 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeave No Stone Unturned: Uncovering Holistic Audio-Visual Intrinsic Coherence for Deepfake Detection
Mar 25, 2026The rapid progress of generative AI has enabled hyper-realistic audio-visual deepfakes, intensifying threats to personal security and social trust. Most existing deepfake detectors rely either on uni-modal artifacts or audio-visual discrepancies, failing to jointly leverage both sources of information. Moreover, detectors that rely on generator-specific artifacts tend to exhibit degraded generalization when confronted with unseen forgeries. We argue that robust and generalizable detection should be grounded in intrinsic audio-visual coherence within and across modalities. Accordingly, we propose HAVIC, a Holistic Audio-Visual Intrinsic Coherence-based deepfake detector. HAVIC first learns priors of modality-specific structural coherence, inter-modal micro- and macro-coherence by pre-training on authentic videos. Based on the learned priors, HAVIC further performs holistic adaptive aggregation to dynamically fuse audio-visual features for deepfake detection. Additionally, we introduce HiFi-AVDF, a high-fidelity audio-visual deepfake dataset featuring both text-to-video and image-to-video forgeries from state-of-the-art commercial generators. Extensive experiments across several benchmarks demonstrate that HAVIC significantly outperforms existing state-of-the-art methods, achieving improvements of 9.39% AP and 9.37% AUC on the most challenging cross-dataset scenario. Our code and dataset are available at https://github.com/tuffy-studio/HAVIC.
OpenSDI: Spotting Diffusion-Generated Images in the Open World
Mar 25, 2025This paper identifies OpenSDI, a challenge for spotting diffusion-generated images in open-world settings. In response to this challenge, we define a new benchmark, the OpenSDI dataset (OpenSDID), which stands out from existing datasets due to its diverse use of large vision-language models that simulate open-world diffusion-based manipulations. Another outstanding feature of OpenSDID is its inclusion of both detection and localization tasks for images manipulated globally and locally by diffusion models. To address the OpenSDI challenge, we propose a Synergizing Pretrained Models (SPM) scheme to build up a mixture of foundation models. This approach exploits a collaboration mechanism with multiple pretrained foundation models to enhance generalization in the OpenSDI context, moving beyond traditional training by synergizing multiple pretrained models through prompting and attending strategies. Building on this scheme, we introduce MaskCLIP, an SPM-based model that aligns Contrastive Language-Image Pre-Training (CLIP) with Masked Autoencoder (MAE). Extensive evaluations on OpenSDID show that MaskCLIP significantly outperforms current state-of-the-art methods for the OpenSDI challenge, achieving remarkable relative improvements of 14.23% in IoU (14.11% in F1) and 2.05% in accuracy (2.38% in F1) compared to the second-best model in localization and detection tasks, respectively. Our dataset and code are available at https://github.com/iamwangyabin/OpenSDI.
A Benchmark for Incremental Micro-expression Recognition
Jan 31, 2025



Micro-expression recognition plays a pivotal role in understanding hidden emotions and has applications across various fields. Traditional recognition methods assume access to all training data at once, but real-world scenarios involve continuously evolving data streams. To respond to the requirement of adapting to new data while retaining previously learned knowledge, we introduce the first benchmark specifically designed for incremental micro-expression recognition. Our contributions include: Firstly, we formulate the incremental learning setting tailored for micro-expression recognition. Secondly, we organize sequential datasets with carefully curated learning orders to reflect real-world scenarios. Thirdly, we define two cross-evaluation-based testing protocols, each targeting distinct evaluation objectives. Finally, we provide six baseline methods and their corresponding evaluation results. This benchmark lays the groundwork for advancing incremental micro-expression recognition research. All code used in this study will be made publicly available.
