 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR^2-HGP: A Double-Regularized Gaussian Process for Heterogeneous Transfer Learning
Dec 11, 2025Multi-output Gaussian process (MGP) models have attracted significant attention for their flexibility and uncertainty-quantification capabilities, and have been widely adopted in multi-source transfer learning scenarios due to their ability to capture inter-task correlations. However, they still face several challenges in transfer learning. First, the input spaces of the source and target domains are often heterogeneous, which makes direct knowledge transfer difficult. Second, potential prior knowledge and physical information are typically ignored during heterogeneous transfer, hampering the utilization of domain-specific insights and leading to unstable mappings. Third, inappropriate information sharing among target and sources can easily lead to negative transfer. Traditional models fail to address these issues in a unified way. To overcome these limitations, this paper proposes a Double-Regularized Heterogeneous Gaussian Process framework (R^2-HGP). Specifically, a trainable prior probability mapping model is first proposed to align the heterogeneous input domains. The resulting aligned inputs are treated as latent variables, upon which a multi-source transfer GP model is constructed and the entire structure is integrated into a novel conditional variational autoencoder (CVAE) based framework. Physical insights is further incorporated as a regularization term to ensure that the alignment results adhere to known physical knowledge. Next, within the multi-source transfer GP model, a sparsity penalty is imposed on the transfer coefficients, enabling the model to adaptively select the most informative source outputs and suppress negative transfer. Extensive simulations and real-world engineering case studies validate the effectiveness of our R^2-HGP, demonstrating consistent superiority over state-of-the-art benchmarks across diverse evaluation metrics.
Verification and Validation of a Vision-Based Landing System for Autonomous VTOL Air Taxis
Dec 11, 2024
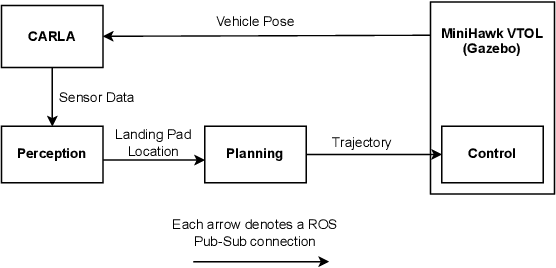
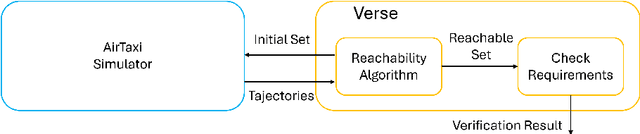
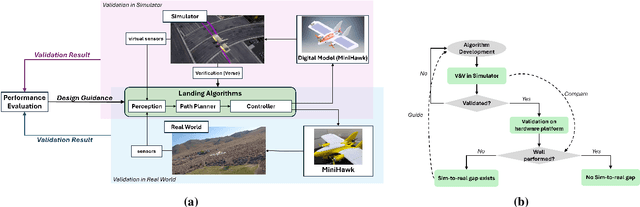
Autonomous air taxis are poised to revolutionize urban mass transportation, however, ensuring their safety and reliability remains an open challenge. Validating autonomy solutions on air taxis in the real world presents complexities, risks, and costs that further convolute this challenge. Verification and Validation (V&V) frameworks play a crucial role in the design and development of highly reliable systems by formally verifying safety properties and validating algorithm behavior across diverse operational scenarios. Advancements in high-fidelity simulators have significantly enhanced their capability to emulate real-world conditions, encouraging their use for validating autonomous air taxi solutions, especially during early development stages. This evolution underscores the growing importance of simulation environments, not only as complementary tools to real-world testing but as essential platforms for evaluating algorithms in a controlled, reproducible, and scalable manner. This work presents a V&V framework for a vision-based landing system for air taxis with vertical take-off and landing (VTOL) capabilities. Specifically, we use Verse, a tool for formal verification, to model and verify the safety of the system by obtaining and analyzing the reachable sets. To conduct this analysis, we utilize a photorealistic simulation environment. The simulation environment, built on Unreal Engine, provides realistic terrain, weather, and sensor characteristics to emulate real-world conditions with high fidelity. To validate the safety analysis results, we conduct extensive scenario-based testing to assess the reachability set and robustness of the landing algorithm in various conditions. This approach showcases the representativeness of high-fidelity simulators, offering an effective means to analyze and refine algorithms before real-world deployment.
