 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre VLMs Lost Between Sky and Space? LinkS$^2$Bench for UAV-Satellite Dynamic Cross-View Spatial Intelligence
Apr 02, 2026Synergistic spatial intelligence between UAVs and satellites is indispensable for emergency response and security operations, as it uniquely integrates macro-scale global coverage with dynamic, real-time local perception. However, the capacity of Vision-Language Models (VLMs) to master this complex interplay remains largely unexplored. This gap persists primarily because existing benchmarks are confined to isolated Unmanned Aerial Vehicle (UAV) videos or static satellite imagery, failing to evaluate the dynamic local-to-global spatial mapping essential for comprehensive cross-view reasoning. To bridge this gap, we introduce LinkS$^2$Bench, the first comprehensive benchmark designed to evaluate VLMs' wide-area, dynamic cross-view spatial intelligence. LinkS$^2$Bench links 1,022 minutes of dynamic UAV footage with high-resolution satellite imagery covering over 200 km$^2$. Through an LMM-assisted pipeline and rigorous human annotation, we constructed 17.9k high-quality question-answer pairs comprising 12 fine-grained tasks across four dimensions: perception, localization, relation, and reasoning. Evaluations of 18 representative VLMs reveal a substantial gap compared to human baselines, identifying accurate cross-view dynamic alignment as the critical bottleneck. To alleviate this, we design a Cross-View Alignment Adapter, demonstrating that explicit alignment significantly improves model performance. Furthermore, fine-tuning experiments underscore the potential of LinkS$^2$Bench in advancing VLM adaptation for complex spatial reasoning.
A3R: Agentic Affordance Reasoning via Cross-Dimensional Evidence in 3D Gaussian Scenes
Apr 02, 2026Affordance reasoning in 3D Gaussian scenes aims to identify the region that supports the action specified by a given text instruction in complex environments. Existing methods typically cast this problem as one-shot prediction from static scene observations, assuming sufficient evidence is already available for reasoning. However, in complex 3D scenes, many failure cases arise not from weak prediction capacity, but from incomplete task-relevant evidence under fixed observations. To address this limitation, we reformulate fine-grained affordance reasoning as a sequential evidence acquisition process, where ambiguity is progressively reduced through complementary 3D geometric and 2D semantic evidence. Building on this formulation, we propose A3R, an agentic affordance reasoning framework that enables an MLLM-based policy to iteratively select evidence acquisition actions and update the affordance belief through cross-dimensional evidence acquisition. To optimize such sequential decision making, we further introduce a GRPO-based policy learning strategy that improves evidence acquisition efficiency and reasoning accuracy. Extensive experiments on scene-level benchmarks show that A3R consistently surpasses static one-shot baselines, demonstrating the advantage of agentic cross-dimensional evidence acquisition for fine-grained affordance reasoning in complex 3D Gaussian scenes.
Scaling Dense Event-Stream Pretraining from Visual Foundation Models
Mar 04, 2026Learning versatile, fine-grained representations from irregular event streams is pivotal yet nontrivial, primarily due to the heavy annotation that hinders scalability in dataset size, semantic richness, and application scope. To mitigate this dilemma, we launch a novel self-supervised pretraining method that distills visual foundation models (VFMs) to push the boundaries of event representation at scale. Specifically, we curate an extensive synchronized image-event collection to amplify cross-modal alignment. Nevertheless, due to inherent mismatches in sparsity and granularity between image-event domains, existing distillation paradigms are prone to semantic collapse in event representations, particularly at high resolutions. To bridge this gap, we propose to extend the alignment objective to semantic structures provided off-the-shelf by VFMs, indicating a broader receptive field and stronger supervision. The key ingredient of our method is a structure-aware distillation loss that grounds higher-quality image-event correspondences for alignment, optimizing dense event representations. Extensive experiments demonstrate that our approach takes a great leap in downstream benchmarks, significantly surpassing traditional methods and existing pretraining techniques. This breakthrough manifests in enhanced generalization, superior data efficiency and elevated transferability.
