 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding-MD: Grounded Video-language Pre-training for Open-World Moment Detection
Apr 20, 2025Temporal Action Detection and Moment Retrieval constitute two pivotal tasks in video understanding, focusing on precisely localizing temporal segments corresponding to specific actions or events. Recent advancements introduced Moment Detection to unify these two tasks, yet existing approaches remain confined to closed-set scenarios, limiting their applicability in open-world contexts. To bridge this gap, we present Grounding-MD, an innovative, grounded video-language pre-training framework tailored for open-world moment detection. Our framework incorporates an arbitrary number of open-ended natural language queries through a structured prompt mechanism, enabling flexible and scalable moment detection. Grounding-MD leverages a Cross-Modality Fusion Encoder and a Text-Guided Fusion Decoder to facilitate comprehensive video-text alignment and enable effective cross-task collaboration. Through large-scale pre-training on temporal action detection and moment retrieval datasets, Grounding-MD demonstrates exceptional semantic representation learning capabilities, effectively handling diverse and complex query conditions. Comprehensive evaluations across four benchmark datasets including ActivityNet, THUMOS14, ActivityNet-Captions, and Charades-STA demonstrate that Grounding-MD establishes new state-of-the-art performance in zero-shot and supervised settings in open-world moment detection scenarios. All source code and trained models will be released.
Triad: Empowering LMM-based Anomaly Detection with Vision Expert-guided Visual Tokenizer and Manufacturing Process
Mar 17, 2025
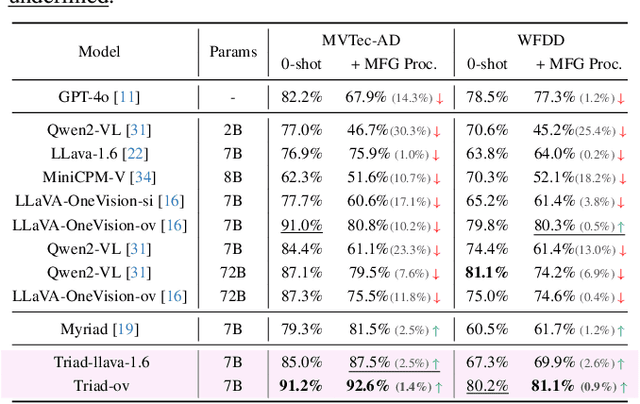
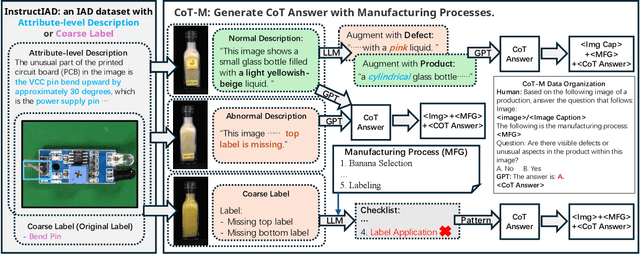
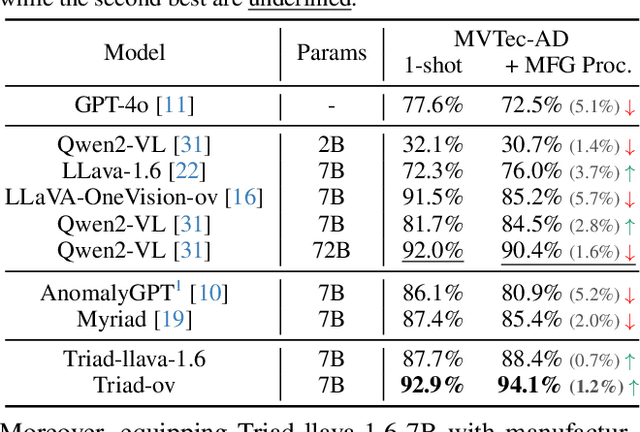
Although recent methods have tried to introduce large multimodal models (LMMs) into industrial anomaly detection (IAD), their generalization in the IAD field is far inferior to that for general purposes. We summarize the main reasons for this gap into two aspects. On one hand, general-purpose LMMs lack cognition of defects in the visual modality, thereby failing to sufficiently focus on defect areas. Therefore, we propose to modify the AnyRes structure of the LLaVA model, providing the potential anomalous areas identified by existing IAD models to the LMMs. On the other hand, existing methods mainly focus on identifying defects by learning defect patterns or comparing with normal samples, yet they fall short of understanding the causes of these defects. Considering that the generation of defects is closely related to the manufacturing process, we propose a manufacturing-driven IAD paradigm. An instruction-tuning dataset for IAD (InstructIAD) and a data organization approach for Chain-of-Thought with manufacturing (CoT-M) are designed to leverage the manufacturing process for IAD. Based on the above two modifications, we present Triad, a novel LMM-based method incorporating an expert-guided region-of-interest tokenizer and manufacturing process for industrial anomaly detection. Extensive experiments show that our Triad not only demonstrates competitive performance against current LMMs but also achieves further improved accuracy when equipped with manufacturing processes. Source code, training data, and pre-trained models will be publicly available at https://github.com/tzjtatata/Triad.