Penny-Wise and Pound-Foolish in Deepfake Detection
Aug 15, 2024



The diffusion of deepfake technologies has sparked serious concerns about its potential misuse across various domains, prompting the urgent need for robust detection methods. Despite advancement, many current approaches prioritize short-term gains at expense of long-term effectiveness. This paper critiques the overly specialized approach of fine-tuning pre-trained models solely with a penny-wise objective on a single deepfake dataset, while disregarding the pound-wise balance for generalization and knowledge retention. To address this "Penny-Wise and Pound-Foolish" issue, we propose a novel learning framework (PoundNet) for generalization of deepfake detection on a pre-trained vision-language model. PoundNet incorporates a learnable prompt design and a balanced objective to preserve broad knowledge from upstream tasks (object classification) while enhancing generalization for downstream tasks (deepfake detection). We train PoundNet on a standard single deepfake dataset, following common practice in the literature. We then evaluate its performance across 10 public large-scale deepfake datasets with 5 main evaluation metrics-forming the largest benchmark test set for assessing the generalization ability of deepfake detection models, to our knowledge. The comprehensive benchmark evaluation demonstrates the proposed PoundNet is significantly less "Penny-Wise and Pound-Foolish", achieving a remarkable improvement of 19% in deepfake detection performance compared to state-of-the-art methods, while maintaining a strong performance of 63% on object classification tasks, where other deepfake detection models tend to be ineffective. Code and data are open-sourced at https://github.com/iamwangyabin/PoundNet.
Multi-modal Crowd Counting via Modal Emulation
Jul 28, 2024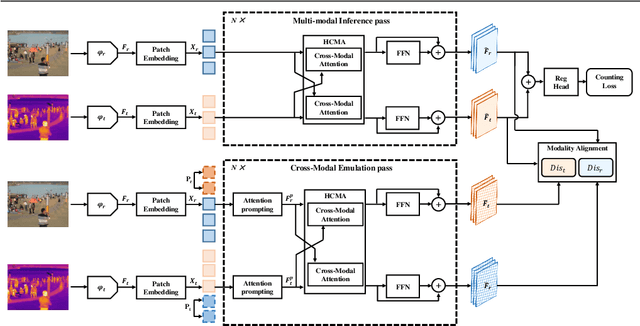
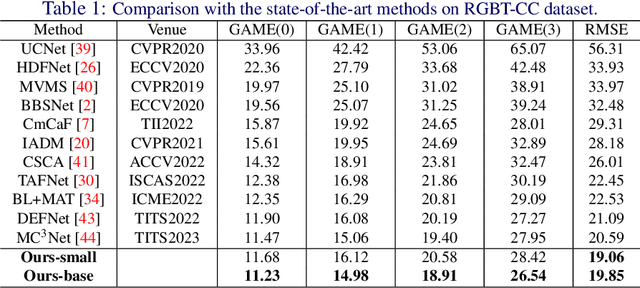
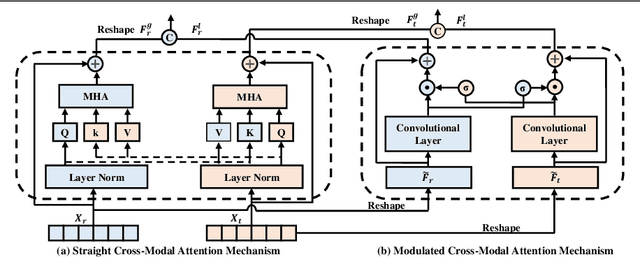
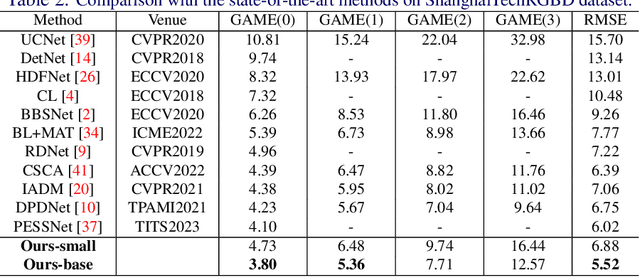
Multi-modal crowd counting is a crucial task that uses multi-modal cues to estimate the number of people in crowded scenes. To overcome the gap between different modalities, we propose a modal emulation-based two-pass multi-modal crowd-counting framework that enables efficient modal emulation, alignment, and fusion. The framework consists of two key components: a \emph{multi-modal inference} pass and a \emph{cross-modal emulation} pass. The former utilizes a hybrid cross-modal attention module to extract global and local information and achieve efficient multi-modal fusion. The latter uses attention prompting to coordinate different modalities and enhance multi-modal alignment. We also introduce a modality alignment module that uses an efficient modal consistency loss to align the outputs of the two passes and bridge the semantic gap between modalities. Extensive experiments on both RGB-Thermal and RGB-Depth counting datasets demonstrate its superior performance compared to previous methods. Code available at https://github.com/Mr-Monday/Multi-modal-Crowd-Counting-via-Modal-Emulation.