On the Rate-Distortion-Complexity Tradeoff for Semantic Communication
Feb 16, 2026Semantic communication is a novel communication paradigm that focuses on conveying the user's intended meaning rather than the bit-wise transmission of source signals. One of the key challenges is to effectively represent and extract the semantic meaning of any given source signals. While deep learning (DL)-based solutions have shown promising results in extracting implicit semantic information from a wide range of sources, existing work often overlooks the high computational complexity inherent in both model training and inference for the DL-based encoder and decoder. To bridge this gap, this paper proposes a rate-distortion-complexity (RDC) framework which extends the classical rate-distortion theory by incorporating the constraints on semantic distance, including both the traditional bit-wise distortion metric and statistical difference-based divergence metric, and complexity measure, adopted from the theory of minimum description length and information bottleneck. We derive the closed-form theoretical results of the minimum achievable rate under given constraints on semantic distance and complexity for both Gaussian and binary semantic sources. Our theoretical results show a fundamental three-way tradeoff among achievable rate, semantic distance, and model complexity. Extensive experiments on real-world image and video datasets validate this tradeoff and further demonstrate that our information-theoretic complexity measure effectively correlates with practical computational costs, guiding efficient system design in resource-constrained scenarios.
SANet: A Semantic-aware Agentic AI Networking Framework for Cross-layer Optimization in 6G
Dec 27, 2025Agentic AI networking (AgentNet) is a novel AI-native networking paradigm in which a large number of specialized AI agents collaborate to perform autonomous decision-making, dynamic environmental adaptation, and complex missions. It has the potential to facilitate real-time network management and optimization functions, including self-configuration, self-optimization, and self-adaptation across diverse and complex environments. This paper proposes SANet, a novel semantic-aware AgentNet architecture for wireless networks that can infer the semantic goal of the user and automatically assign agents associated with different layers of the network to fulfill the inferred goal. Motivated by the fact that AgentNet is a decentralized framework in which collaborating agents may generally have different and even conflicting objectives, we formulate the decentralized optimization of SANet as a multi-agent multi-objective problem, and focus on finding the Pareto-optimal solution for agents with distinct and potentially conflicting objectives. We propose three novel metrics for evaluating SANet. Furthermore, we develop a model partition and sharing (MoPS) framework in which large models, e.g., deep learning models, of different agents can be partitioned into shared and agent-specific parts that are jointly constructed and deployed according to agents' local computational resources. Two decentralized optimization algorithms are proposed. We derive theoretical bounds and prove that there exists a three-way tradeoff among optimization, generalization, and conflicting errors. We develop an open-source RAN and core network-based hardware prototype that implements agents to interact with three different layers of the network. Experimental results show that the proposed framework achieved performance gains of up to 14.61% while requiring only 44.37% of FLOPs required by state-of-the-art algorithms.
SITP: A High-Reliability Semantic Information Transport Protocol Without Retransmission for Semantic Communication
Dec 10, 2025With the evolution of 6G networks, modern communication systems are facing unprecedented demands for high reliability and low latency. However, conventional transport protocols are designed for bit-level reliability, failing to meet the semantic robustness requirements. To address this limitation, this paper proposes a novel Semantic Information Transport Protocol (SITP), which achieves TCP-level reliability and UDP level latency by verifying only packet headers while retaining potentially corrupted payloads for semantic decoding. Building upon SITP, a cross-layer analytical model is established to quantify packet-loss probability across the physical, data-link, network, transport, and application layers. The model provides a unified probabilistic formulation linking signal noise rate (SNR) and packet-loss rate, offering theoretical foundation into end-to-end semantic transmission. Furthermore, a cross-image feature interleaving mechanism is developed to mitigate consecutive burst losses by redistributing semantic features across multiple correlated images, thereby enhancing robustness in burst-fade channels. Extensive experiments show that SITP offers lower latency than TCP with comparable reliability at low SNRs, while matching UDP-level latency and delivering superior reconstruction quality. In addition, the proposed cross-image semantic interleaving mechanism further demonstrates its effectiveness in mitigating degradation caused by bursty packet losses.
