 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecouple and Rectify: Semantics-Preserving Structural Enhancement for Open-Vocabulary Remote Sensing Segmentation
Apr 02, 2026Open-vocabulary semantic segmentation in the remote sensing (RS) field requires both language-aligned recognition and fine-grained spatial delineation. Although CLIP offers robust semantic generalization, its global-aligned visual representations inherently struggle to capture structural details. Recent methods attempt to compensate for this by introducing RS-pretrained DINO features. However, these methods treat CLIP representations as a monolithic semantic space and cannot localize where structural enhancement is required, failing to effectively delineate boundaries while risking the disruption of CLIP's semantic integrity. To address this limitation, we propose DR-Seg, a novel decouple-and-rectify framework in this paper. Our method is motivated by the key observation that CLIP feature channels exhibit distinct functional heterogeneity rather than forming a uniform semantic space. Building on this insight, DR-Seg decouples CLIP features into semantics-dominated and structure-dominated subspaces, enabling targeted structural enhancement by DINO without distorting language-aligned semantics. Subsequently, a prior-driven graph rectification module injects high-fidelity structural priors under DINO guidance to form a refined branch, while an uncertainty-guided adaptive fusion module dynamically integrates this refined branch with the original CLIP branch for final prediction. Comprehensive experiments across eight benchmarks demonstrate that DR-Seg establishes a new state-of-the-art.
Resonance4D: Frequency-Domain Motion Supervision for Preset-Free Physical Parameter Learning in 4D Dynamic Physical Scene Simulation
Apr 02, 2026Physics-driven 4D dynamic simulation from static 3D scenes remains constrained by an overlooked contradiction: reliable motion supervision often relies on online video diffusion or optical-flow pipelines whose computational cost exceeds that of the simulator itself. Existing methods further simplify inverse physical modeling by optimizing only partial material parameters, limiting realism in scenes with complex materials and dynamics. We present Resonance4D, a physics-driven 4D dynamic simulation framework that couples 3D Gaussian Splatting with the Material Point Method through lightweight yet physically expressive supervision. Our key insight is that dynamic consistency can be enforced without dense temporal generation by jointly constraining motion in complementary domains. To this end, we introduce Dual-domain Motion Supervision (DMS), which combines spatial structural consistency for local deformation with frequency-domain spectral consistency for oscillatory and global dynamic patterns, substantially reducing training cost and memory overhead while preserving physically meaningful motion cues. To enable stable full-parameter physical recovery, we further combine zero-shot text-prompted segmentation with simulation-guided initialization to automatically decompose Gaussians into object-part-level regions and support joint optimization of full material parameters. Experiments on both synthetic and real scenes show that Resonance4D achieves strong physical fidelity and motion consistency while reducing peak GPU memory from over 35\,GB to around 20\,GB, enabling high-fidelity physics-driven 4D simulation on a single consumer-grade GPU.
A3R: Agentic Affordance Reasoning via Cross-Dimensional Evidence in 3D Gaussian Scenes
Apr 02, 2026Affordance reasoning in 3D Gaussian scenes aims to identify the region that supports the action specified by a given text instruction in complex environments. Existing methods typically cast this problem as one-shot prediction from static scene observations, assuming sufficient evidence is already available for reasoning. However, in complex 3D scenes, many failure cases arise not from weak prediction capacity, but from incomplete task-relevant evidence under fixed observations. To address this limitation, we reformulate fine-grained affordance reasoning as a sequential evidence acquisition process, where ambiguity is progressively reduced through complementary 3D geometric and 2D semantic evidence. Building on this formulation, we propose A3R, an agentic affordance reasoning framework that enables an MLLM-based policy to iteratively select evidence acquisition actions and update the affordance belief through cross-dimensional evidence acquisition. To optimize such sequential decision making, we further introduce a GRPO-based policy learning strategy that improves evidence acquisition efficiency and reasoning accuracy. Extensive experiments on scene-level benchmarks show that A3R consistently surpasses static one-shot baselines, demonstrating the advantage of agentic cross-dimensional evidence acquisition for fine-grained affordance reasoning in complex 3D Gaussian scenes.
