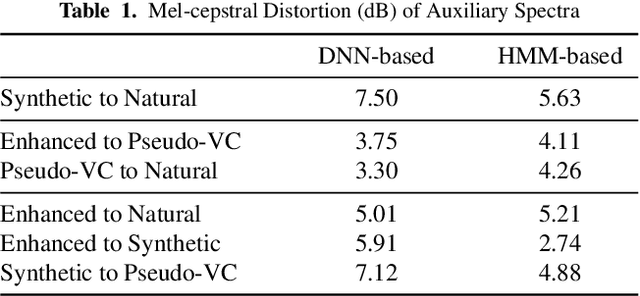
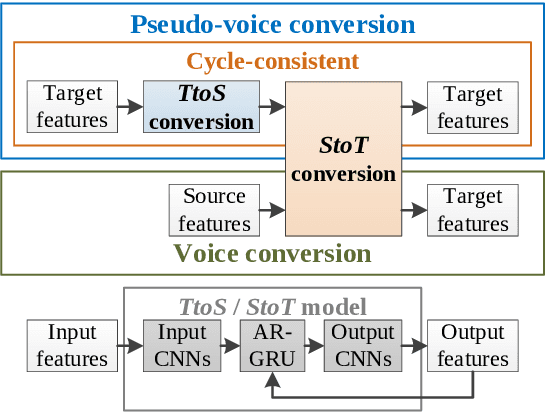
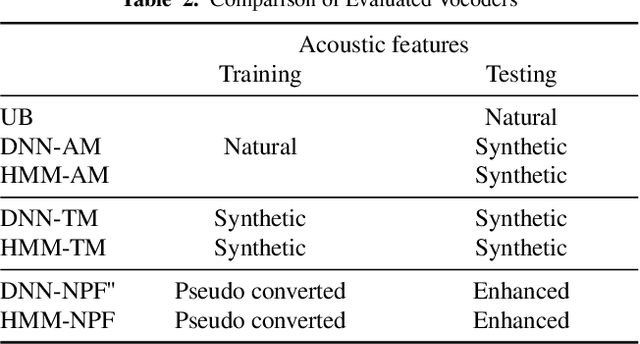
Neural-based text-to-speech (TTS) systems achieve very high-fidelity speech generation because of the rapid neural network developments. However, the huge labeled corpus and high computation cost requirements limit the possibility of developing a high-fidelity TTS system by small companies or individuals. On the other hand, a neural vocoder, which has been widely adopted for the speech generation in neural-based TTS systems, can be trained with a relatively small unlabeled corpus. Therefore, in this paper, we explore a general framework to develop a neural post-filter (NPF) for low-cost TTS systems using neural vocoders. A cyclical approach is proposed to tackle the acoustic and temporal mismatches (AM and TM) of developing an NPF. Both objective and subjective evaluations have been conducted to demonstrate the AM and TM problems and the effectiveness of the proposed framework.
