 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Level Diffusion Guidance: Well Begun is Half Done
Sep 17, 2025



Diffusion models have achieved state-of-the-art image generation. However, the random Gaussian noise used to start the diffusion process influences the final output, causing variations in image quality and prompt adherence. Existing noise-level optimization approaches generally rely on extra dataset construction, additional networks, or backpropagation-based optimization, limiting their practicality. In this paper, we propose Noise Level Guidance (NLG), a simple, efficient, and general noise-level optimization approach that refines initial noise by increasing the likelihood of its alignment with general guidance - requiring no additional training data, auxiliary networks, or backpropagation. The proposed NLG approach provides a unified framework generalizable to both conditional and unconditional diffusion models, accommodating various forms of diffusion-level guidance. Extensive experiments on five standard benchmarks demonstrate that our approach enhances output generation quality and input condition adherence. By seamlessly integrating with existing guidance methods while maintaining computational efficiency, our method establishes NLG as a practical and scalable enhancement to diffusion models. Code can be found at https://github.com/harveymannering/NoiseLevelGuidance.
OpenSDI: Spotting Diffusion-Generated Images in the Open World
Mar 25, 2025This paper identifies OpenSDI, a challenge for spotting diffusion-generated images in open-world settings. In response to this challenge, we define a new benchmark, the OpenSDI dataset (OpenSDID), which stands out from existing datasets due to its diverse use of large vision-language models that simulate open-world diffusion-based manipulations. Another outstanding feature of OpenSDID is its inclusion of both detection and localization tasks for images manipulated globally and locally by diffusion models. To address the OpenSDI challenge, we propose a Synergizing Pretrained Models (SPM) scheme to build up a mixture of foundation models. This approach exploits a collaboration mechanism with multiple pretrained foundation models to enhance generalization in the OpenSDI context, moving beyond traditional training by synergizing multiple pretrained models through prompting and attending strategies. Building on this scheme, we introduce MaskCLIP, an SPM-based model that aligns Contrastive Language-Image Pre-Training (CLIP) with Masked Autoencoder (MAE). Extensive evaluations on OpenSDID show that MaskCLIP significantly outperforms current state-of-the-art methods for the OpenSDI challenge, achieving remarkable relative improvements of 14.23% in IoU (14.11% in F1) and 2.05% in accuracy (2.38% in F1) compared to the second-best model in localization and detection tasks, respectively. Our dataset and code are available at https://github.com/iamwangyabin/OpenSDI.
Penny-Wise and Pound-Foolish in Deepfake Detection
Aug 15, 2024



The diffusion of deepfake technologies has sparked serious concerns about its potential misuse across various domains, prompting the urgent need for robust detection methods. Despite advancement, many current approaches prioritize short-term gains at expense of long-term effectiveness. This paper critiques the overly specialized approach of fine-tuning pre-trained models solely with a penny-wise objective on a single deepfake dataset, while disregarding the pound-wise balance for generalization and knowledge retention. To address this "Penny-Wise and Pound-Foolish" issue, we propose a novel learning framework (PoundNet) for generalization of deepfake detection on a pre-trained vision-language model. PoundNet incorporates a learnable prompt design and a balanced objective to preserve broad knowledge from upstream tasks (object classification) while enhancing generalization for downstream tasks (deepfake detection). We train PoundNet on a standard single deepfake dataset, following common practice in the literature. We then evaluate its performance across 10 public large-scale deepfake datasets with 5 main evaluation metrics-forming the largest benchmark test set for assessing the generalization ability of deepfake detection models, to our knowledge. The comprehensive benchmark evaluation demonstrates the proposed PoundNet is significantly less "Penny-Wise and Pound-Foolish", achieving a remarkable improvement of 19% in deepfake detection performance compared to state-of-the-art methods, while maintaining a strong performance of 63% on object classification tasks, where other deepfake detection models tend to be ineffective. Code and data are open-sourced at https://github.com/iamwangyabin/PoundNet.