Explore Intrinsic Geometry for Query-based Tiny and Oriented Object Detector with Momentum-based Bipartite Matching
Feb 14, 2026Recent query-based detectors have achieved remarkable progress, yet their performance remains constrained when handling objects with arbitrary orientations, especially for tiny objects capturing limited texture information. This limitation primarily stems from the underutilization of intrinsic geometry during pixel-based feature decoding and the occurrence of inter-stage matching inconsistency caused by stage-wise bipartite matching. To tackle these challenges, we present IGOFormer, a novel query-based oriented object detector that explicitly integrates intrinsic geometry into feature decoding and enhances inter-stage matching stability. Specifically, we design an Intrinsic Geometry-aware Decoder, which enhances the object-related features conditioned on an object query by injecting complementary geometric embeddings extrapolated from their correlations to capture the geometric layout of the object, thereby offering a critical geometric insight into its orientation. Meanwhile, a Momentum-based Bipartite Matching scheme is developed to adaptively aggregate historical matching costs by formulating an exponential moving average with query-specific smoothing factors, effectively preventing conflicting supervisory signals arising from inter-stage matching inconsistency. Extensive experiments and ablation studies demonstrate the superiority of our IGOFormer for aerial oriented object detection, achieving an AP$_{50}$ score of 78.00\% on DOTA-V1.0 using Swin-T backbone under the single-scale setting. The code will be made publicly available.
Meta knowledge assisted Evolutionary Neural Architecture Search
Apr 30, 2025Evolutionary computation (EC)-based neural architecture search (NAS) has achieved remarkable performance in the automatic design of neural architectures. However, the high computational cost associated with evaluating searched architectures poses a challenge for these methods, and a fixed form of learning rate (LR) schedule means greater information loss on diverse searched architectures. This paper introduces an efficient EC-based NAS method to solve these problems via an innovative meta-learning framework. Specifically, a meta-learning-rate (Meta-LR) scheme is used through pretraining to obtain a suitable LR schedule, which guides the training process with lower information loss when evaluating each individual. An adaptive surrogate model is designed through an adaptive threshold to select the potential architectures in a few epochs and then evaluate the