Prompt Customization for Continual Learning
Apr 28, 2024



Contemporary continual learning approaches typically select prompts from a pool, which function as supplementary inputs to a pre-trained model. However, this strategy is hindered by the inherent noise of its selection approach when handling increasing tasks. In response to these challenges, we reformulate the prompting approach for continual learning and propose the prompt customization (PC) method. PC mainly comprises a prompt generation module (PGM) and a prompt modulation module (PMM). In contrast to conventional methods that employ hard prompt selection, PGM assigns different coefficients to prompts from a fixed-sized pool of prompts and generates tailored prompts. Moreover, PMM further modulates the prompts by adaptively assigning weights according to the correlations between input data and corresponding prompts. We evaluate our method on four benchmark datasets for three diverse settings, including the class, domain, and task-agnostic incremental learning tasks. Experimental results demonstrate consistent improvement (by up to 16.2\%), yielded by the proposed method, over the state-of-the-art (SOTA) techniques.
Linguistic Profiling of Deepfakes: An Open Database for Next-Generation Deepfake Detection
Jan 04, 2024The emergence of text-to-image generative models has revolutionized the field of deepfakes, enabling the creation of realistic and convincing visual content directly from textual descriptions. However, this advancement presents considerably greater challenges in detecting the authenticity of such content. Existing deepfake detection datasets and methods often fall short in effectively capturing the extensive range of emerging deepfakes and offering satisfactory explanatory information for detection. To address the significant issue, this paper introduces a deepfake database (DFLIP-3K) for the development of convincing and explainable deepfake detection. It encompasses about 300K diverse deepfake samples from approximately 3K generative models, which boasts the largest number of deepfake models in the literature. Moreover, it collects around 190K linguistic footprints of these deepfakes. The two distinguished features enable DFLIP-3K to develop a benchmark that promotes progress in linguistic profiling of deepfakes, which includes three sub-tasks namely deepfake detection, model identification, and prompt prediction. The deepfake model and prompt are two essential components of each deepfake, and thus dissecting them linguistically allows for an invaluable exploration of trustworthy and interpretable evidence in deepfake detection, which we believe is the key for the next-generation deepfake detection. Furthermore, DFLIP-3K is envisioned as an open database that fosters transparency and encourages collaborative efforts to further enhance its growth. Our extensive experiments on the developed benchmark verify that our DFLIP-3K database is capable of serving as a standardized resource for evaluating and comparing linguistic-based deepfake detection, identification, and prompt prediction techniques.
Towards Practical Multi-Robot Hybrid Tasks Allocation for Autonomous Cleaning
Apr 04, 2023



Task allocation plays a vital role in multi-robot autonomous cleaning systems, where multiple robots work together to clean a large area. However, most current studies mainly focus on deterministic, single-task allocation for cleaning robots, without considering hybrid tasks in uncertain working environments. Moreover, there is a lack of datasets and benchmarks for relevant research. In this paper, to address these problems, we formulate multi-robot hybrid-task allocation under the uncertain cleaning environment as a robust optimization problem. Firstly, we propose a novel robust mixed-integer linear programming model with practical constraints including the task order constraint for different tasks and the ability constraints of hybrid robots. Secondly, we establish a dataset of \emph{100} instances made from floor plans, each of which has 2D manually-labeled images and a 3D model. Thirdly, we provide comprehensive results on the collected dataset using three traditional optimization approaches and a deep reinforcement learning-based solver. The evaluation results show that our solution meets the needs of multi-robot cleaning task allocation and the robust solver can protect the system from worst-case scenarios with little additional cost. The benchmark will be available at {https://github.com/iamwangyabin/Multi-robot-Cleaning-Task-Allocation}.
