 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Machine Dubbing Through Phrase-level Cross-lingual Prosody Transfer
Jun 21, 2023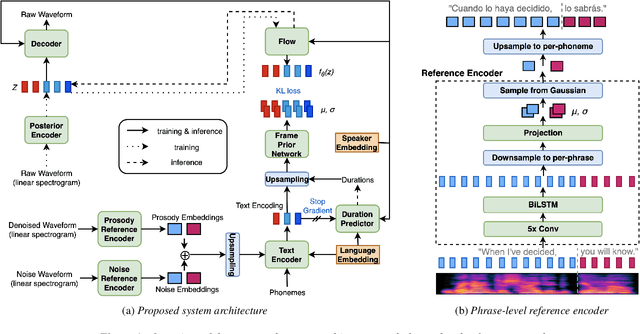
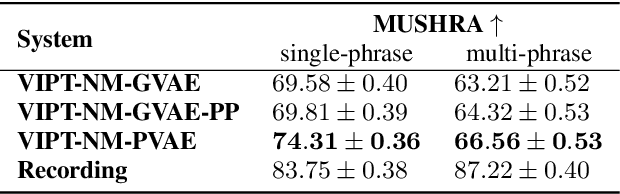
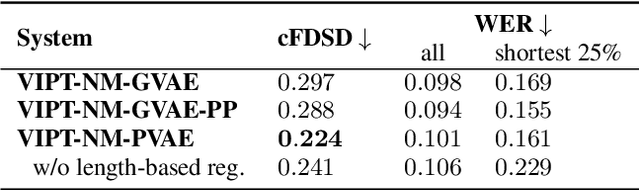
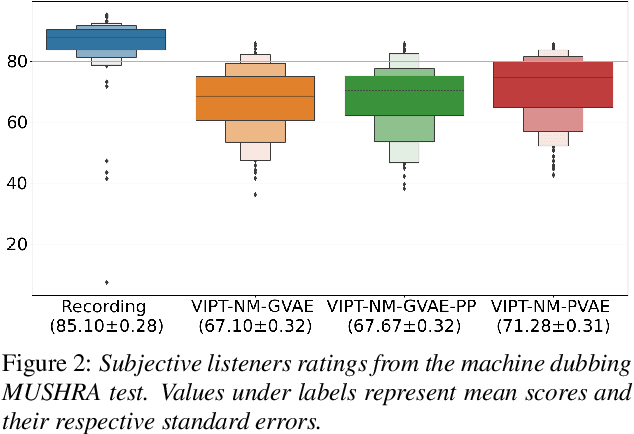
Speech generation for machine dubbing adds complexity to conventional Text-To-Speech solutions as the generated output is required to match the expressiveness, emotion and speaking rate of the source content. Capturing and transferring details and variations in prosody is a challenge. We introduce phrase-level cross-lingual prosody transfer for expressive multi-lingual machine dubbing. The proposed phrase-level prosody transfer delivers a significant 6.2% MUSHRA score increase over a baseline with utterance-level global prosody transfer, thereby closing the gap between the baseline and expressive human dubbing by 23.2%, while preserving intelligibility of the synthesised speech.
Cross-lingual Prosody Transfer for Expressive Machine Dubbing
Jun 20, 2023



Prosody transfer is well-studied in the context of expressive speech synthesis. Cross-lingual prosody transfer, however, is challenging and has been under-explored to date. In this paper, we present a novel solution to learn prosody representations that are transferable across languages and speakers for machine dubbing of expressive multimedia contents. Multimedia contents often contain field recordings. To enable prosody transfer from noisy audios, we introduce a novel noise modelling module that disentangles noise conditioning from prosody conditioning, and thereby gains independent control of noise levels in the synthesised speech. We augment noisy training data with clean data to improve the ability of the model to map the denoised reference audio to clean speech. Our proposed system can generate speech with context-matching prosody and closes the gap between a strong baseline and human expressive dialogs by 11.2%.
On granularity of prosodic representations in expressive text-to-speech
Jan 26, 2023



In expressive speech synthesis it is widely adopted to use latent prosody representations to deal with variability of the data during training. Same text may correspond to various acoustic realizations, which is known as a one-to-many mapping problem in text-to-speech. Utterance, word, or phoneme-level representations are extracted from target signal in an auto-encoding setup, to complement phonetic input and simplify that mapping. This paper compares prosodic embeddings at different levels of granularity and examines their prediction from text. We show that utterance-level embeddings have insufficient capacity and phoneme-level tend to introduce instabilities when predicted from text. Word-level representations impose balance between capacity and predictability. As a result, we close the gap in naturalness by 90% between synthetic speech and recordings on LibriTTS dataset, without sacrificing intelligibility.