 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehendEdit: A Comprehensive Dataset and Evaluation Framework for Multimodal Knowledge Editing
Dec 17, 2024



Large multimodal language models (MLLMs) have revolutionized natural language processing and visual understanding, but often contain outdated or inaccurate information. Current multimodal knowledge editing evaluations are limited in scope and potentially biased, focusing on narrow tasks and failing to assess the impact on in-domain samples. To address these issues, we introduce ComprehendEdit, a comprehensive benchmark comprising eight diverse tasks from multiple datasets. We propose two novel metrics: Knowledge Generalization Index (KGI) and Knowledge Preservation Index (KPI), which evaluate editing effects on in-domain samples without relying on AI-synthetic samples. Based on insights from our framework, we establish Hierarchical In-Context Editing (HICE), a baseline method employing a two-stage approach that balances performance across all metrics. This study provides a more comprehensive evaluation framework for multimodal knowledge editing, reveals unique challenges in this field, and offers a baseline method demonstrating improved performance. Our work opens new perspectives for future research and provides a foundation for developing more robust and effective editing techniques for MLLMs. The ComprehendEdit benchmark and implementation code are available at https://github.com/yaohui120/ComprehendEdit.
Effective Multi-Agent Deep Reinforcement Learning Control with Relative Entropy Regularization
Sep 26, 2023



In this paper, a novel Multi-agent Reinforcement Learning (MARL) approach, Multi-Agent Continuous Dynamic Policy Gradient (MACDPP) was proposed to tackle the issues of limited capability and sample efficiency in various scenarios controlled by multiple agents. It alleviates the inconsistency of multiple agents' policy updates by introducing the relative entropy regularization to the Centralized Training with Decentralized Execution (CTDE) framework with the Actor-Critic (AC) structure. Evaluated by multi-agent cooperation and competition tasks and traditional control tasks including OpenAI benchmarks and robot arm manipulation, MACDPP demonstrates significant superiority in learning capability and sample efficiency compared with both related multi-agent and widely implemented signal-agent baselines and therefore expands the potential of MARL in effectively learning challenging control scenarios.
Practical Probabilistic Model-based Deep Reinforcement Learning by Integrating Dropout Uncertainty and Trajectory Sampling
Sep 20, 2023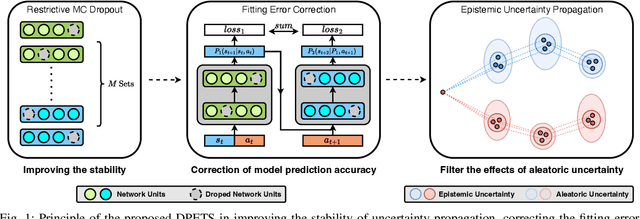
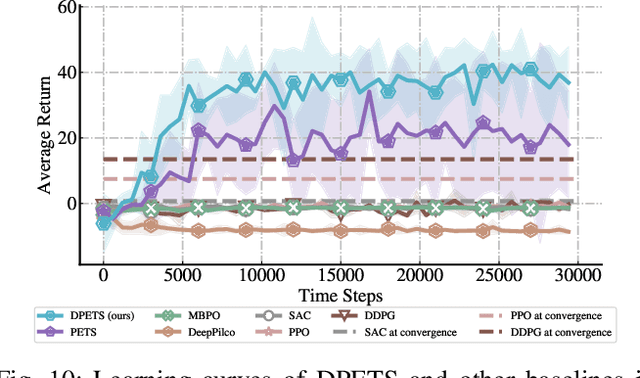
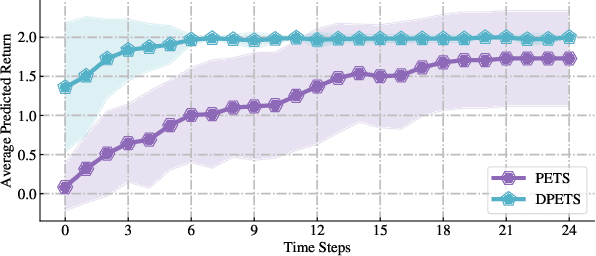
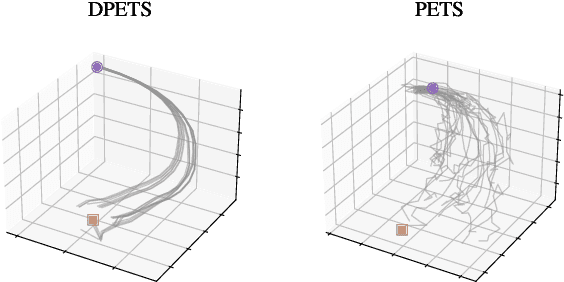
