 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehendEdit: A Comprehensive Dataset and Evaluation Framework for Multimodal Knowledge Editing
Dec 17, 2024



Large multimodal language models (MLLMs) have revolutionized natural language processing and visual understanding, but often contain outdated or inaccurate information. Current multimodal knowledge editing evaluations are limited in scope and potentially biased, focusing on narrow tasks and failing to assess the impact on in-domain samples. To address these issues, we introduce ComprehendEdit, a comprehensive benchmark comprising eight diverse tasks from multiple datasets. We propose two novel metrics: Knowledge Generalization Index (KGI) and Knowledge Preservation Index (KPI), which evaluate editing effects on in-domain samples without relying on AI-synthetic samples. Based on insights from our framework, we establish Hierarchical In-Context Editing (HICE), a baseline method employing a two-stage approach that balances performance across all metrics. This study provides a more comprehensive evaluation framework for multimodal knowledge editing, reveals unique challenges in this field, and offers a baseline method demonstrating improved performance. Our work opens new perspectives for future research and provides a foundation for developing more robust and effective editing techniques for MLLMs. The ComprehendEdit benchmark and implementation code are available at https://github.com/yaohui120/ComprehendEdit.
Reshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation
Jul 12, 2024
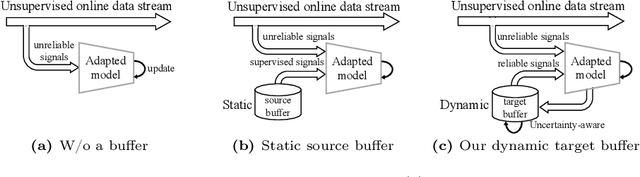


Continual Test-Time Adaptation (CTTA) involves adapting a pre-trained source model to continually changing unsupervised target domains. In this paper, we systematically analyze the challenges of this task: online environment, unsupervised nature, and the risks of error accumulation and catastrophic forgetting under continual domain shifts. To address these challenges, we reshape the online data buffering and organizing mechanism for CTTA. We propose an {uncertainty-aware buffering approach} to identify {and aggregate} significant samples with high certainty from the unsupervised, single-pass data stream. {Based on this}, we propose a graph-based class relation preservation constraint to overcome catastrophic forgetting. Furthermore, a pseudo-target replay objective is used to mitigate error accumulation. Extensive experiments demonstrate the superiority of our method in both segmentation and classification CTTA tasks. Code is available at \href{https://github.com/z1358/OBAO}{this https URL}.