NOC4SC: A Bandwidth-Efficient Multi-User Semantic Communication Framework for Interference-Resilient Transmission
Dec 10, 2025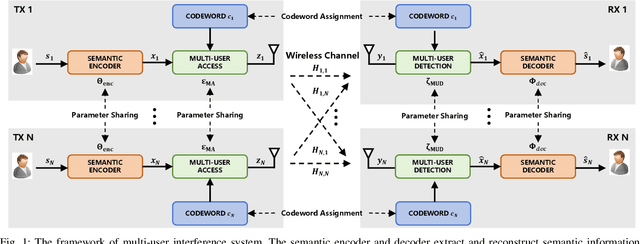
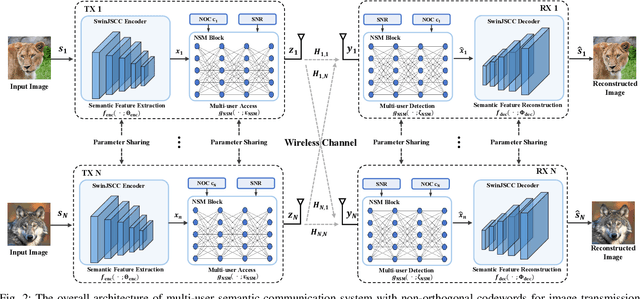
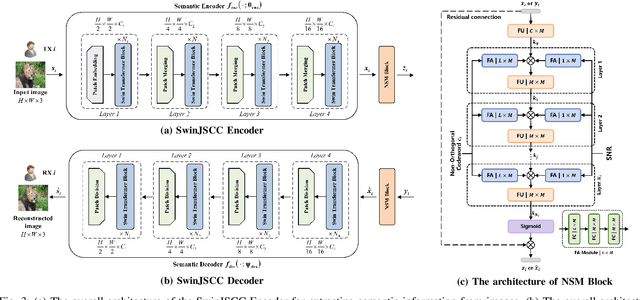
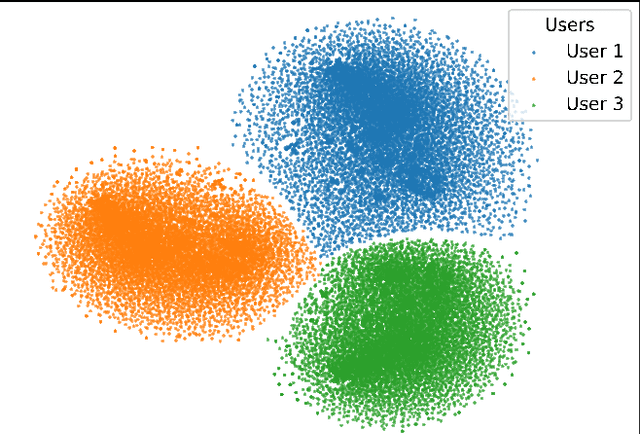
With the explosive growth of connected devices and emerging applications, current wireless networks are encountering unprecedented demands for massive user access, where the inter-user interference has become a critical challenge to maintaining high quality of service (QoS) in multi-user communication systems. To tackle this issue, we propose a bandwidth-efficient semantic communication paradigm termed Non-Orthogonal Codewords for Semantic Communication (NOC4SC), which enables simultaneous same-frequency transmission without spectrum spreading. By leveraging the Swin Transformer, the proposed NOC4SC framework enables each user to independently extract semantic features through a unified encoder-decoder architecture with shared network parameters across all users, which ensures that the user's data remains protected from unauthorized decoding. Furthermore, we introduce an adaptive NOC and SNR Modulation (NSM) block, which employs deep learning to dynamically regulate SNR and generate approximately orthogonal semantic features within distinct feature subspaces, thereby effectively mitigating inter-user interference. Extensive experiments demonstrate the proposed NOC4SC achieves comparable performance to the DeepJSCC-PNOMA and outperforms other multi-user SemCom baseline methods.
Parse Graph-Based Visual-Language Interaction for Human Pose Estimation
Sep 09, 2025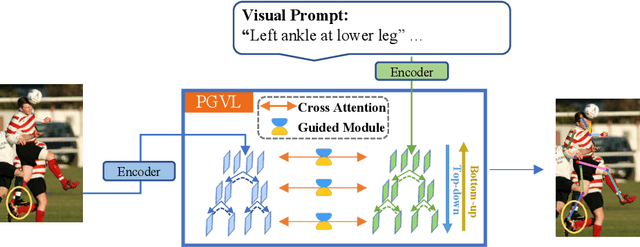

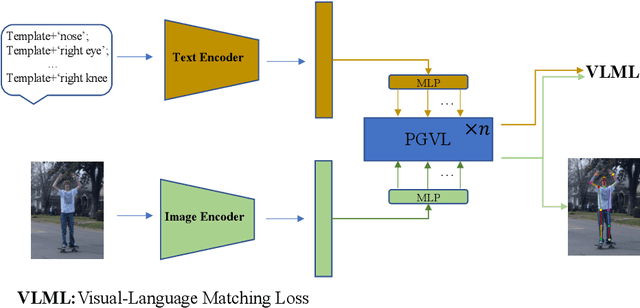

Parse graphs boost human pose estimation (HPE) by integrating context and hierarchies, yet prior work mostly focuses on single modality modeling, ignoring the potential of multimodal fusion. Notably, language offers rich HPE priors like spatial relations for occluded scenes, but existing visual-language fusion via global feature integration weakens occluded region responses and causes alignment and location failures. To address this issue, we propose Parse Graph-based Visual-Language interaction (PGVL) with a core novel Guided Module (GM). In PGVL, low-level nodes focus on local features, maximizing the maintenance of responses in occluded areas and high-level nodes integrate global features to infer occluded or invisible parts. GM enables high semantic nodes to guide the feature update of low semantic nodes that have undergone cross attention. It ensuring effective fusion of diverse information. PGVL includes top-down decomposition and bottom-up composition. In the first stage, modality specific parse graphs are constructed. Next stage. recursive bidirectional cross-attention is used, purified by GM. We also design network based on PGVL. The PGVL and our network is validated on major pose estimation datasets. We will release the code soon.