In-Context Translation: Towards Unifying Image Recognition, Processing, and Generation
Apr 15, 2024



We propose In-Context Translation (ICT), a general learning framework to unify visual recognition (e.g., semantic segmentation), low-level image processing (e.g., denoising), and conditional image generation (e.g., edge-to-image synthesis). Thanks to unification, ICT significantly reduces the inherent inductive bias that comes with designing models for specific tasks, and it maximizes mutual enhancement across similar tasks. However, the unification across a large number of tasks is non-trivial due to various data formats and training pipelines. To this end, ICT introduces two designs. Firstly, it standardizes input-output data of different tasks into RGB image pairs, e.g., semantic segmentation data pairs an RGB image with its segmentation mask in the same RGB format. This turns different tasks into a general translation task between two RGB images. Secondly, it standardizes the training of different tasks into a general in-context learning, where "in-context" means the input comprises an example input-output pair of the target task and a query image. The learning objective is to generate the "missing" data paired with the query. The implicit translation process is thus between the query and the generated image. In experiments, ICT unifies ten vision tasks and showcases impressive performance on their respective benchmarks. Notably, compared to its competitors, e.g., Painter and PromptDiffusion, ICT trained on only 4 RTX 3090 GPUs is shown to be more efficient and less costly in training.
Linguistic Profiling of Deepfakes: An Open Database for Next-Generation Deepfake Detection
Jan 04, 2024The emergence of text-to-image generative models has revolutionized the field of deepfakes, enabling the creation of realistic and convincing visual content directly from textual descriptions. However, this advancement presents considerably greater challenges in detecting the authenticity of such content. Existing deepfake detection datasets and methods often fall short in effectively capturing the extensive range of emerging deepfakes and offering satisfactory explanatory information for detection. To address the significant issue, this paper introduces a deepfake database (DFLIP-3K) for the development of convincing and explainable deepfake detection. It encompasses about 300K diverse deepfake samples from approximately 3K generative models, which boasts the largest number of deepfake models in the literature. Moreover, it collects around 190K linguistic footprints of these deepfakes. The two distinguished features enable DFLIP-3K to develop a benchmark that promotes progress in linguistic profiling of deepfakes, which includes three sub-tasks namely deepfake detection, model identification, and prompt prediction. The deepfake model and prompt are two essential components of each deepfake, and thus dissecting them linguistically allows for an invaluable exploration of trustworthy and interpretable evidence in deepfake detection, which we believe is the key for the next-generation deepfake detection. Furthermore, DFLIP-3K is envisioned as an open database that fosters transparency and encourages collaborative efforts to further enhance its growth. Our extensive experiments on the developed benchmark verify that our DFLIP-3K database is capable of serving as a standardized resource for evaluating and comparing linguistic-based deepfake detection, identification, and prompt prediction techniques.
Adaptive Riemannian Metrics on SPD Manifolds
Mar 26, 2023Symmetric Positive Definite (SPD) matrices have received wide attention in machine learning due to their intrinsic capacity of encoding underlying structural correlation in data. To reflect the non-Euclidean geometry of SPD manifolds, many successful Riemannian metrics have been proposed. However, existing fixed metric tensors might lead to sub-optimal performance for SPD matrices learning, especially for SPD neural networks. To remedy this limitation, we leverage the idea of pullback and propose adaptive Riemannian metrics for SPD manifolds. Moreover, we present comprehensive theories for our metrics. Experiments on three datasets demonstrate that equipped with the proposed metrics, SPD networks can exhibit superior performance.
Freestyle Layout-to-Image Synthesis
Mar 25, 2023



Typical layout-to-image synthesis (LIS) models generate images for a closed set of semantic classes, e.g., 182 common objects in COCO-Stuff. In this work, we explore the freestyle capability of the model, i.e., how far can it generate unseen semantics (e.g., classes, attributes, and styles) onto a given layout, and call the task Freestyle LIS (FLIS). Thanks to the development of large-scale pre-trained language-image models, a number of discriminative models (e.g., image classification and object detection) trained on limited base classes are empowered with the ability of unseen class prediction. Inspired by this, we opt to leverage large-scale pre-trained text-to-image diffusion models to achieve the generation of unseen semantics. The key challenge of FLIS is how to enable the diffusion model to synthesize images from a specific layout which very likely violates its pre-learned knowledge, e.g., the model never sees "a unicorn sitting on a bench" during its pre-training. To this end, we introduce a new module called Rectified Cross-Attention (RCA) that can be conveniently plugged in the diffusion model to integrate semantic masks. This "plug-in" is applied in each cross-attention layer of the model to rectify the attention maps between image and text tokens. The key idea of RCA is to enforce each text token to act on the pixels in a specified region, allowing us to freely put a wide variety of semantics from pre-trained knowledge (which is general) onto the given layout (which is specific). Extensive experiments show that the proposed diffusion network produces realistic and freestyle layout-to-image generation results with diverse text inputs, which has a high potential to spawn a bunch of interesting applications. Code is available at https://github.com/essunny310/FreestyleNet.