Deciphering the Chaos: Enhancing Jailbreak Attacks via Adversarial Prompt Translation
Oct 15, 2024Automatic adversarial prompt generation provides remarkable success in jailbreaking safely-aligned large language models (LLMs). Existing gradient-based attacks, while demonstrating outstanding performance in jailbreaking white-box LLMs, often generate garbled adversarial prompts with chaotic appearance. These adversarial prompts are difficult to transfer to other LLMs, hindering their performance in attacking unknown victim models. In this paper, for the first time, we delve into the semantic meaning embedded in garbled adversarial prompts and propose a novel method that "translates" them into coherent and human-readable natural language adversarial prompts. In this way, we can effectively uncover the semantic information that triggers vulnerabilities of the model and unambiguously transfer it to the victim model, without overlooking the adversarial information hidden in the garbled text, to enhance jailbreak attacks. It also offers a new approach to discovering effective designs for jailbreak prompts, advancing the understanding of jailbreak attacks. Experimental results demonstrate that our method significantly improves the success rate of jailbreak attacks against various safety-aligned LLMs and outperforms state-of-the-arts by large margins. With at most 10 queries, our method achieves an average attack success rate of 81.8% in attacking 7 commercial closed-source LLMs, including GPT and Claude-3 series, on HarmBench. Our method also achieves over 90% attack success rates against Llama-2-Chat models on AdvBench, despite their outstanding resistance to jailbreak attacks. Code at: https://github.com/qizhangli/Adversarial-Prompt-Translator.
Improved Generation of Adversarial Examples Against Safety-aligned LLMs
May 28, 2024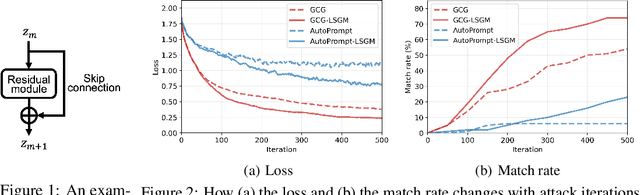
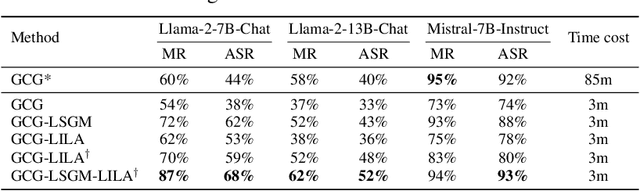

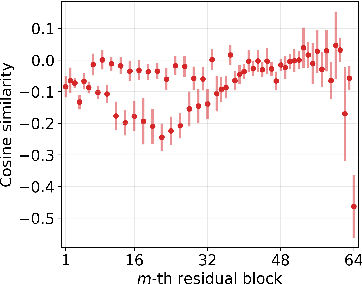
Despite numerous efforts to ensure large language models (LLMs) adhere to safety standards and produce harmless content, some successes have been achieved in bypassing these restrictions, known as jailbreak attacks against LLMs. Adversarial prompts generated using gradient-based methods exhibit outstanding performance in performing jailbreak attacks automatically. Nevertheless, due to the discrete nature of texts, the input gradient of LLMs struggles to precisely reflect the magnitude of loss change that results from token replacements in the prompt, leading to limited attack success rates against safety-aligned LLMs, even in the white-box setting. In this paper, we explore a new perspective on this problem, suggesting that it can be alleviated by leveraging innovations inspired in transfer-based attacks that were originally proposed for attacking black-box image classification models. For the first time, we appropriate the ideologies of effective methods among these transfer-based attacks, i.e., Skip Gradient Method and Intermediate Level Attack, for improving the effectiveness of automatically generated adversarial examples against white-box LLMs. With appropriate adaptations, we inject these ideologies into gradient-based adversarial prompt generation processes and achieve significant performance gains without introducing obvious computational cost. Meanwhile, by discussing mechanisms behind the gains, new insights are drawn, and proper combinations of these methods are also developed. Our empirical results show that the developed combination achieves >30% absolute increase in attack success rates compared with GCG for attacking the Llama-2-7B-Chat model on AdvBench.