Optimizing Multi-Modal Trackers via Sensitivity-aware Regularized Tuning
Aug 24, 2025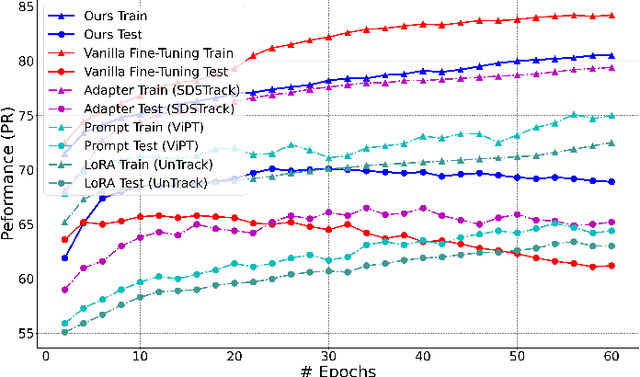

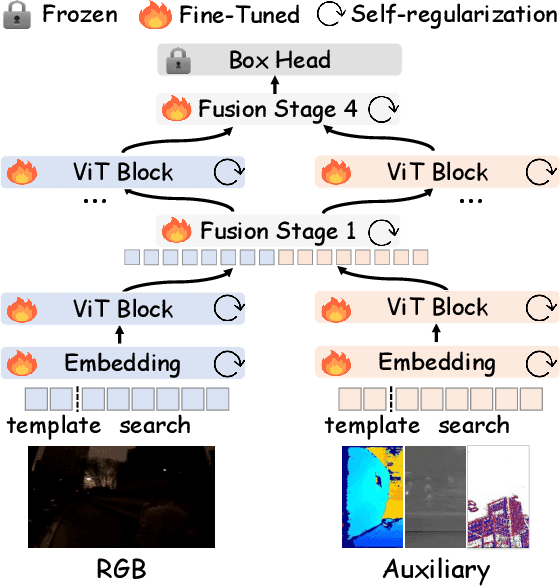
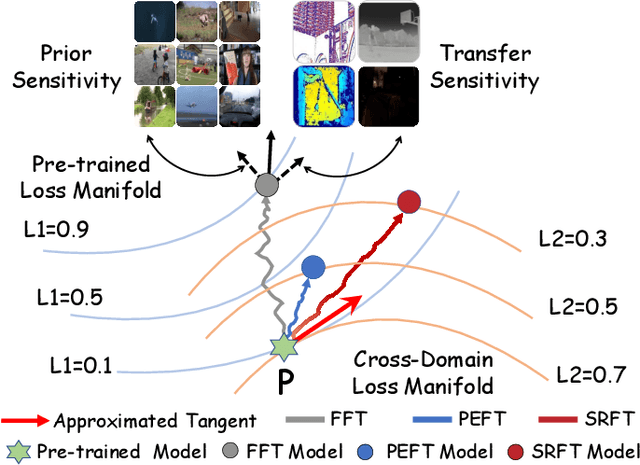
This paper tackles the critical challenge of optimizing multi-modal trackers by effectively adapting the pre-trained models for RGB data. Existing fine-tuning paradigms oscillate between excessive freedom and over-restriction, both leading to a suboptimal plasticity-stability trade-off. To mitigate this dilemma, we propose a novel sensitivity-aware regularized tuning framework, which delicately refines the learning process by incorporating intrinsic parameter sensitivities. Through a comprehensive investigation from pre-trained to multi-modal contexts, we identify that parameters sensitive to pivotal foundational patterns and cross-domain shifts are primary drivers of this issue. Specifically, we first analyze the tangent space of pre-trained weights to measure and orient prior sensitivities, dedicated to preserving generalization. Then, we further explore transfer sensitivities during the tuning phase, emphasizing adaptability and stability. By incorporating these sensitivities as regularization terms, our method significantly enhances the transferability across modalities. Extensive experiments showcase the superior performance of the proposed method, surpassing current state-of-the-art techniques across various multi-modal tracking. The source code and models will be publicly available at https://github.com/zhiwen-xdu/SRTrack.
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Jul 31, 20253D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.