This paper addresses the prediction stability, prediction accuracy and control capability of the current probabilistic model-based reinforcement learning (MBRL) built on neural networks. A novel approach dropout-based probabilistic ensembles with trajectory sampling (DPETS) is proposed where the system uncertainty is stably predicted by combining the Monte-Carlo dropout and trajectory sampling in one framework. Its loss function is designed to correct the fitting error of neural networks for more accurate prediction of probabilistic models. The state propagation in its policy is extended to filter the aleatoric uncertainty for superior control capability. Evaluated by several Mujoco benchmark control tasks under additional disturbances and one practical robot arm manipulation task, DPETS outperforms related MBRL approaches in both average return and convergence velocity while achieving superior performance than well-known model-free baselines with significant sample efficiency. The open source code of DPETS is available at https://github.com/mrjun123/DPETS.
Remind of the Past: Incremental Learning with Analogical Prompts
Mar 24, 2023



Although data-free incremental learning methods are memory-friendly, accurately estimating and counteracting representation shifts is challenging in the absence of historical data. This paper addresses this thorny problem by proposing a novel incremental learning method inspired by human analogy capabilities. Specifically, we design an analogy-making mechanism to remap the new data into the old class by prompt tuning. It mimics the feature distribution of the target old class on the old model using only samples of new classes. The learnt prompts are further used to estimate and counteract the representation shift caused by fine-tuning for the historical prototypes. The proposed method sets up new state-of-the-art performance on four incremental learning benchmarks under both the class and domain incremental learning settings. It consistently outperforms data-replay methods by only saving feature prototypes for each class. It has almost hit the empirical upper bound by joint training on the Core50 benchmark. The code will be released at \url{https://github.com/ZhihengCV/A-Prompts}.
IA Planner: Motion Planning Using Instantaneous Analysis for Autonomous Vehicle in the Dense Dynamic Scenarios on Highways
Mar 19, 2021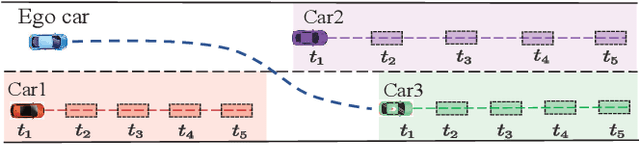
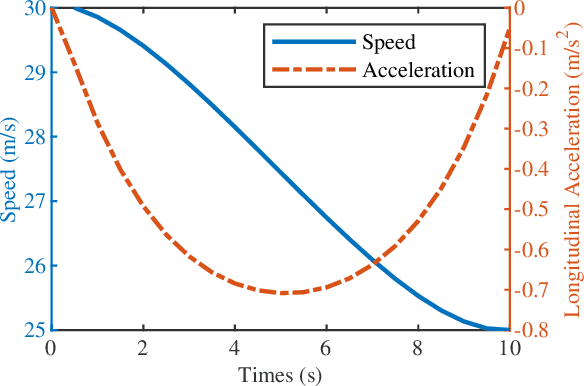
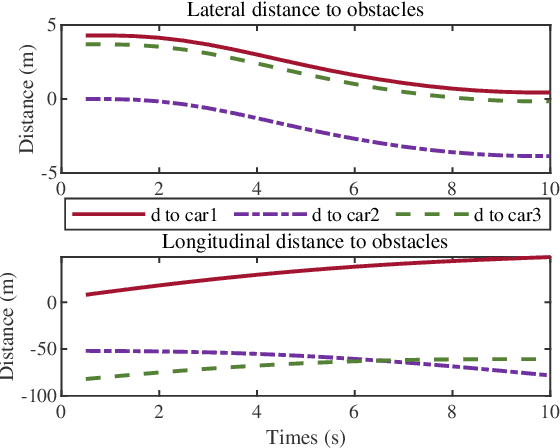

In dense and dynamic scenarios, planning a safe and comfortable trajectory is full of challenges when traffic participants are driving at high speed. The classic graph search and sampling methods first perform path planning and then configure the corresponding speed, which lacks a strategy to deal with the high-speed obstacles. Decoupling optimization methods perform motion planning in the S-L and S-T domains respectively. These methods require a large free configuration space to plan the lane change trajectory. In dense dynamic scenes, it is easy to cause the failure of trajectory planning and be cut in by others, causing slow driving speed and bring safety hazards. We analyze the collision relationship in the spatio-temporal domain, and propose an instantaneous analysis model which only analyzes the collision relationship at the same time. In the model, the collision-free constraints in 3D spatio-temporal domain is projected to the 2D space domain to remove redundant constraints and reduce computational complexity. Experimental results show that our method can plan a safe and comfortable lane-changing trajectory in dense dynamic scenarios. At the same time, it improves traffic efficiency and increases ride comfort.
