 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding-MD: Grounded Video-language Pre-training for Open-World Moment Detection
Apr 20, 2025Temporal Action Detection and Moment Retrieval constitute two pivotal tasks in video understanding, focusing on precisely localizing temporal segments corresponding to specific actions or events. Recent advancements introduced Moment Detection to unify these two tasks, yet existing approaches remain confined to closed-set scenarios, limiting their applicability in open-world contexts. To bridge this gap, we present Grounding-MD, an innovative, grounded video-language pre-training framework tailored for open-world moment detection. Our framework incorporates an arbitrary number of open-ended natural language queries through a structured prompt mechanism, enabling flexible and scalable moment detection. Grounding-MD leverages a Cross-Modality Fusion Encoder and a Text-Guided Fusion Decoder to facilitate comprehensive video-text alignment and enable effective cross-task collaboration. Through large-scale pre-training on temporal action detection and moment retrieval datasets, Grounding-MD demonstrates exceptional semantic representation learning capabilities, effectively handling diverse and complex query conditions. Comprehensive evaluations across four benchmark datasets including ActivityNet, THUMOS14, ActivityNet-Captions, and Charades-STA demonstrate that Grounding-MD establishes new state-of-the-art performance in zero-shot and supervised settings in open-world moment detection scenarios. All source code and trained models will be released.
Reshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation
Jul 12, 2024
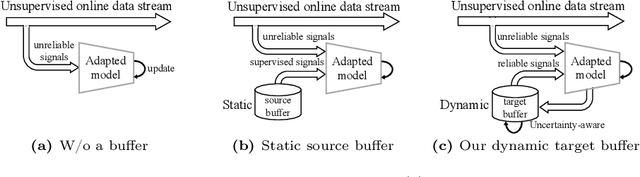


Continual Test-Time Adaptation (CTTA) involves adapting a pre-trained source model to continually changing unsupervised target domains. In this paper, we systematically analyze the challenges of this task: online environment, unsupervised nature, and the risks of error accumulation and catastrophic forgetting under continual domain shifts. To address these challenges, we reshape the online data buffering and organizing mechanism for CTTA. We propose an {uncertainty-aware buffering approach} to identify {and aggregate} significant samples with high certainty from the unsupervised, single-pass data stream. {Based on this}, we propose a graph-based class relation preservation constraint to overcome catastrophic forgetting. Furthermore, a pseudo-target replay objective is used to mitigate error accumulation. Extensive experiments demonstrate the superiority of our method in both segmentation and classification CTTA tasks. Code is available at \href{https://github.com/z1358/OBAO}{this https URL}.