 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Machine Dubbing Through Phrase-level Cross-lingual Prosody Transfer
Jun 21, 2023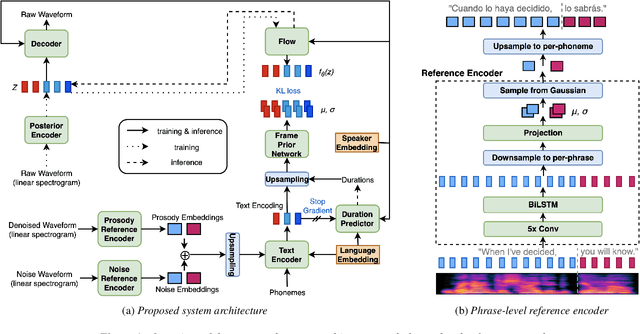
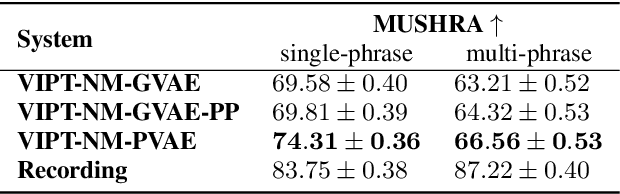
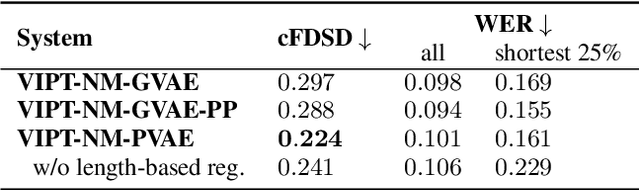
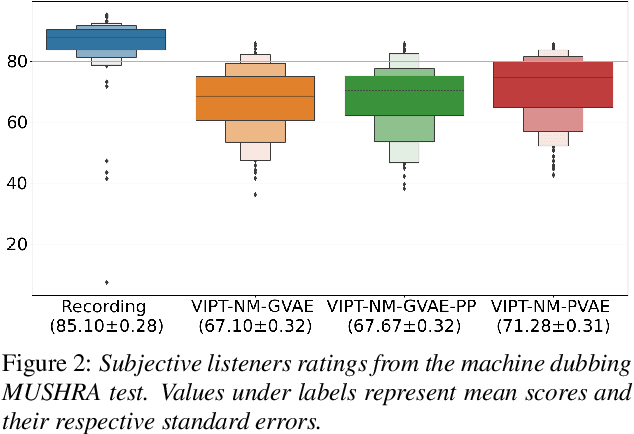
Speech generation for machine dubbing adds complexity to conventional Text-To-Speech solutions as the generated output is required to match the expressiveness, emotion and speaking rate of the source content. Capturing and transferring details and variations in prosody is a challenge. We introduce phrase-level cross-lingual prosody transfer for expressive multi-lingual machine dubbing. The proposed phrase-level prosody transfer delivers a significant 6.2% MUSHRA score increase over a baseline with utterance-level global prosody transfer, thereby closing the gap between the baseline and expressive human dubbing by 23.2%, while preserving intelligibility of the synthesised speech.
On granularity of prosodic representations in expressive text-to-speech
Jan 26, 2023



In expressive speech synthesis it is widely adopted to use latent prosody representations to deal with variability of the data during training. Same text may correspond to various acoustic realizations, which is known as a one-to-many mapping problem in text-to-speech. Utterance, word, or phoneme-level representations are extracted from target signal in an auto-encoding setup, to complement phonetic input and simplify that mapping. This paper compares prosodic embeddings at different levels of granularity and examines their prediction from text. We show that utterance-level embeddings have insufficient capacity and phoneme-level tend to introduce instabilities when predicted from text. Word-level representations impose balance between capacity and predictability. As a result, we close the gap in naturalness by 90% between synthetic speech and recordings on LibriTTS dataset, without sacrificing intelligibility.