Towards Evaluating Transfer-based Attacks Systematically, Practically, and Fairly
Nov 02, 2023

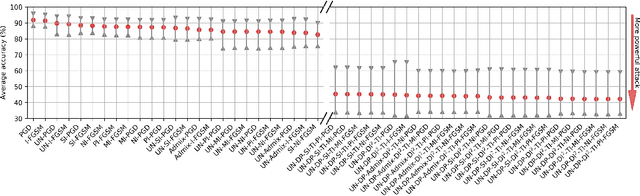

The adversarial vulnerability of deep neural networks (DNNs) has drawn great attention due to the security risk of applying these models in real-world applications. Based on transferability of adversarial examples, an increasing number of transfer-based methods have been developed to fool black-box DNN models whose architecture and parameters are inaccessible. Although tremendous effort has been exerted, there still lacks a standardized benchmark that could be taken advantage of to compare these methods systematically, fairly, and practically. Our investigation shows that the evaluation of some methods needs to be more reasonable and more thorough to verify their effectiveness, to avoid, for example, unfair comparison and insufficient consideration of possible substitute/victim models. Therefore, we establish a transfer-based attack benchmark (TA-Bench) which implements 30+ methods. In this paper, we evaluate and compare them comprehensively on 25 popular substitute/victim models on ImageNet. New insights about the effectiveness of these methods are gained and guidelines for future evaluations are provided. Code at: https://github.com/qizhangli/TA-Bench.
DualAug: Exploiting Additional Heavy Augmentation with OOD Data Rejection
Oct 16, 2023Data augmentation is a dominant method for reducing model overfitting and improving generalization. Most existing data augmentation methods tend to find a compromise in augmenting the data, \textit{i.e.}, increasing the amplitude of augmentation carefully to avoid degrading some data too much and doing harm to the model performance. We delve into the relationship between data augmentation and model performance, revealing that the performance drop with heavy augmentation comes from the presence of out-of-distribution (OOD) data. Nonetheless, as the same data transformation has different effects for different training samples, even for heavy augmentation, there remains part of in-distribution data which is beneficial to model training. Based on the observation, we propose a novel data augmentation method, named \textbf{DualAug}, to keep the augmentation in distribution as much as possible at a reasonable time and computational cost. We design a data mixing strategy to fuse augmented data from both the basic- and the heavy-augmentation branches. Extensive experiments on supervised image classification benchmarks show that DualAug improve various automated data augmentation method. Moreover, the experiments on semi-supervised learning and contrastive self-supervised learning demonstrate that our DualAug can also improve related method. Code is available at \href{https://github.com/shuguang99/DualAug}{https://github.com/shuguang99/DualAug}.