Bayesian Data Augmentation and Training for Perception DNN in Autonomous Aerial Vehicles
Dec 10, 2024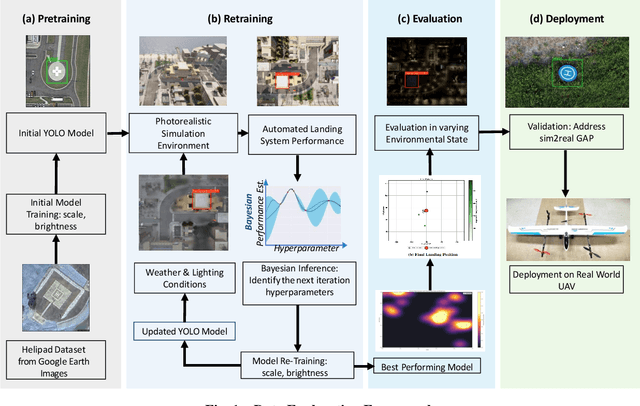
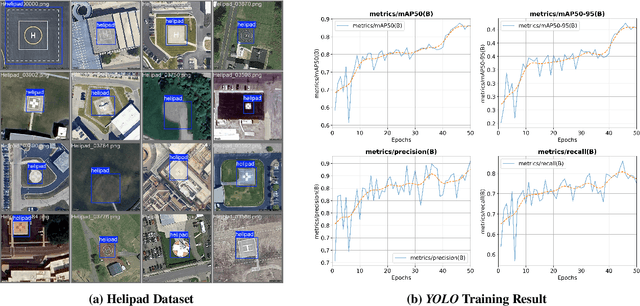
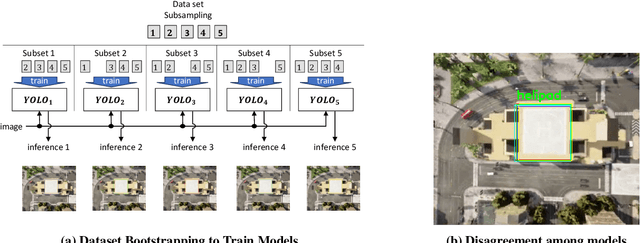
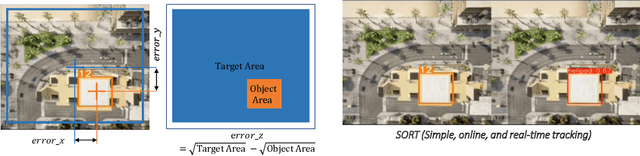
Learning-based solutions have enabled incredible capabilities for autonomous systems. Autonomous vehicles, both aerial and ground, rely on DNN for various integral tasks, including perception. The efficacy of supervised learning solutions hinges on the quality of the training data. Discrepancies between training data and operating conditions result in faults that can lead to catastrophic incidents. However, collecting vast amounts of context-sensitive data, with broad coverage of possible operating environments, is prohibitively difficult. Synthetic data generation techniques for DNN allow for the easy exploration of diverse scenarios. However, synthetic data generation solutions for aerial vehicles are still lacking. This work presents a data augmentation framework for aerial vehicle's perception training, leveraging photorealistic simulation integrated with high-fidelity vehicle dynamics. Safe landing is a crucial challenge in the development of autonomous air taxis, therefore, landing maneuver is chosen as the focus of this work. With repeated simulations of landing in varying scenarios we assess the landing performance of the VTOL type UAV and gather valuable data. The landing performance is used as the objective function to optimize the DNN through retraining. Given the high computational cost of DNN retraining, we incorporated Bayesian Optimization in our framework that systematically explores the data augmentation parameter space to retrain the best-performing models. The framework allowed us to identify high-performing data augmentation parameters that are consistently effective across different landing scenarios. Utilizing the capabilities of this data augmentation framework, we obtained a robust perception model. The model consistently improved the perception-based landing success rate by at least 20% under different lighting and weather conditions.