Enhancing audio quality for expressive Neural Text-to-Speech
Aug 13, 2021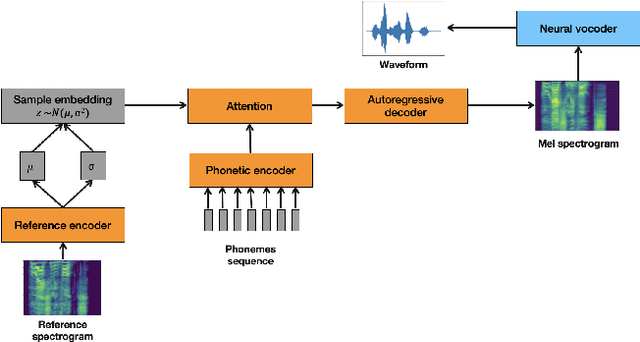
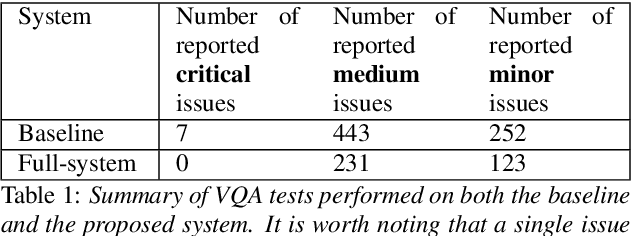
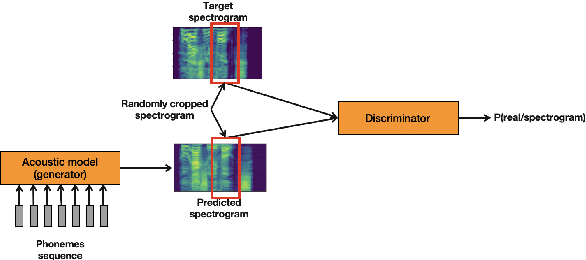
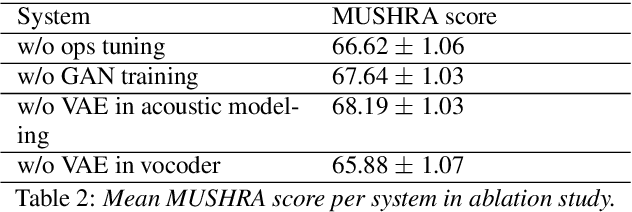
Artificial speech synthesis has made a great leap in terms of naturalness as recent Text-to-Speech (TTS) systems are capable of producing speech with similar quality to human recordings. However, not all speaking styles are easy to model: highly expressive voices are still challenging even to recent TTS architectures since there seems to be a trade-off between expressiveness in a generated audio and its signal quality. In this paper, we present a set of techniques that can be leveraged to enhance the signal quality of a highly-expressive voice without the use of additional data. The proposed techniques include: tuning the autoregressive loop's granularity during training; using Generative Adversarial Networks in acoustic modelling; and the use of Variational Auto-Encoders in both the acoustic model and the neural vocoder. We show that, when combined, these techniques greatly closed the gap in perceived naturalness between the baseline system and recordings by 39% in terms of MUSHRA scores for an expressive celebrity voice.
Non-Autoregressive TTS with Explicit Duration Modelling for Low-Resource Highly Expressive Speech
Jun 25, 2021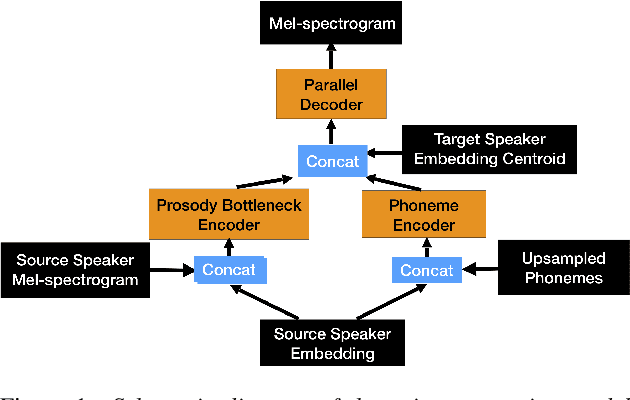
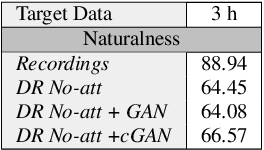

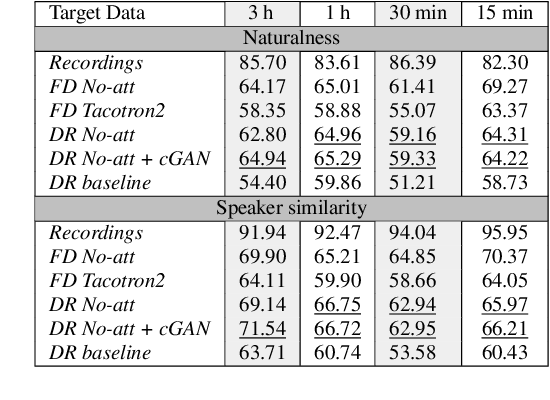
Whilst recent neural text-to-speech (TTS) approaches produce high-quality speech, they typically require a large amount of recordings from the target speaker. In previous work, a 3-step method was proposed to generate high-quality TTS while greatly reducing the amount of data required for training. However, we have observed a ceiling effect in the level of naturalness achievable for highly expressive voices when using this approach. In this paper, we present a method for building highly expressive TTS voices with as little as 15 minutes of speech data from the target speaker. Compared to the current state-of-the-art approach, our proposed improvements close the gap to recordings by 23.3% for naturalness of speech and by 16.3% for speaker similarity. Further, we match the naturalness and speaker similarity of a Tacotron2-based full-data (~10 hours) model using only 15 minutes of target speaker data, whereas with 30 minutes or more, we significantly outperform it. The following improvements are proposed: 1) changing from an autoregressive, attention-based TTS model to a non-autoregressive model replacing attention with an external duration model and 2) an additional Conditional Generative Adversarial Network (cGAN) based fine-tuning step.