Benchmarking Deepart Detection
Feb 28, 2023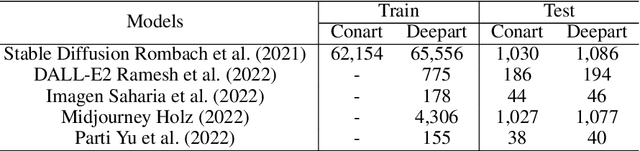

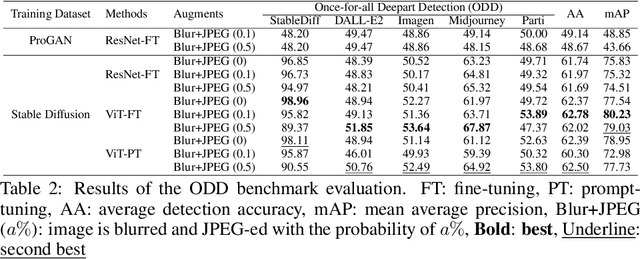
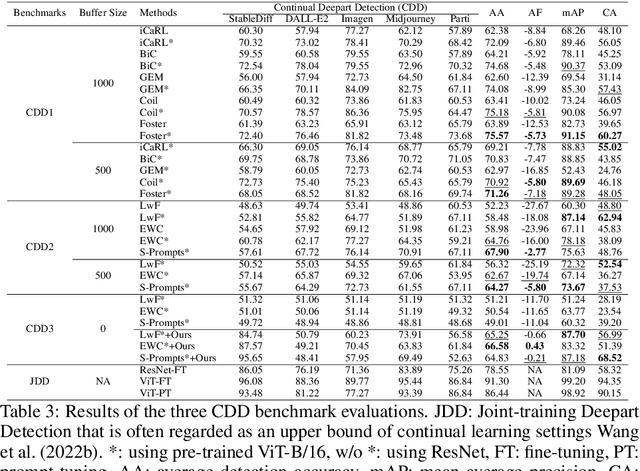
Deepfake technologies have been blurring the boundaries between the real and unreal, likely resulting in malicious events. By leveraging newly emerged deepfake technologies, deepfake researchers have been making a great upending to create deepfake artworks (deeparts), which are further closing the gap between reality and fantasy. To address potentially appeared ethics questions, this paper establishes a deepart detection database (DDDB) that consists of a set of high-quality conventional art images (conarts) and five sets of deepart images generated by five state-of-the-art deepfake models. This database enables us to explore once-for-all deepart detection and continual deepart detection. For the two new problems, we suggest four benchmark evaluations and four families of solutions on the constructed DDDB. The comprehensive study demonstrates the effectiveness of the proposed solutions on the established benchmark dataset, which is capable of paving a way to more interesting directions of deepart detection. The constructed benchmark dataset and the source code will be made publicly available.
Isolation and Impartial Aggregation: A Paradigm of Incremental Learning without Interference
Nov 29, 2022This paper focuses on the prevalent performance imbalance in the stages of incremental learning. To avoid obvious stage learning bottlenecks, we propose a brand-new stage-isolation based incremental learning framework, which leverages a series of stage-isolated classifiers to perform the learning task of each stage without the interference of others. To be concrete, to aggregate multiple stage classifiers as a uniform one impartially, we first introduce a temperature-controlled energy metric for indicating the confidence score levels of the stage classifiers. We then propose an anchor-based energy self-normalization strategy to ensure the stage classifiers work at the same energy level. Finally, we design a voting-based inference augmentation strategy for robust inference. The proposed method is rehearsal free and can work for almost all continual learning scenarios. We evaluate the proposed method on four large benchmarks. Extensive results demonstrate the superiority of the proposed method in setting up new state-of-the-art overall performance. \emph{Code is available at} \url{https://github.com/iamwangyabin/ESN}.