Online design of dynamic networks
Oct 11, 2024



Designing a network (e.g., a telecommunication or transport network) is mainly done offline, in a planning phase, prior to the operation of the network. On the other hand, a massive effort has been devoted to characterizing dynamic networks, i.e., those that evolve over time. The novelty of this paper is that we introduce a method for the online design of dynamic networks. The need to do so emerges when a network needs to operate in a dynamic and stochastic environment. In this case, one may wish to build a network over time, on the fly, in order to react to the changes of the environment and to keep certain performance targets. We tackle this online design problem with a rolling horizon optimization based on Monte Carlo Tree Search. The potential of online network design is showcased for the design of a futuristic dynamic public transport network, where bus lines are constructed on the fly to better adapt to a stochastic user demand. In such a scenario, we compare our results with state-of-the-art dynamic vehicle routing problem (VRP) resolution methods, simulating requests from a New York City taxi dataset. Differently from classic VRP methods, that extend vehicle trajectories in isolation, our method enables us to build a structured network of line buses, where complex user journeys are possible, thus increasing system performance.
Public Transport Network Design for Equality of Accessibility via Message Passing Neural Networks and Reinforcement Learning
Oct 11, 2024



Designing Public Transport (PT) networks able to satisfy mobility needs of people is essential to reduce the number of individual vehicles on the road, and thus pollution and congestion. Urban sustainability is thus tightly coupled to an efficient PT. Current approaches on Transport Network Design (TND) generally aim to optimize generalized cost, i.e., a unique number including operator and users' costs. Since we intend quality of PT as the capability of satisfying mobility needs, we focus instead on PT accessibility, i.e., the ease of reaching surrounding points of interest via PT. PT accessibility is generally unequally distributed in urban regions: suburbs generally suffer from poor PT accessibility, which condemns residents therein to be dependent on their private cars. We thus tackle the problem of designing bus lines so as to minimize the inequality in the geographical distribution of accessibility. We combine state-of-the-art Message Passing Neural Networks (MPNN) and Reinforcement Learning. We show the efficacy of our method against metaheuristics (classically used in TND) in a use case representing in simplified terms the city of Montreal.
LLMs as Zero-shot Graph Learners: Alignment of GNN Representations with LLM Token Embeddings
Aug 25, 2024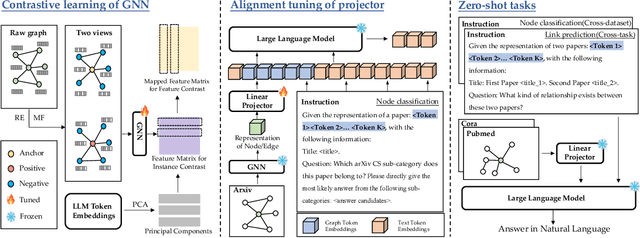
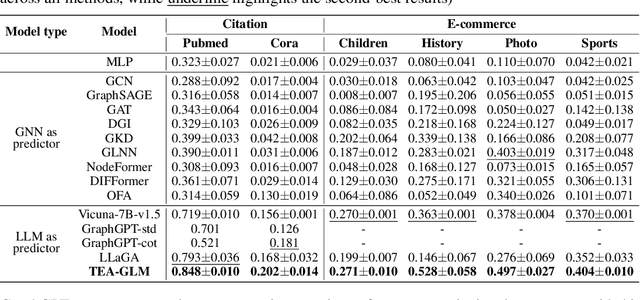