Remind of the Past: Incremental Learning with Analogical Prompts
Mar 24, 2023



Although data-free incremental learning methods are memory-friendly, accurately estimating and counteracting representation shifts is challenging in the absence of historical data. This paper addresses this thorny problem by proposing a novel incremental learning method inspired by human analogy capabilities. Specifically, we design an analogy-making mechanism to remap the new data into the old class by prompt tuning. It mimics the feature distribution of the target old class on the old model using only samples of new classes. The learnt prompts are further used to estimate and counteract the representation shift caused by fine-tuning for the historical prototypes. The proposed method sets up new state-of-the-art performance on four incremental learning benchmarks under both the class and domain incremental learning settings. It consistently outperforms data-replay methods by only saving feature prototypes for each class. It has almost hit the empirical upper bound by joint training on the Core50 benchmark. The code will be released at \url{https://github.com/ZhihengCV/A-Prompts}.
Benchmarking Deepart Detection
Feb 28, 2023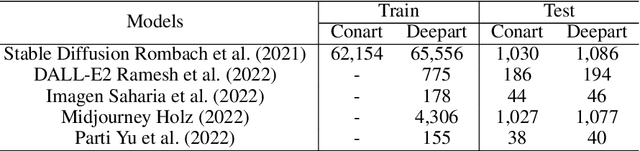

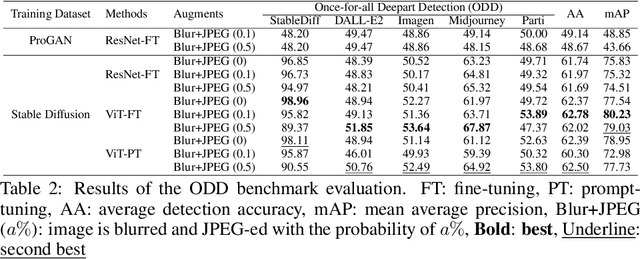
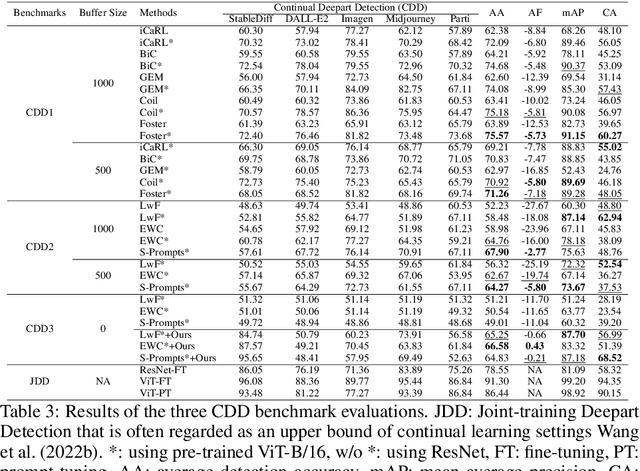
Deepfake technologies have been blurring the boundaries between the real and unreal, likely resulting in malicious events. By leveraging newly emerged deepfake technologies, deepfake researchers have been making a great upending to create deepfake artworks (deeparts), which are further closing the gap between reality and fantasy. To address potentially appeared ethics questions, this paper establishes a deepart detection database (DDDB) that consists of a set of high-quality conventional art images (conarts) and five sets of deepart images generated by five state-of-the-art deepfake models. This database enables us to explore once-for-all deepart detection and continual deepart detection. For the two new problems, we suggest four benchmark evaluations and four families of solutions on the constructed DDDB. The comprehensive study demonstrates the effectiveness of the proposed solutions on the established benchmark dataset, which is capable of paving a way to more interesting directions of deepart detection. The constructed benchmark dataset and the source code will be made publicly available.