potential architectures with complete epochs. Additionally, a periodic mutation operator is proposed to increase the diversity of the population, which enhances the generalizability and robustness. Experiments on CIFAR-10, CIFAR-100, and ImageNet1K datasets demonstrate that the proposed method achieves high performance comparable to that of many state-of-the-art peer methods, with lower computational cost and greater robustness.
Masked Image Modeling Boosting Semi-Supervised Semantic Segmentation
Nov 14, 2024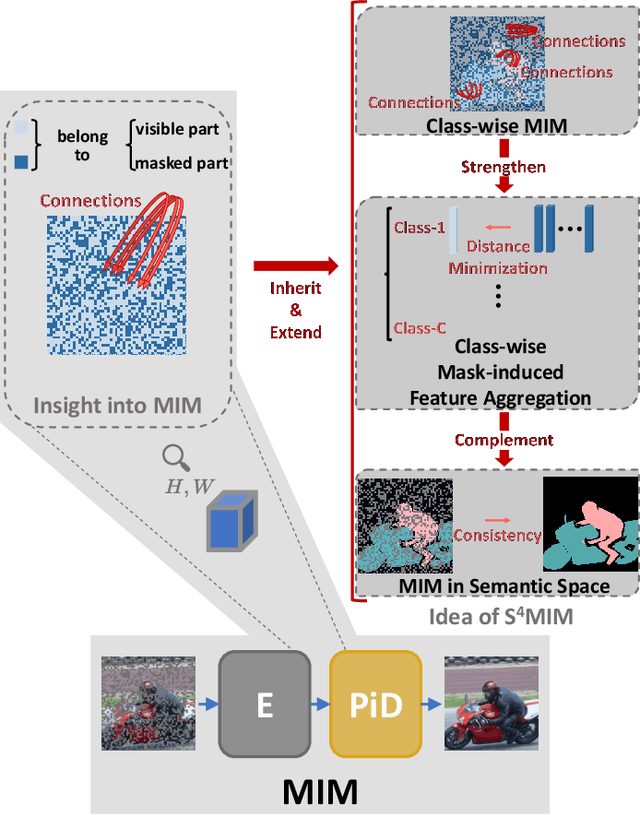
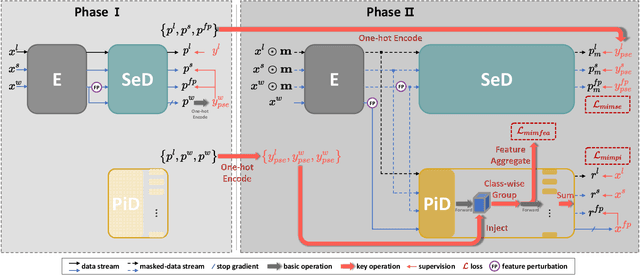
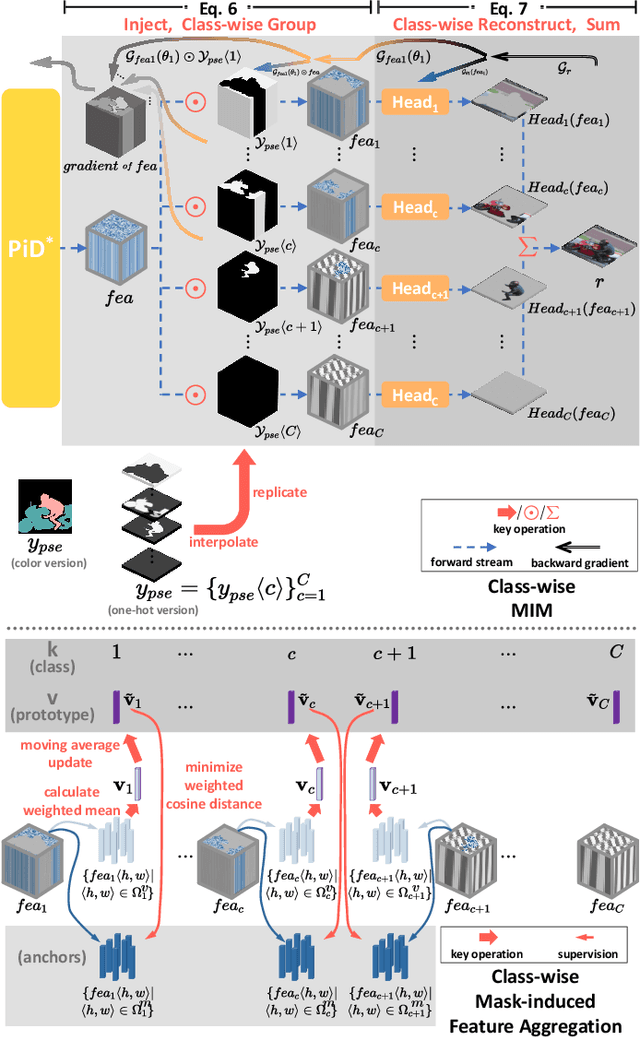
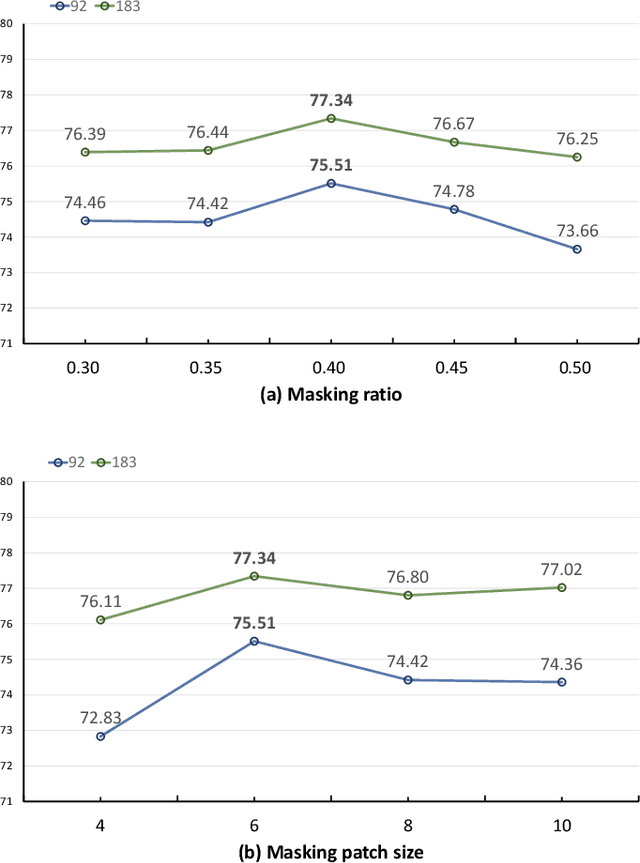
In view of the fact that semi- and self-supervised learning share a fundamental principle, effectively modeling knowledge from unlabeled data, various semi-supervised semantic segmentation methods have integrated representative self-supervised learning paradigms for further regularization. However, the potential of the state-of-the-art generative self-supervised paradigm, masked image modeling, has been scarcely studied. This paradigm learns the knowledge through establishing connections between the masked and visible parts of masked image, during the pixel reconstruction process. By inheriting and extending this insight, we successfully leverage masked image modeling to boost semi-supervised semantic segmentation. Specifically, we introduce a novel class-wise masked image modeling that independently reconstructs different image regions according to their respective classes. In this way, the mask-induced connections are established within each class, mitigating the semantic confusion that arises from plainly reconstructing images in basic masked image modeling. To strengthen these intra-class connections, we further develop a feature aggregation strategy that minimizes the distances between features corresponding to the masked and visible parts within the same class. Additionally, in semantic space, we explore the application of masked image modeling to enhance regularization. Extensive experiments conducted on well-known benchmarks demonstrate that our approach achieves state-of-the-art performance. The code will be available at https://github.com/haoxt/S4MIM.
Multi-Teacher Multi-Objective Meta-Learning for Zero-Shot Hyperspectral Band Selection
Jun 12, 2024