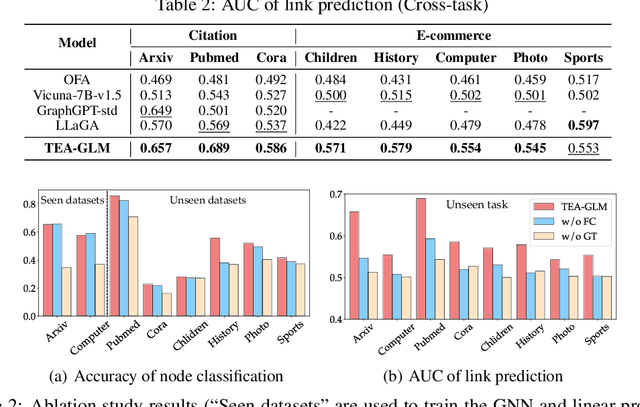
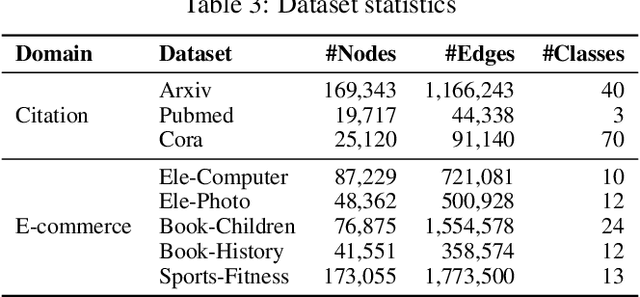
Zero-shot graph machine learning, especially with graph neural networks (GNNs), has garnered significant interest due to the challenge of scarce labeled data. While methods like self-supervised learning and graph prompt learning have been extensively explored, they often rely on fine-tuning with task-specific labels, limiting their effectiveness in zero-shot scenarios. Inspired by the zero-shot capabilities of instruction-fine-tuned large language models (LLMs), we introduce a novel framework named Token Embedding-Aligned Graph Language Model (TEA-GLM) that leverages LLMs as cross-dataset and cross-task zero-shot learners for graph machine learning. Concretely, we pretrain a GNN, aligning its representations with token embeddings of an LLM. We then train a linear projector that transforms the GNN's representations into a fixed number of graph token embeddings without tuning the LLM. A unified instruction is designed for various graph tasks at different levels, such as node classification (node-level) and link prediction (edge-level). These design choices collectively enhance our method's effectiveness in zero-shot learning, setting it apart from existing methods. Experiments show that our graph token embeddings help the LLM predictor achieve state-of-the-art performance on unseen datasets and tasks compared to other methods using LLMs as predictors.
Expressive Machine Dubbing Through Phrase-level Cross-lingual Prosody Transfer
Jun 21, 2023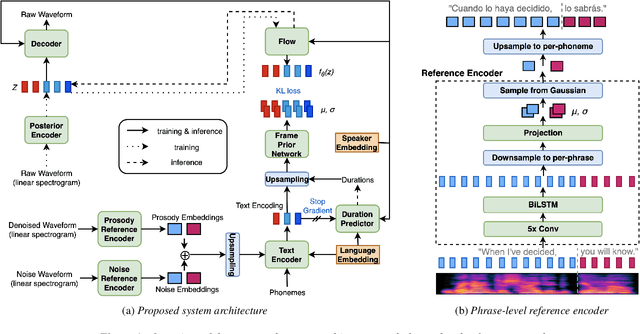
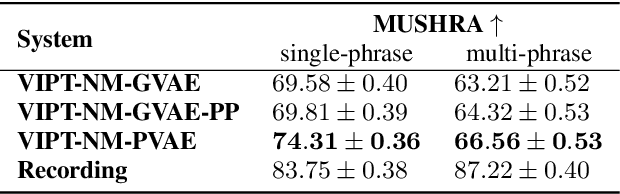
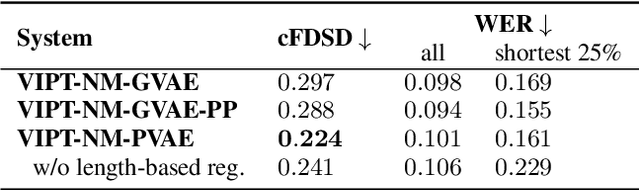
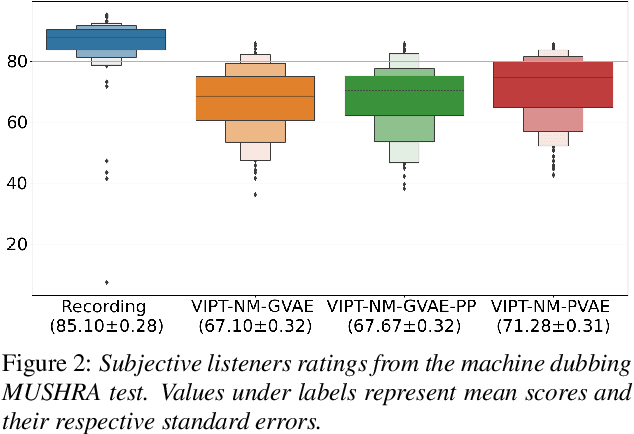
Speech generation for machine dubbing adds complexity to conventional Text-To-Speech solutions as the generated output is required to match the expressiveness, emotion and speaking rate of the source content. Capturing and transferring details and variations in prosody is a challenge. We introduce phrase-level cross-lingual prosody transfer for expressive multi-lingual machine dubbing. The proposed phrase-level prosody transfer delivers a significant 6.2% MUSHRA score increase over a baseline with utterance-level global prosody transfer, thereby closing the gap between the baseline and expressive human dubbing by 23.2%, while preserving intelligibility of the synthesised speech.
Cross-lingual Prosody Transfer for Expressive Machine Dubbing
Jun 20, 2023



Prosody transfer is well-studied in the context of expressive speech synthesis. Cross-lingual prosody transfer, however, is challenging and has been under-explored to date. In this paper, we present a novel solution to learn prosody representations that are transferable across languages and speakers for machine dubbing of expressive multimedia contents. Multimedia contents often contain field recordings. To enable prosody transfer from noisy