Direct Noisy Speech Modeling for Noisy-to-Noisy Voice Conversion
Nov 13, 2021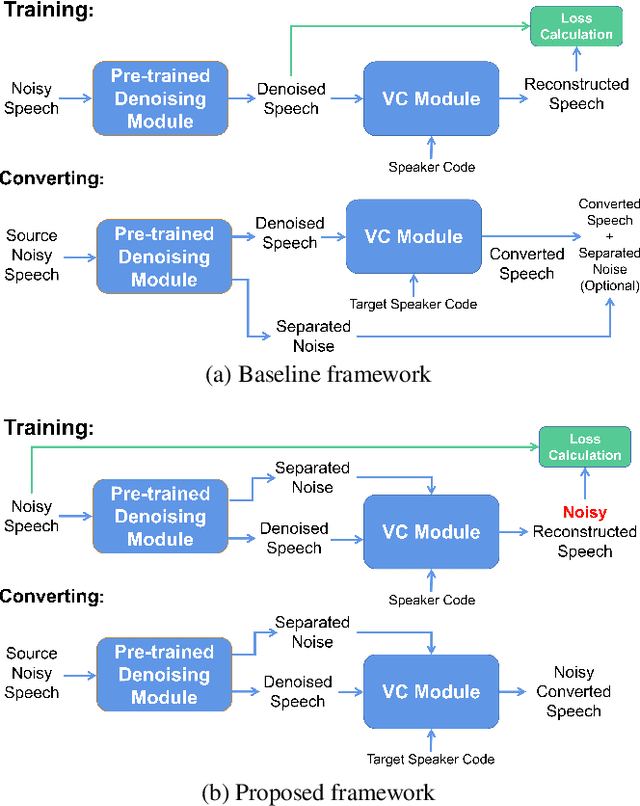
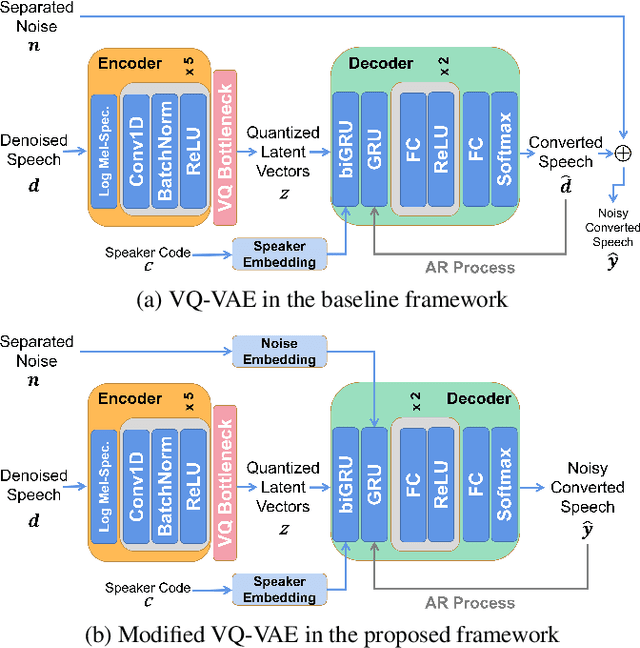
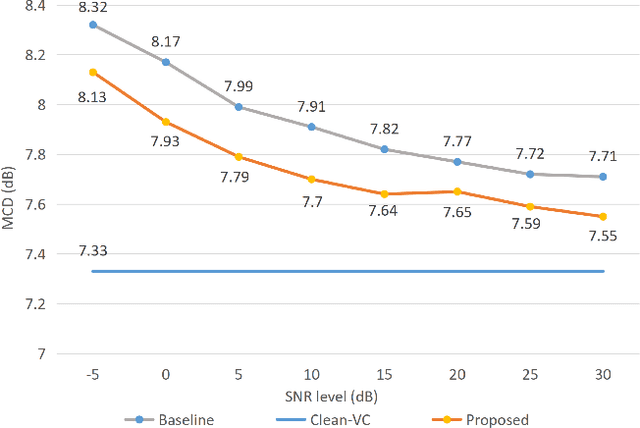
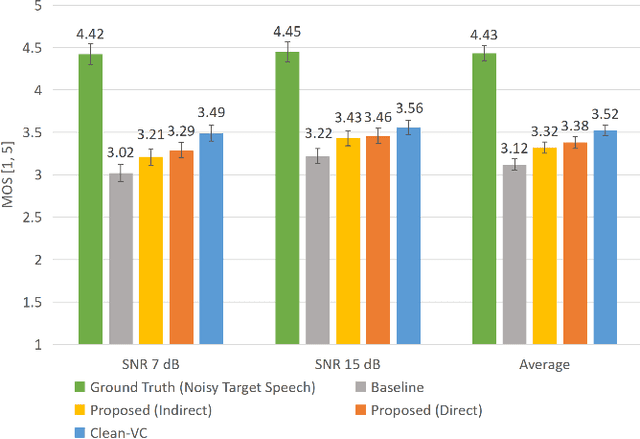
Beyond the conventional voice conversion (VC) where the speaker information is converted without altering the linguistic content, the background sounds are informative and need to be retained in some real-world scenarios, such as VC in movie/video and VC in music where the voice is entangled with background sounds. As a new VC framework, we have developed a noisy-to-noisy (N2N) VC framework to convert the speaker's identity while preserving the background sounds. Although our framework consisting of a denoising module and a VC module well handles the background sounds, the VC module is sensitive to the distortion caused by the denoising module. To address this distortion issue, in this paper we propose the improved VC module to directly model the noisy speech waveform while controlling the background sounds. The experimental results have demonstrated that our improved framework significantly outperforms the previous one and achieves an acceptable score in terms of naturalness, while reaching comparable similarity performance to the upper bound of our framework.