Band selection plays a crucial role in hyperspectral image classification by removing redundant and noisy bands and retaining discriminative ones. However, most existing deep learning-based methods are aimed at dealing with a specific band selection dataset, and need to retrain parameters for new datasets, which significantly limits their generalizability.To address this issue, a novel multi-teacher multi-objective meta-learning network (M$^3$BS) is proposed for zero-shot hyperspectral band selection. In M$^3$BS, a generalizable graph convolution network (GCN) is constructed to generate dataset-agnostic base, and extract compatible meta-knowledge from multiple band selection tasks. To enhance the ability of meta-knowledge extraction, multiple band selection teachers are introduced to provide diverse high-quality experiences.strategy Finally, subsequent classification tasks are attached and jointly optimized with multi-teacher band selection tasks through multi-objective meta-learning in an end-to-end trainable way. Multi-objective meta-learning guarantees to coordinate diverse optimization objectives automatically and adapt to various datasets simultaneously. Once the optimization is accomplished, the acquired meta-knowledge can be directly transferred to unseen datasets without any retraining or fine-tuning. Experimental results demonstrate the effectiveness and efficiency of our proposed method on par with state-of-the-art baselines for zero-shot hyperspectral band selection.
DynamicKD: An Effective Knowledge Distillation via Dynamic Entropy Correction-Based Distillation for Gap Optimizing
May 09, 2023The knowledge distillation uses a high-performance teacher network to guide the student network. However, the performance gap between the teacher and student networks can affect the student's training. This paper proposes a novel knowledge distillation algorithm based on dynamic entropy correction to reduce the gap by adjusting the student instead of the teacher. Firstly, the effect of changing the output entropy (short for output information entropy) in the student on the distillation loss is analyzed in theory. This paper shows that correcting the output entropy can reduce the gap. Then, a knowledge distillation algorithm based on dynamic entropy correction is created, which can correct the output entropy in real-time with an entropy controller updated dynamically by the distillation loss. The proposed algorithm is validated on the CIFAR100 and ImageNet. The comparison with various state-of-the-art distillation algorithms shows impressive results, especially in the experiment on the CIFAR100 regarding teacher-student pair resnet32x4-resnet8x4. The proposed algorithm raises 2.64 points over the traditional distillation algorithm and 0.87 points over the state-of-the-art algorithm CRD in classification accuracy, demonstrating its effectiveness and efficiency.