S-Prompts Learning with Pre-trained Transformers: An Occam's Razor for Domain Incremental Learning
Jul 26, 2022
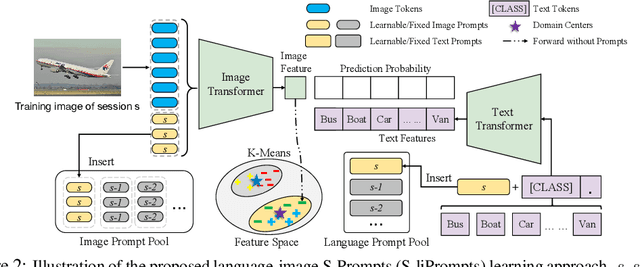
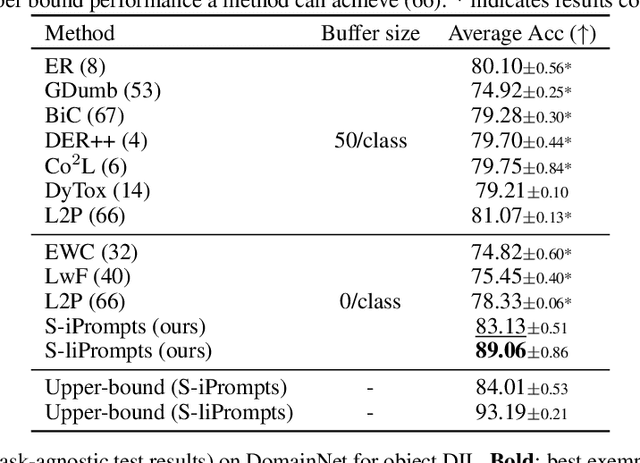
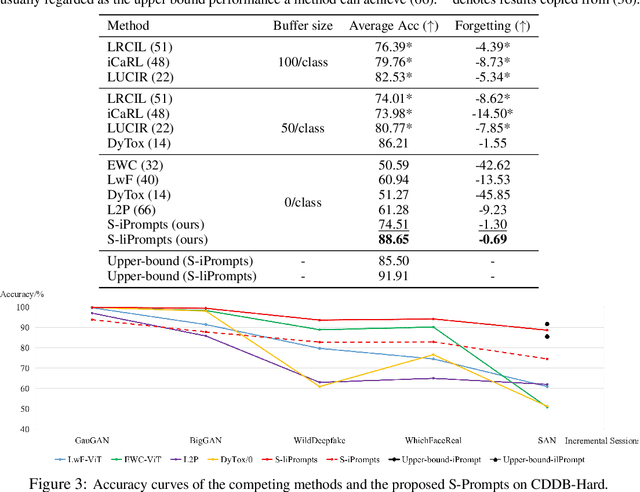
State-of-the-art deep neural networks are still struggling to address the catastrophic forgetting problem in continual learning. In this paper, we propose one simple paradigm (named as S-Prompting) and two concrete approaches to highly reduce the forgetting degree in one of the most typical continual learning scenarios, i.e., domain increment learning (DIL). The key idea of the paradigm is to learn prompts independently across domains with pre-trained transformers, avoiding the use of exemplars that commonly appear in conventional methods. This results in a win-win game where the prompting can achieve the best for each domain. The independent prompting across domains only requests one single cross-entropy loss for training and one simple K-NN operation as a domain identifier for inference. The learning paradigm derives an image prompt learning approach and a brand-new language-image prompt learning approach. Owning an excellent scalability (0.03% parameter increase per domain), the best of our approaches achieves a remarkable relative improvement (an average of about 30%) over the best of the state-of-the-art exemplar-free methods for three standard DIL tasks, and even surpasses the best of them relatively by about 6% in average when they use exemplars.