 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWakeUpNet: A Mobile-Transformer based Framework for End-to-End Streaming Voice Trigger
Oct 06, 2022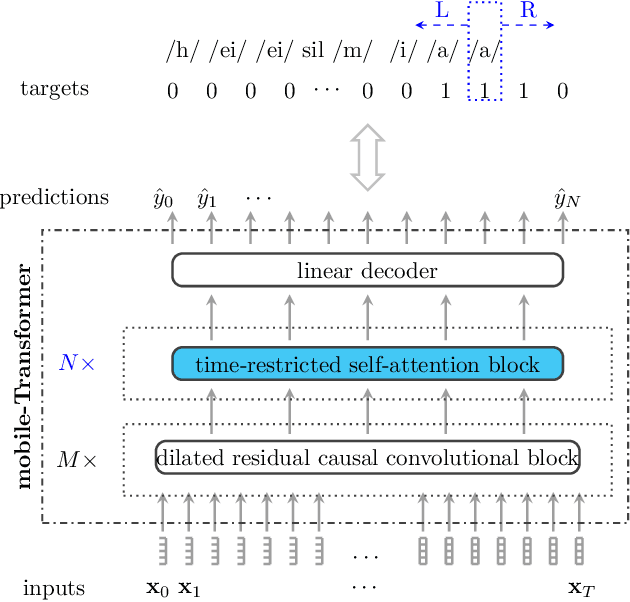
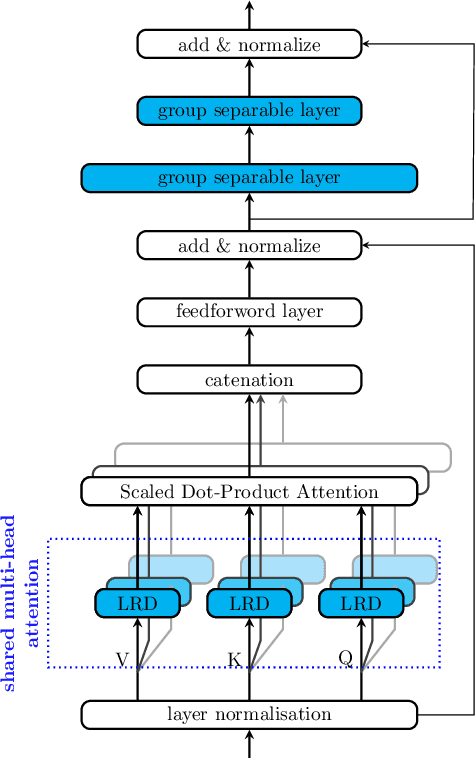
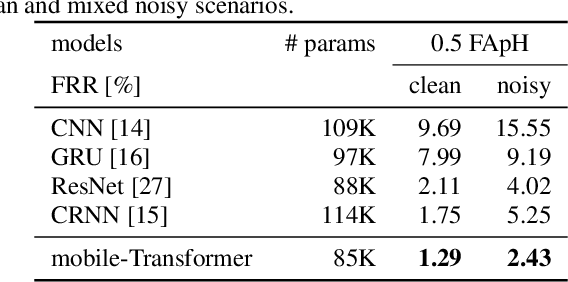
End-to-end models have gradually become the main technical stream for voice trigger, aiming to achieve an utmost prediction accuracy but with a small footprint. In present paper, we propose an end-to-end voice trigger framework, namely WakeupNet, which is basically structured on a Transformer encoder. The purpose of this framework is to explore the context-capturing capability of Transformer, as sequential information is vital for wakeup-word detection. However, the conventional Transformer encoder is too large to fit our task. To address this issue, we introduce different model compression approaches to shrink the vanilla one into a tiny one, called mobile-Transformer. To evaluate the performance of mobile-Transformer, we conduct extensive experiments on a large public-available dataset HiMia. The obtained results indicate that introduced mobile-Transformer significantly outperforms other frequently used models for voice trigger in both clean and noisy scenarios.
Efficient Adapter Transfer of Self-Supervised Speech Models for Automatic Speech Recognition
Feb 07, 2022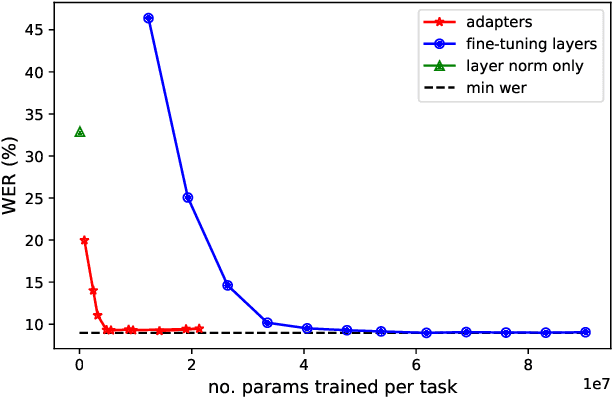
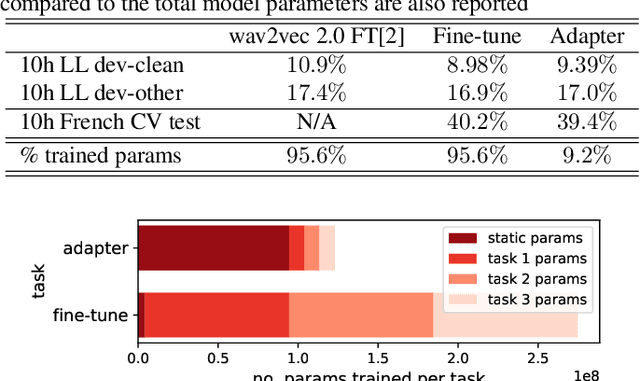

Self-supervised learning (SSL) is a powerful tool that allows learning of underlying representations from unlabeled data. Transformer based models such as wav2vec 2.0 and HuBERT are leading the field in the speech domain. Generally these models are fine-tuned on a small amount of labeled data for a downstream task such as Automatic Speech Recognition (ASR). This involves re-training the majority of the model for each task. Adapters are small lightweight modules which are commonly used in Natural Language Processing (NLP) to adapt pre-trained models to new tasks. In this paper we propose applying adapters to wav2vec 2.0 to reduce the number of parameters required for downstream ASR tasks, and increase scalability of the model to multiple tasks or languages. Using adapters we can perform ASR while training fewer than 10% of parameters per task compared to full fine-tuning with little degradation of performance. Ablations show that applying adapters into just the top few layers of the pre-trained network gives similar performance to full transfer, supporting the theory that higher pre-trained layers encode more phonemic information, and further optimizing efficiency.