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021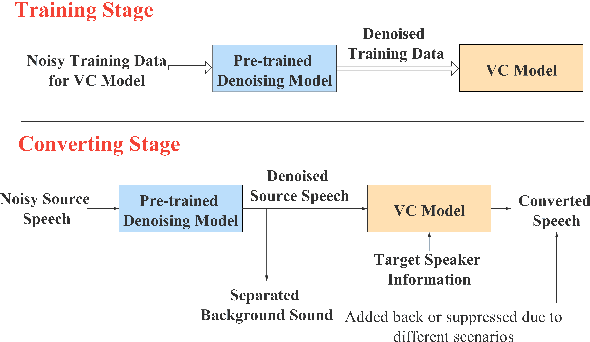
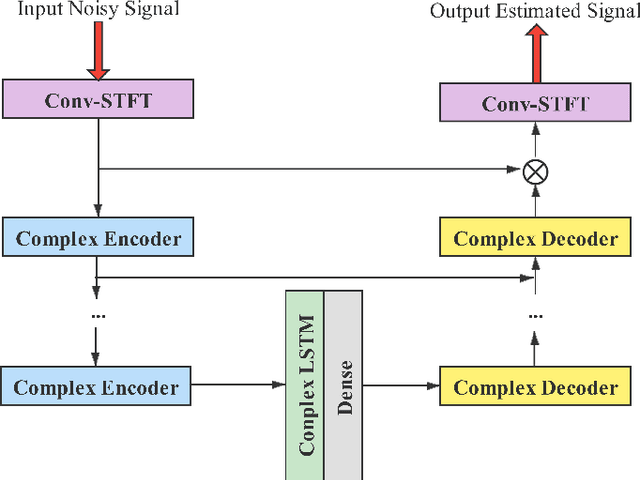
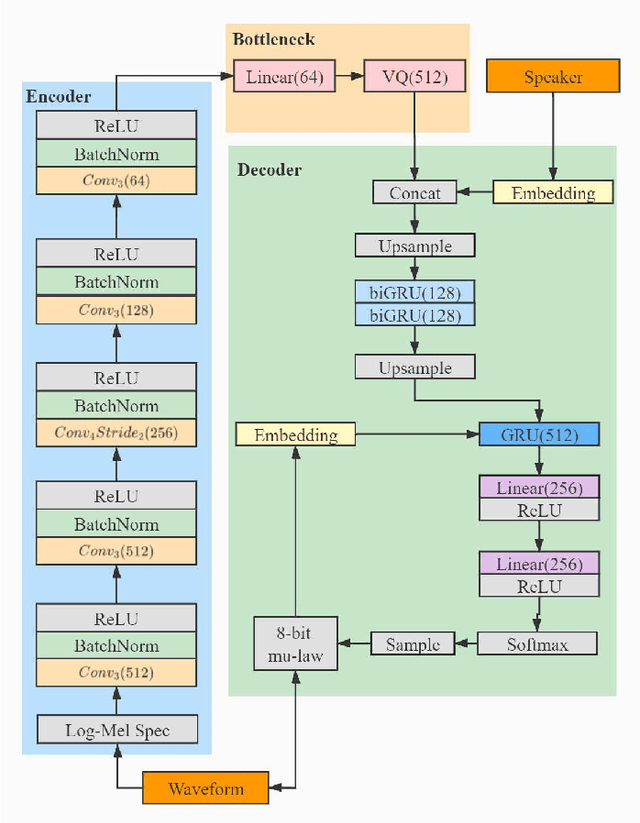
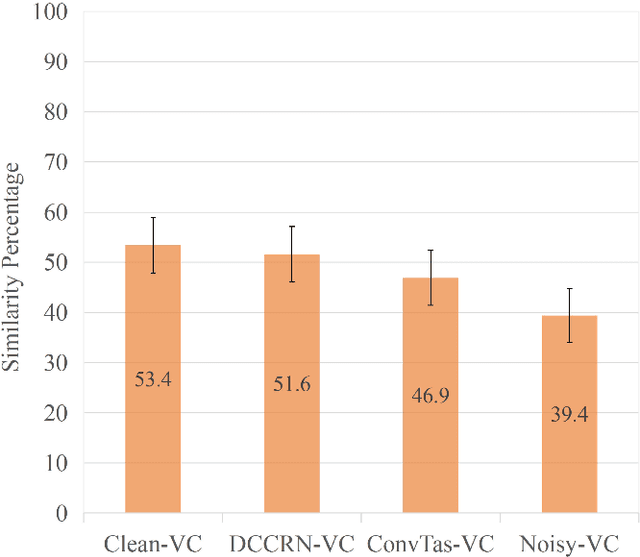
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Low-Latency Real-Time Non-Parallel Voice Conversion based on Cyclic Variational Autoencoder and Multiband WaveRNN with Data-Driven Linear Prediction
May 20, 2021



This paper presents a low-latency real-time (LLRT) non-parallel voice conversion (VC) framework based on cyclic variational autoencoder (CycleVAE) and multiband WaveRNN with data-driven linear prediction (MWDLP). CycleVAE is a robust non-parallel multispeaker spectral model, which utilizes a speaker-independent latent space and a speaker-dependent code to generate reconstructed/converted spectral features given the spectral features of an input speaker. On the other hand, MWDLP is an efficient and a high-quality neural vocoder that can handle multispeaker data and generate speech waveform for LLRT applications with CPU. To accommodate LLRT constraint with CPU, we propose a novel CycleVAE framework that utilizes mel-spectrogram as spectral features and is built with a sparse network architecture. Further, to improve the modeling performance, we also propose a novel fine-tuning procedure that refines the frame-rate CycleVAE network by utilizing the waveform loss from the MWDLP network. The experimental results demonstrate that the proposed framework achieves high-performance VC, while allowing for LLRT usage with a single-core of $2.1$--$2.7$~GHz CPU on a real-time factor of $0.87$--$0.95$, including input/output, feature extraction, on a frame shift of $10$ ms, a window length of $27.5$ ms, and $2$ lookup frames.
