 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Exposure Correction for Spatially Non-uniform Degradation
Apr 05, 2026Real-world exposure correction is fundamentally challenged by spatially non-uniform degradations, where diverse exposure errors frequently coexist within a single image. However, existing exposure correction methods are still largely developed under a predominantly uniform assumption. Architecturally, they typically rely on globally aggregated modulation signals that capture only the overall exposure trend. From the optimization perspective, conventional reconstruction losses are usually derived under a shared global scale, thus overlooking the spatially varying correction demands across regions. To address these limitations, we propose a new exposure correction paradigm explicitly designed for spatial non-uniformity. Specifically, we introduce a Spatial Signal Encoder to predict spatially adaptive modulation weights, which are used to guide multiple look-up tables for image transformation, together with an HSL-based compensation module for improved color fidelity. Beyond the architectural design, we propose an uncertainty-inspired non-uniform loss that dynamically allocates the optimization focus based on local restoration uncertainties, better matching the heterogeneous nature of real-world exposure errors. Extensive experiments demonstrate that our method achieves superior qualitative and quantitative performance compared with state-of-the-art methods. Code is available at https://github.com/FALALAS/rethinkingEC.
Are VLMs Lost Between Sky and Space? LinkS$^2$Bench for UAV-Satellite Dynamic Cross-View Spatial Intelligence
Apr 02, 2026Synergistic spatial intelligence between UAVs and satellites is indispensable for emergency response and security operations, as it uniquely integrates macro-scale global coverage with dynamic, real-time local perception. However, the capacity of Vision-Language Models (VLMs) to master this complex interplay remains largely unexplored. This gap persists primarily because existing benchmarks are confined to isolated Unmanned Aerial Vehicle (UAV) videos or static satellite imagery, failing to evaluate the dynamic local-to-global spatial mapping essential for comprehensive cross-view reasoning. To bridge this gap, we introduce LinkS$^2$Bench, the first comprehensive benchmark designed to evaluate VLMs' wide-area, dynamic cross-view spatial intelligence. LinkS$^2$Bench links 1,022 minutes of dynamic UAV footage with high-resolution satellite imagery covering over 200 km$^2$. Through an LMM-assisted pipeline and rigorous human annotation, we constructed 17.9k high-quality question-answer pairs comprising 12 fine-grained tasks across four dimensions: perception, localization, relation, and reasoning. Evaluations of 18 representative VLMs reveal a substantial gap compared to human baselines, identifying accurate cross-view dynamic alignment as the critical bottleneck. To alleviate this, we design a Cross-View Alignment Adapter, demonstrating that explicit alignment significantly improves model performance. Furthermore, fine-tuning experiments underscore the potential of LinkS$^2$Bench in advancing VLM adaptation for complex spatial reasoning.
SDesc3D: Towards Layout-Aware 3D Indoor Scene Generation from Short Descriptions
Apr 02, 20263D indoor scene generation conditioned on short textual descriptions provides a promising avenue for interactive 3D environment construction without the need for labor-intensive layout specification. Despite recent progress in text-conditioned 3D scene generation, existing works suffer from poor physical plausibility and insufficient detail richness in such semantic condensation cases, largely due to their reliance on explicit semantic cues about compositional objects and their spatial relationships. This limitation highlights the need for enhanced 3D reasoning capabilities, particularly in terms of prior integration and spatial anchoring.Motivated by this, we propose SDesc3D, a short-text conditioned 3D indoor scene generation framework, that leverages multi-view structural priors and regional functionality implications to enable 3D layout reasoning under sparse textual guidance.Specifically, we introduce a Multi-view scene prior augmentation that enriches underspecified textual inputs with aggregated multi-view structural knowledge, shifting from inaccessible semantic relation cues to multi-view relational prior aggregation. Building on this, we design a Functionality-aware layout grounding, employing regional functionality grounding for implicit spatial anchors and conducting hierarchical layout reasoning to enhance scene organization and semantic plausibility.Furthermore, an Iterative reflection-rectification scheme is employed for progressive structural plausibility refinement via self-rectification.Extensive experiments show that our method outperforms existing approaches on short-text conditioned 3D indoor scene generation.Code will be publicly available.