Improving the expressiveness of neural vocoding with non-affine Normalizing Flows
Jun 16, 2021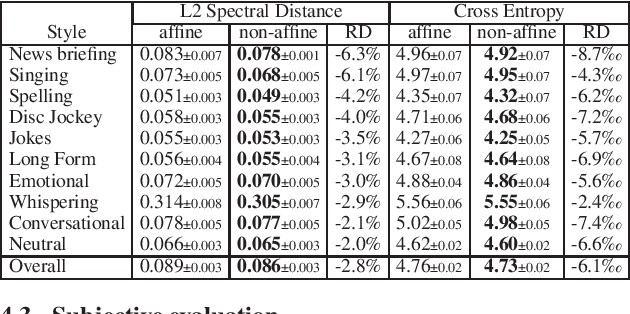

This paper proposes a general enhancement to the Normalizing Flows (NF) used in neural vocoding. As a case study, we improve expressive speech vocoding with a revamped Parallel Wavenet (PW). Specifically, we propose to extend the affine transformation of PW to the more expressive invertible non-affine function. The greater expressiveness of the improved PW leads to better-perceived signal quality and naturalness in the waveform reconstruction and text-to-speech (TTS) tasks. We evaluate the model across different speaking styles on a multi-speaker, multi-lingual dataset. In the waveform reconstruction task, the proposed model closes the naturalness and signal quality gap from the original PW to recordings by $10\%$, and from other state-of-the-art neural vocoding systems by more than $60\%$. We also demonstrate improvements in objective metrics on the evaluation test set with L2 Spectral Distance and Cross-Entropy reduced by $3\%$ and $6\unicode{x2030}$ comparing to the affine PW. Furthermore, we extend the probability density distillation procedure proposed by the original PW paper, so that it works with any non-affine invertible and differentiable function.
Universal Neural Vocoding with Parallel WaveNet
Feb 15, 2021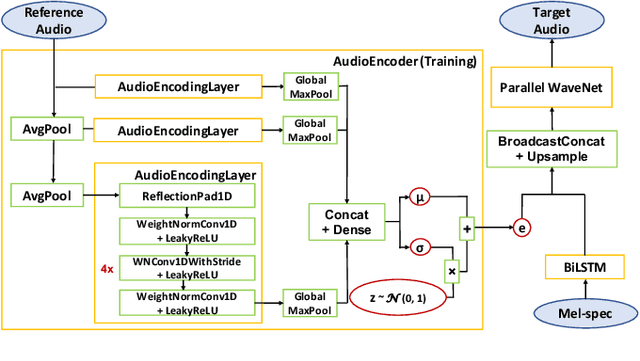

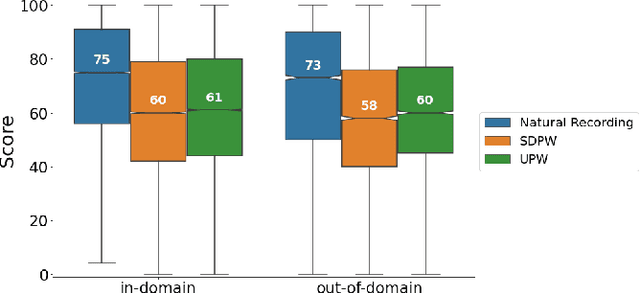
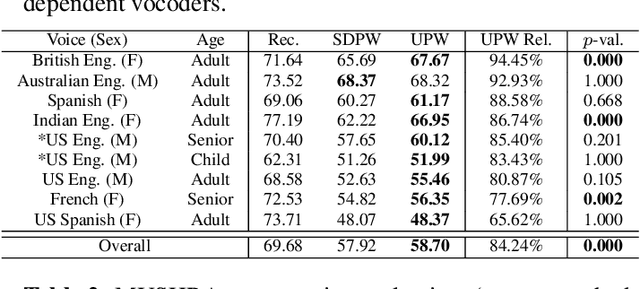
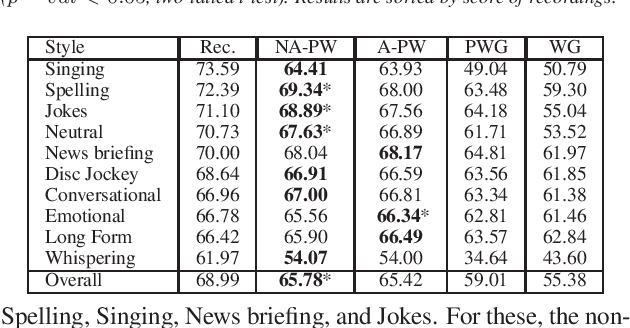
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.