High-Fidelity and Low-Latency Universal Neural Vocoder based on Multiband WaveRNN with Data-Driven Linear Prediction for Discrete Waveform Modeling
May 20, 2021


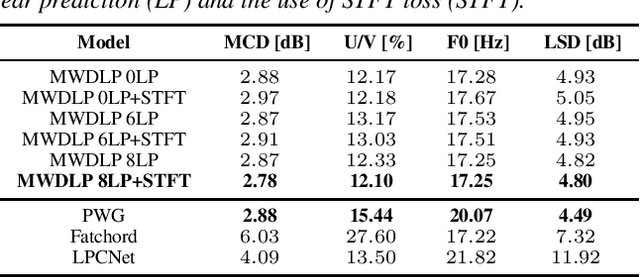
This paper presents a novel high-fidelity and low-latency universal neural vocoder framework based on multiband WaveRNN with data-driven linear prediction for discrete waveform modeling (MWDLP). MWDLP employs a coarse-fine bit WaveRNN architecture for 10-bit mu-law waveform modeling. A sparse gated recurrent unit with a relatively large size of hidden units is utilized, while the multiband modeling is deployed to achieve real-time low-latency usage. A novel technique for data-driven linear prediction (LP) with discrete waveform modeling is proposed, where the LP coefficients are estimated in a data-driven manner. Moreover, a novel loss function using short-time Fourier transform (STFT) for discrete waveform modeling with Gumbel approximation is also proposed. The experimental results demonstrate that the proposed MWDLP framework generates high-fidelity synthetic speech for seen and unseen speakers and/or language on 300 speakers training data including clean and noisy/reverberant conditions, where the number of training utterances is limited to 60 per speaker, while allowing for real-time low-latency processing using a single core of $\sim\!$ 2.1--2.7~GHz CPU with $\sim\!$ 0.57--0.64 real-time factor including input/output and feature extraction.
crank: An Open-Source Software for Nonparallel Voice Conversion Based on Vector-Quantized Variational Autoencoder
Mar 04, 2021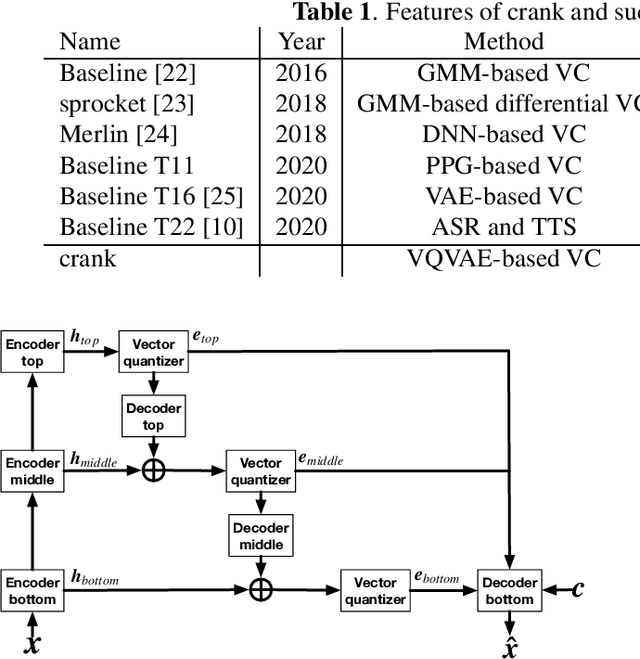

In this paper, we present an open-source software for developing a nonparallel voice conversion (VC) system named crank. Although we have released an open-source VC software based on the Gaussian mixture model named sprocket in the last VC Challenge, it is not straightforward to apply any speech corpus because it is necessary to prepare parallel utterances of source and target speakers to model a statistical conversion function. To address this issue, in this study, we developed a new open-source VC software that enables users to model the conversion function by using only a nonparallel speech corpus. For implementing the VC software, we used a vector-quantized variational autoencoder (VQVAE). To rapidly examine the effectiveness of recent technologies developed in this research field, crank also supports several representative works for autoencoder-based VC methods such as the use of hierarchical architectures, cyclic architectures, generative adversarial networks, speaker adversarial training, and neural vocoders. Moreover, it is possible to automatically estimate objective measures such as mel-cepstrum distortion and pseudo mean opinion score based on MOSNet. In this paper, we describe representative functions developed in crank and make brief comparisons by objective evaluations.