Improving Transferability of Adversarial Examples via Bayesian Attacks
Jul 21, 2023

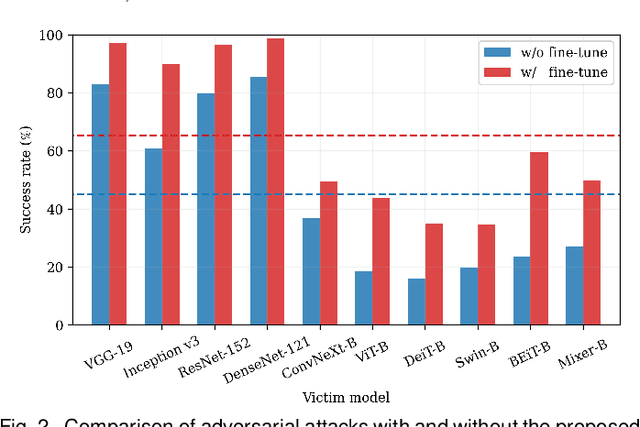
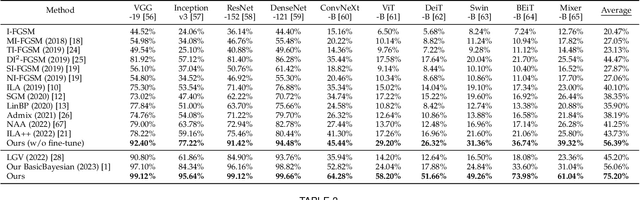
This paper presents a substantial extension of our work published at ICLR. Our ICLR work advocated for enhancing transferability in adversarial examples by incorporating a Bayesian formulation into model parameters, which effectively emulates the ensemble of infinitely many deep neural networks, while, in this paper, we introduce a novel extension by incorporating the Bayesian formulation into the model input as well, enabling the joint diversification of both the model input and model parameters. Our empirical findings demonstrate that: 1) the combination of Bayesian formulations for both the model input and model parameters yields significant improvements in transferability; 2) by introducing advanced approximations of the posterior distribution over the model input, adversarial transferability achieves further enhancement, surpassing all state-of-the-arts when attacking without model fine-tuning. Moreover, we propose a principled approach to fine-tune model parameters in such an extended Bayesian formulation. The derived optimization objective inherently encourages flat minima in the parameter space and input space. Extensive experiments demonstrate that our method achieves a new state-of-the-art on transfer-based attacks, improving the average success rate on ImageNet and CIFAR-10 by 19.14% and 2.08%, respectively, when comparing with our ICLR basic Bayesian method. We will make our code publicly available.
Improving Adversarial Transferability via Intermediate-level Perturbation Decay
May 09, 2023Intermediate-level attacks that attempt to perturb feature representations following an adversarial direction drastically have shown favorable performance in crafting transferable adversarial examples. Existing methods in this category are normally formulated with two separate stages, where a directional guide is required to be determined at first and the scalar projection of the intermediate-level perturbation onto the directional guide is enlarged thereafter. The obtained perturbation deviates from the guide inevitably in the feature space, and it is revealed in this paper that such a deviation may lead to sub-optimal attack. To address this issue, we develop a novel intermediate-level method that crafts adversarial examples within a single stage of optimization. In particular, the proposed method, named intermediate-level perturbation decay (ILPD), encourages the intermediate-level perturbation to be in an effective adversarial direction and to possess a great magnitude simultaneously. In-depth discussion verifies the effectiveness of our method. Experimental results show that it outperforms state-of-the-arts by large margins in attacking various victim models on ImageNet (+10.07% on average) and CIFAR-10 (+3.88% on average). Our code is at https://github.com/qizhangli/ILPD-attack.
Making Substitute Models More Bayesian Can Enhance Transferability of Adversarial Examples
Mar 02, 2023The transferability of adversarial examples across deep neural networks (DNNs) is the crux of many black-box attacks. Many prior efforts have been devoted to improving the transferability via increasing the diversity in inputs of some substitute models. In this paper, by contrast, we opt for the diversity in substitute models and advocate to attack a Bayesian model for achieving desirable transferability. Deriving from the Bayesian formulation, we develop a principled strategy for possible finetuning, which can be combined with many off-the-shelf Gaussian posterior approximations over DNN parameters. Extensive experiments have been conducted to verify the effectiveness of our method, on common benchmark datasets, and the results demonstrate that our method outperforms recent state-of-the-arts by large margins (roughly 19% absolute increase in average attack success rate on ImageNet), and, by combining with these recent methods, further performance gain can be obtained. Our code: https://github.com/qizhangli/MoreBayesian-attack.