audios, we introduce a novel noise modelling module that disentangles noise conditioning from prosody conditioning, and thereby gains independent control of noise levels in the synthesised speech. We augment noisy training data with clean data to improve the ability of the model to map the denoised reference audio to clean speech. Our proposed system can generate speech with context-matching prosody and closes the gap between a strong baseline and human expressive dialogs by 11.2%.
Model Architecture Adaption for Bayesian Neural Networks
Feb 09, 2022



Bayesian Neural Networks (BNNs) offer a mathematically grounded framework to quantify the uncertainty of model predictions but come with a prohibitive computation cost for both training and inference. In this work, we show a novel network architecture search (NAS) that optimizes BNNs for both accuracy and uncertainty while having a reduced inference latency. Different from canonical NAS that optimizes solely for in-distribution likelihood, the proposed scheme searches for the uncertainty performance using both in- and out-of-distribution data. Our method is able to search for the correct placement of Bayesian layer(s) in a network. In our experiments, the searched models show comparable uncertainty quantification ability and accuracy compared to the state-of-the-art (deep ensemble). In addition, the searched models use only a fraction of the runtime compared to many popular BNN baselines, reducing the inference runtime cost by $2.98 \times$ and $2.92 \times$ respectively on the CIFAR10 dataset when compared to MCDropout and deep ensemble.
Fine-grained Multi-Modal Self-Supervised Learning
Dec 22, 2021



Multi-Modal Self-Supervised Learning from videos has been shown to improve model's performance on various downstream tasks. However, such Self-Supervised pre-training requires large batch sizes and a large amount of computation resources due to the noise present in the uncurated data. This is partly due to the fact that the prevalent training scheme is trained on coarse-grained setting, in which vectors representing the whole video clips or natural language sentences are used for computing similarity. Such scheme makes training noisy as part of the video clips can be totally not correlated with the other-modality input such as text description. In this paper, we propose a fine-grained multi-modal self-supervised training scheme that computes the similarity between embeddings at finer-scale (such as individual feature map embeddings and embeddings of phrases), and uses attention mechanisms to reduce noisy pairs' weighting in the loss function. We show that with the proposed pre-training scheme, we can train smaller models, with smaller batch-size and much less computational resources to achieve downstream tasks performances comparable to State-Of-The-Art, for tasks including action recognition and text-image retrievals.