A3R: Agentic Affordance Reasoning via Cross-Dimensional Evidence in 3D Gaussian Scenes
Apr 02, 2026Affordance reasoning in 3D Gaussian scenes aims to identify the region that supports the action specified by a given text instruction in complex environments. Existing methods typically cast this problem as one-shot prediction from static scene observations, assuming sufficient evidence is already available for reasoning. However, in complex 3D scenes, many failure cases arise not from weak prediction capacity, but from incomplete task-relevant evidence under fixed observations. To address this limitation, we reformulate fine-grained affordance reasoning as a sequential evidence acquisition process, where ambiguity is progressively reduced through complementary 3D geometric and 2D semantic evidence. Building on this formulation, we propose A3R, an agentic affordance reasoning framework that enables an MLLM-based policy to iteratively select evidence acquisition actions and update the affordance belief through cross-dimensional evidence acquisition. To optimize such sequential decision making, we further introduce a GRPO-based policy learning strategy that improves evidence acquisition efficiency and reasoning accuracy. Extensive experiments on scene-level benchmarks show that A3R consistently surpasses static one-shot baselines, demonstrating the advantage of agentic cross-dimensional evidence acquisition for fine-grained affordance reasoning in complex 3D Gaussian scenes.
Dual Distillation for Few-Shot Anomaly Detection
Mar 02, 2026Anomaly detection is a critical task in computer vision with profound implications for medical imaging, where identifying pathologies early can directly impact patient outcomes. While recent unsupervised anomaly detection approaches show promise, they require substantial normal training data and struggle to generalize across anatomical contexts. We introduce D$^2$4FAD, a novel dual distillation framework for few-shot anomaly detection that identifies anomalies in previously unseen tasks using only a small number of normal reference images. Our approach leverages a pre-trained encoder as a teacher network to extract multi-scale features from both support and query images, while a student decoder learns to distill knowledge from the teacher on query images and self-distill on support images. We further propose a learn-to-weight mechanism that dynamically assesses the reference value of each support image conditioned on the query, optimizing anomaly detection performance. To evaluate our method, we curate a comprehensive benchmark dataset comprising 13,084 images across four organs, four imaging modalities, and five disease categories. Extensive experiments demonstrate that D$^2$4FAD significantly outperforms existing approaches, establishing a new state-of-the-art in few-shot medical anomaly detection. Code is available at https://github.com/ttttqz/D24FAD.
Towards Syn-to-Real IQA: A Novel Perspective on Reshaping Synthetic Data Distributions
Jan 01, 2026Blind Image Quality Assessment (BIQA) has advanced significantly through deep learning, but the scarcity of large-scale labeled datasets remains a challenge. While synthetic data offers a promising solution, models trained on existing synthetic datasets often show limited generalization ability. In this work, we make a key observation that representations learned from synthetic datasets often exhibit a discrete and clustered pattern that hinders regression performance: features of high-quality images cluster around reference images, while those of low-quality images cluster based on distortion types. Our analysis reveals that this issue stems from the distribution of synthetic data rather than model architecture. Consequently, we introduce a novel framework SynDR-IQA, which reshapes synthetic data distribution to enhance BIQA generalization. Based on theoretical derivations of sample diversity and redundancy's impact on generalization error, SynDR-IQA employs two strategies: distribution-aware diverse content upsampling, which enhances visual diversity while preserving content distribution, and density-aware redundant cluster downsampling, which balances samples by reducing the density of densely clustered areas. Extensive experiments across three cross-dataset settings (synthetic-to-authentic, synthetic-to-algorithmic, and synthetic-to-synthetic) demonstrate the effectiveness of our method. The code is available at https://github.com/Li-aobo/SynDR-IQA.
LoopExpose: An Unsupervised Framework for Arbitrary-Length Exposure Correction
Nov 08, 2025Exposure correction is essential for enhancing image quality under challenging lighting conditions. While supervised learning has achieved significant progress in this area, it relies heavily on large-scale labeled datasets, which are difficult to obtain in practical scenarios. To address this limitation, we propose a pseudo label-based unsupervised method called LoopExpose for arbitrary-length exposure correction. A nested loop optimization strategy is proposed to address the exposure correction problem, where the correction model and pseudo-supervised information are jointly optimized in a two-level framework. Specifically, the upper-level trains a correction model using pseudo-labels generated through multi-exposure fusion at the lower level. A feedback mechanism is introduced where corrected images are fed back into the fusion process to refine the pseudo-labels, creating a self-reinforcing learning loop. Considering the dominant role of luminance calibration in exposure correction, a Luminance Ranking Loss is introduced to leverage the relative luminance ordering across the input sequence as a self-supervised constraint. Extensive experiments on different benchmark datasets demonstrate that LoopExpose achieves superior exposure correction and fusion performance, outperforming existing state-of-the-art unsupervised methods. Code is available at https://github.com/FALALAS/LoopExpose.