Adversarial Contrastive Learning via Asymmetric InfoNCE
Jul 18, 2022
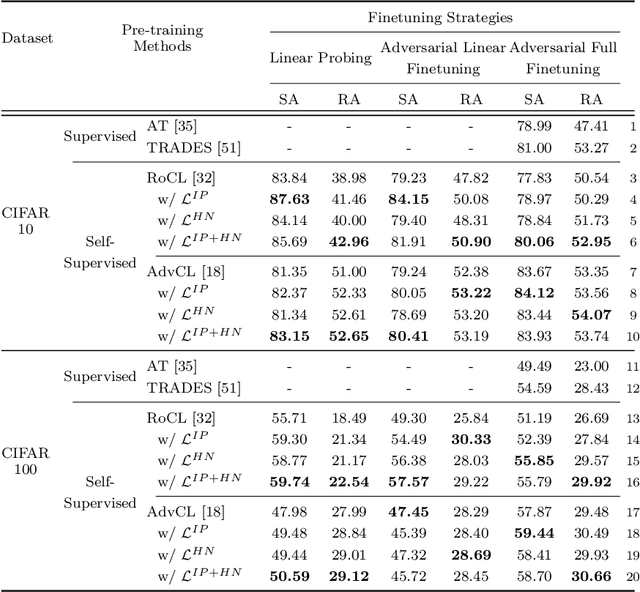
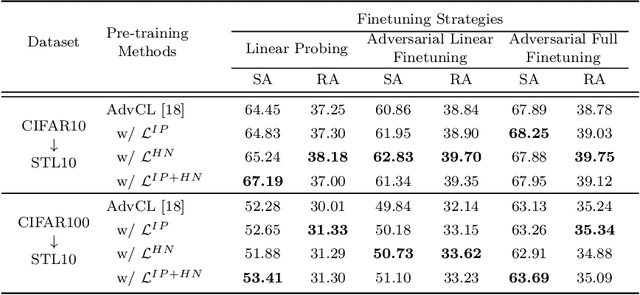
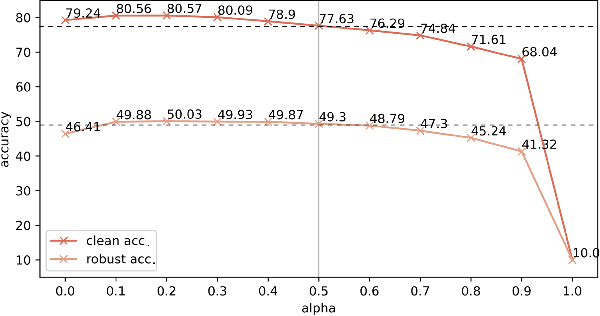
Contrastive learning (CL) has recently been applied to adversarial learning tasks. Such practice considers adversarial samples as additional positive views of an instance, and by maximizing their agreements with each other, yields better adversarial robustness. However, this mechanism can be potentially flawed, since adversarial perturbations may cause instance-level identity confusion, which can impede CL performance by pulling together different instances with separate identities. To address this issue, we propose to treat adversarial samples unequally when contrasted, with an asymmetric InfoNCE objective ($A-InfoNCE$) that allows discriminating considerations of adversarial samples. Specifically, adversaries are viewed as inferior positives that induce weaker learning signals, or as hard negatives exhibiting higher contrast to other negative samples. In the asymmetric fashion, the adverse impacts of conflicting objectives between CL and adversarial learning can be effectively mitigated. Experiments show that our approach consistently outperforms existing Adversarial CL methods across different finetuning schemes without additional computational cost. The proposed A-InfoNCE is also a generic form that can be readily extended to other CL methods. Code is available at https://github.com/yqy2001/A-InfoNCE.