Fine-grained Multi-Modal Self-Supervised Learning
Dec 22, 2021



Multi-Modal Self-Supervised Learning from videos has been shown to improve model's performance on various downstream tasks. However, such Self-Supervised pre-training requires large batch sizes and a large amount of computation resources due to the noise present in the uncurated data. This is partly due to the fact that the prevalent training scheme is trained on coarse-grained setting, in which vectors representing the whole video clips or natural language sentences are used for computing similarity. Such scheme makes training noisy as part of the video clips can be totally not correlated with the other-modality input such as text description. In this paper, we propose a fine-grained multi-modal self-supervised training scheme that computes the similarity between embeddings at finer-scale (such as individual feature map embeddings and embeddings of phrases), and uses attention mechanisms to reduce noisy pairs' weighting in the loss function. We show that with the proposed pre-training scheme, we can train smaller models, with smaller batch-size and much less computational resources to achieve downstream tasks performances comparable to State-Of-The-Art, for tasks including action recognition and text-image retrievals.
Continual-wav2vec2: an Application of Continual Learning for Self-Supervised Automatic Speech Recognition
Jul 26, 2021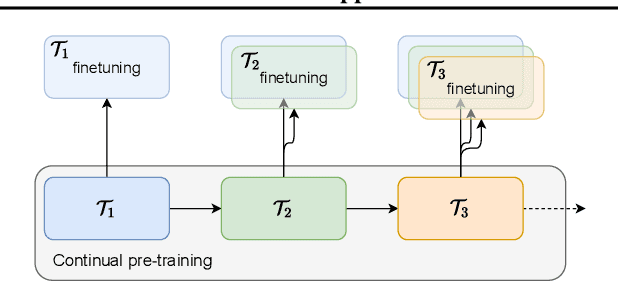
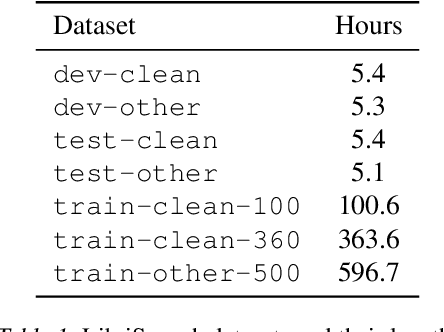
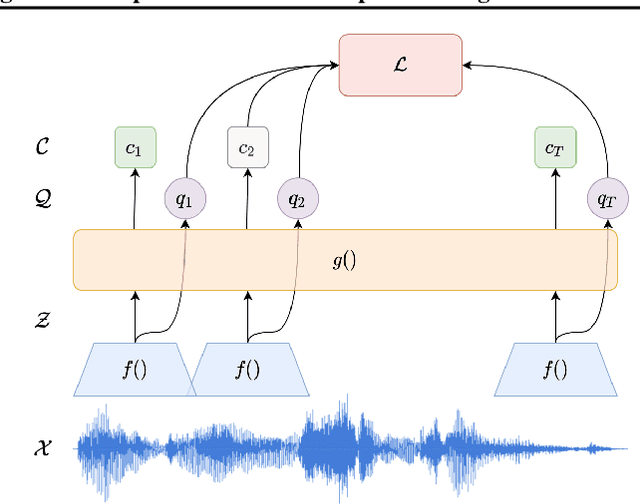
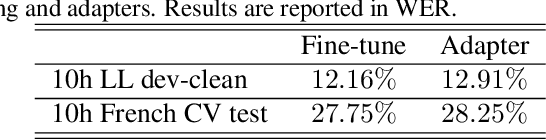
We present a method for continual learning of speech representations for multiple languages using self-supervised learning (SSL) and applying these for automatic speech recognition. There is an abundance of unannotated speech, so creating self-supervised representations from raw audio and finetuning on a small annotated datasets is a promising direction to build speech recognition systems. Wav2vec models perform SSL on raw audio in a pretraining phase and then finetune on a small fraction of annotated data. SSL models have produced state of the art results for ASR. However, these models are very expensive to pretrain with self-supervision. We tackle the problem of learning new language representations continually from audio without forgetting a previous language representation. We use ideas from continual learning to transfer knowledge from a previous task to speed up pretraining a new language task. Our continual-wav2vec2 model can decrease pretraining times by 32% when learning a new language task, and learn this new audio-language representation without forgetting previous language representation.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.