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Jul 31, 20253D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
Controlled Data Rebalancing in Multi-Task Learning for Real-World Image Super-Resolution
Jun 05, 2025Real-world image super-resolution (Real-SR) is a challenging problem due to the complex degradation patterns in low-resolution images. Unlike approaches that assume a broadly encompassing degradation space, we focus specifically on achieving an optimal balance in how SR networks handle different degradation patterns within a fixed degradation space. We propose an improved paradigm that frames Real-SR as a data-heterogeneous multi-task learning problem, our work addresses task imbalance in the paradigm through coordinated advancements in task definition, imbalance quantification, and adaptive data rebalancing. Specifically, we introduce a novel task definition framework that segments the degradation space by setting parameter-specific boundaries for degradation operators, effectively reducing the task quantity while maintaining task discrimination. We then develop a focal loss based multi-task weighting mechanism that precisely quantifies task imbalance dynamics during model training. Furthermore, to prevent sporadic outlier samples from dominating the gradient optimization of the shared multi-task SR model, we strategically convert the quantified task imbalance into controlled data rebalancing through deliberate regulation of task-specific training volumes. Extensive quantitative and qualitative experiments demonstrate that our method achieves consistent superiority across all degradation tasks.
EgoSplat: Open-Vocabulary Egocentric Scene Understanding with Language Embedded 3D Gaussian Splatting
Mar 14, 2025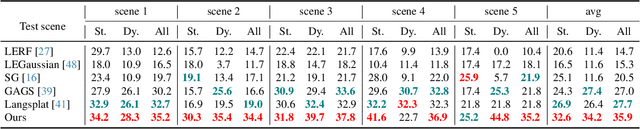
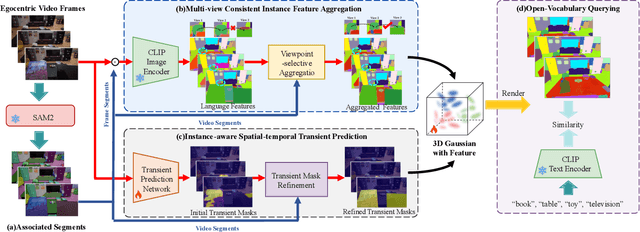
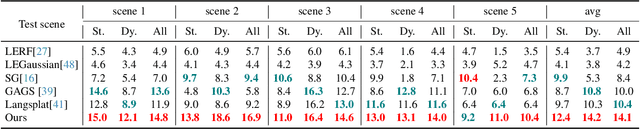
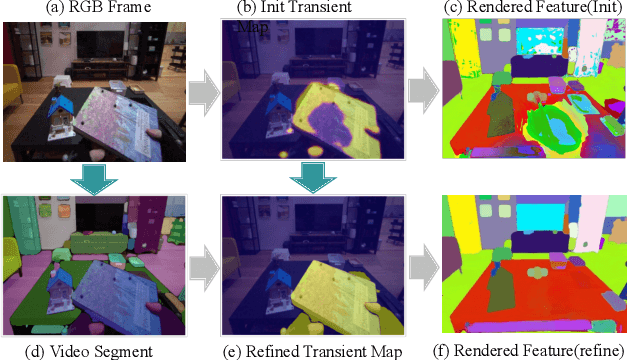
Egocentric scenes exhibit frequent occlusions, varied viewpoints, and dynamic interactions compared to typical scene understanding tasks. Occlusions and varied viewpoints can lead to multi-view semantic inconsistencies, while dynamic objects may act as transient distractors, introducing artifacts into semantic feature modeling. To address these challenges, we propose EgoSplat, a language-embedded 3D Gaussian Splatting framework for open-vocabulary egocentric scene understanding. A multi-view consistent instance feature aggregation method is designed to leverage the segmentation and tracking capabilities of SAM2 to selectively aggregate complementary features across views for each instance, ensuring precise semantic representation of scenes. Additionally, an instance-aware spatial-temporal transient prediction module is constructed to improve spatial integrity and temporal continuity in predictions by incorporating spatial-temporal associations across multi-view instances, effectively reducing artifacts in the semantic reconstruction of egocentric scenes. EgoSplat achieves state-of-the-art performance in both localization and segmentation tasks on two datasets, outperforming existing methods with a 8.2% improvement in localization accuracy and a 3.7% improvement in segmentation mIoU on the ADT dataset, and setting a new benchmark in open-vocabulary egocentric scene understanding. The code will be made publicly available.