Fine-grained robust prosody transfer for single-speaker neural text-to-speech
Jul 04, 2019
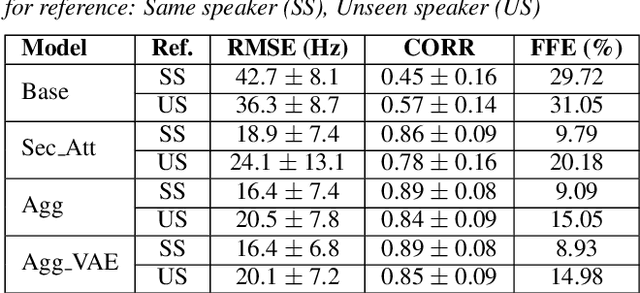
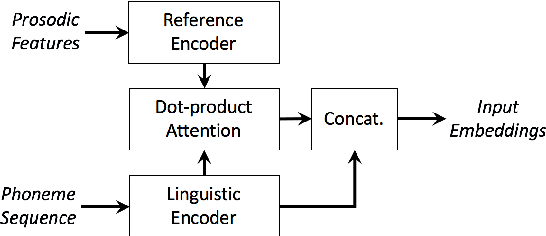
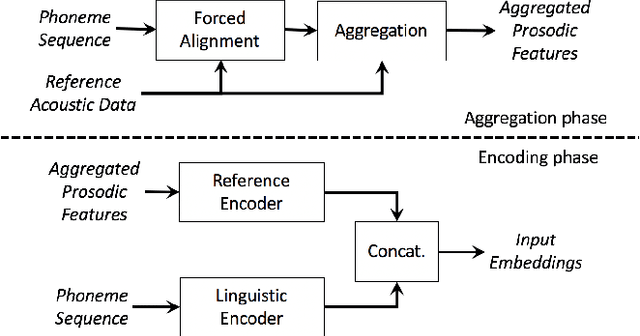
We present a neural text-to-speech system for fine-grained prosody transfer from one speaker to another. Conventional approaches for end-to-end prosody transfer typically use either fixed-dimensional or variable-length prosody embedding via a secondary attention to encode the reference signal. However, when trained on a single-speaker dataset, the conventional prosody transfer systems are not robust enough to speaker variability, especially in the case of a reference signal coming from an unseen speaker. Therefore, we propose decoupling of the reference signal alignment from the overall system. For this purpose, we pre-compute phoneme-level time stamps and use them to aggregate prosodic features per phoneme, injecting them into a sequence-to-sequence text-to-speech system. We incorporate a variational auto-encoder to further enhance the latent representation of prosody embeddings. We show that our proposed approach is significantly more stable and achieves reliable prosody transplantation from an unseen speaker. We also propose a solution to the use case in which the transcription of the reference signal is absent. We evaluate all our proposed methods using both objective and subjective listening tests.
Traditional Machine Learning for Pitch Detection
Mar 04, 2019


Pitch detection is a fundamental problem in speech processing as F0 is used in a large number of applications. Recent articles have proposed deep learning for robust pitch tracking. In this paper, we consider voicing detection as a classification problem and F0 contour estimation as a regression problem. For both tasks, acoustic features from multiple domains and traditional machine learning methods are used. The discrimination power of existing and proposed features is assessed through mutual information. Multiple supervised and unsupervised approaches are compared. A significant relative reduction of voicing errors over the best baseline is obtained: 20% with the best clustering method (K-means) and 45% with a Multi-Layer Perceptron. For F0 contour estimation, the benefits of regression techniques are limited though. We investigate whether those objective gains translate in a parametric synthesis task. Clear perceptual preferences are observed for the proposed approach over two widely-used baselines (RAPT and DIO).