The NU Voice Conversion System for the Voice Conversion Challenge 2020: On the Effectiveness of Sequence-to-sequence Models and Autoregressive Neural Vocoders
Oct 09, 2020

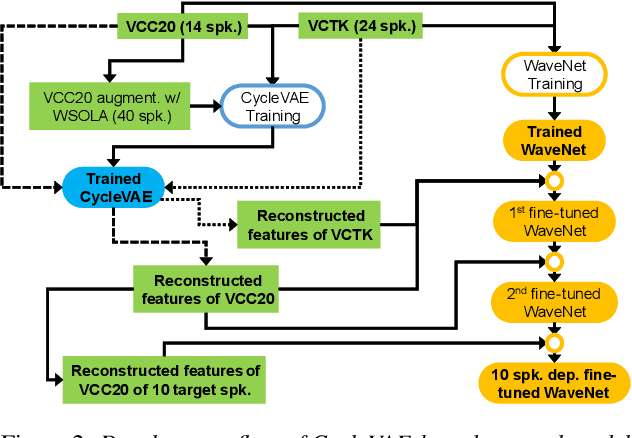
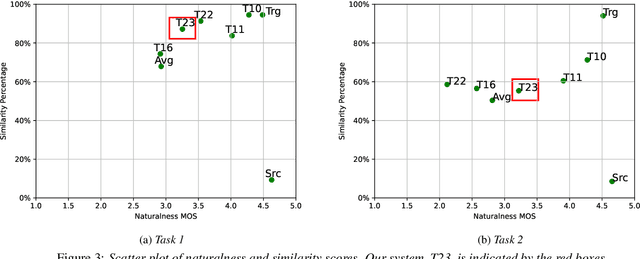
In this paper, we present the voice conversion (VC) systems developed at Nagoya University (NU) for the Voice Conversion Challenge 2020 (VCC2020). We aim to determine the effectiveness of two recent significant technologies in VC: sequence-to-sequence (seq2seq) models and autoregressive (AR) neural vocoders. Two respective systems were developed for the two tasks in the challenge: for task 1, we adopted the Voice Transformer Network, a Transformer-based seq2seq VC model, and extended it with synthetic parallel data to tackle nonparallel data; for task 2, we used the frame-based cyclic variational autoencoder (CycleVAE) to model the spectral features of a speech waveform and the AR WaveNet vocoder with additional fine-tuning. By comparing with the baseline systems, we confirmed that the seq2seq modeling can improve the conversion similarity and that the use of AR vocoders can improve the naturalness of the converted speech.
Baseline System of Voice Conversion Challenge 2020 with Cyclic Variational Autoencoder and Parallel WaveGAN
Oct 09, 2020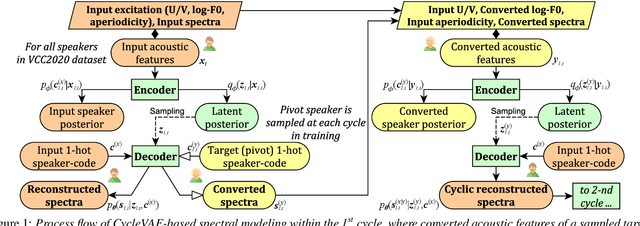



In this paper, we present a description of the baseline system of Voice Conversion Challenge (VCC) 2020 with a cyclic variational autoencoder (CycleVAE) and Parallel WaveGAN (PWG), i.e., CycleVAEPWG. CycleVAE is a nonparallel VAE-based voice conversion that utilizes converted acoustic features to consider cyclically reconstructed spectra during optimization. On the other hand, PWG is a non-autoregressive neural vocoder that is based on a generative adversarial network for a high-quality and fast waveform generator. In practice, the CycleVAEPWG system can be straightforwardly developed with the VCC 2020 dataset using a unified model for both Task 1 (intralingual) and Task 2 (cross-lingual), where our open-source implementation is available at https://github.com/bigpon/vcc20_baseline_cyclevae. The results of VCC 2020 have demonstrated that the CycleVAEPWG baseline achieves the following: 1) a mean opinion score (MOS) of 2.87 in naturalness and a speaker similarity percentage (Sim) of 75.37% for Task 1, and 2) a MOS of 2.56 and a Sim of 56.46% for Task 2, showing an approximately or nearly average score for naturalness and an above average score for speaker similarity.