Sparse Gaussian Process Based On Hat Basis Functions
Jun 15, 2020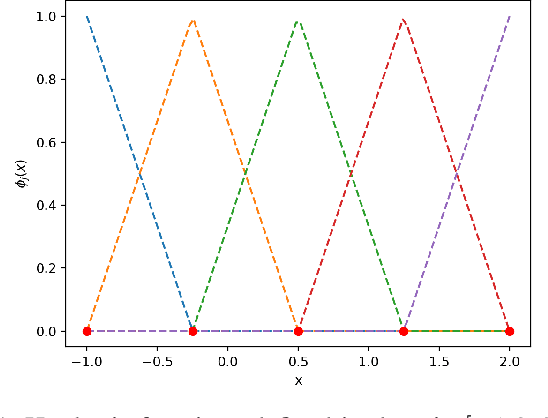
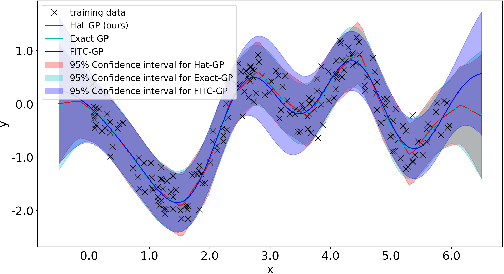
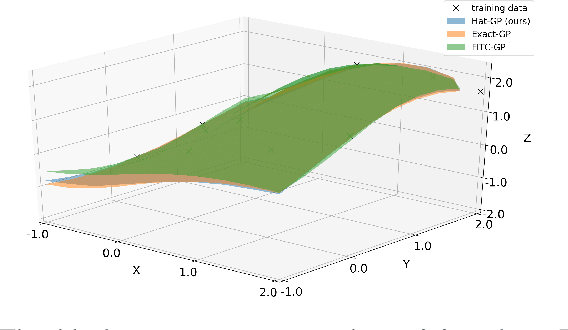
Gaussian process is one of the most popular non-parametric Bayesian methodologies for modeling the regression problem. It is completely determined by its mean and covariance functions. And its linear property makes it relatively straightforward to solve the prediction problem. Although Gaussian process has been successfully applied in many fields, it is still not enough to deal with physical systems that satisfy inequality constraints. This issue has been addressed by the so-called constrained Gaussian process in recent years. In this paper, we extend the core ideas of constrained Gaussian process. According to the range of training or test data, we redefine the hat basis functions mentioned in the constrained Gaussian process. Based on hat basis functions, we propose a new sparse Gaussian process method to solve the unconstrained regression problem. Similar to the exact Gaussian process and Gaussian process with Fully Independent Training Conditional approximation, our method obtains satisfactory approximate results on open-source datasets or analytical functions. In terms of performance, the proposed method reduces the overall computational complexity from $O(n^{3})$ computation in exact Gaussian process to $O(nm^{2})$ with $m$ hat basis functions and $n$ training data points.