An EMO Joint Pruning with Multiple Sub-networks: Fast and Effect
Mar 28, 2023The network pruning algorithm based on evolutionary multi-objective (EMO) can balance the pruning rate and performance of the network. However, its population-based nature often suffers from the complex pruning optimization space and the highly resource-consuming pruning structure verification process, which limits its application. To this end, this paper proposes an EMO joint pruning with multiple sub-networks (EMO-PMS) to reduce space complexity and resource consumption. First, a divide-and-conquer EMO network pruning framework is proposed, which decomposes the complex EMO pruning task on the whole network into easier sub-tasks on multiple sub-networks. On the one hand, this decomposition reduces the pruning optimization space and decreases the optimization difficulty; on the other hand, the smaller network structure converges faster, so the computational resource consumption of the proposed algorithm is lower. Secondly, a sub-network training method based on cross-network constraints is designed so that the sub-network can process the features generated by the previous one through feature constraints. This method allows sub-networks optimized independently to collaborate better and improves the overall performance of the pruned network. Finally, a multiple sub-networks joint pruning method based on EMO is proposed. For one thing, it can accurately measure the feature processing capability of the sub-networks with the pre-trained feature selector. For another, it can combine multi-objective pruning results on multiple sub-networks through global performance impairment ranking to design a joint pruning scheme. The proposed algorithm is validated on three datasets with different challenging. Compared with fifteen advanced pruning algorithms, the experiment results exhibit the effectiveness and efficiency of the proposed algorithm.
RSBNet: One-Shot Neural Architecture Search for A Backbone Network in Remote Sensing Image Recognition
Dec 07, 2021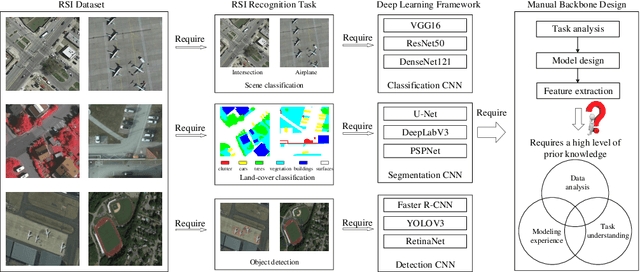
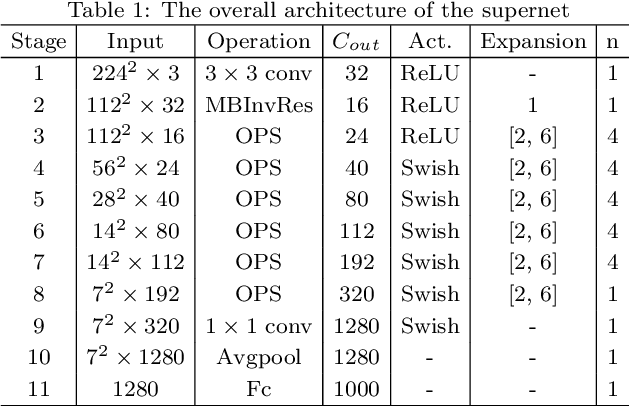
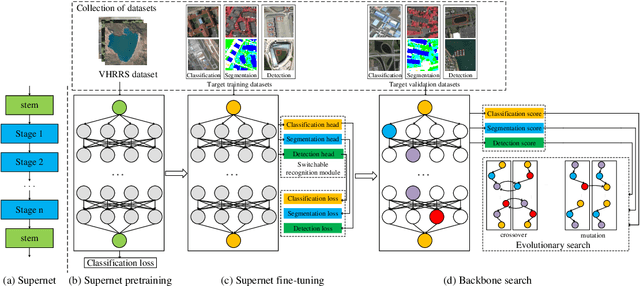
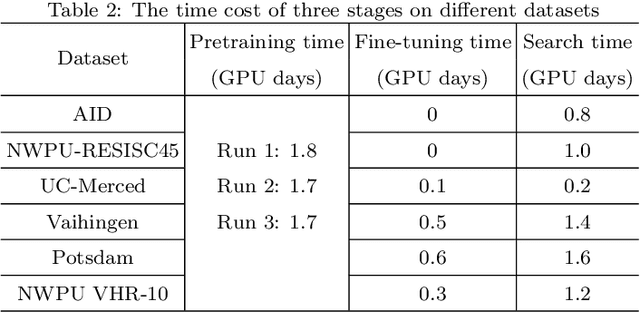
Recently, a massive number of deep learning based approaches have been successfully applied to various remote sensing image (RSI) recognition tasks. However, most existing advances of deep learning methods in the RSI field heavily rely on the features extracted by the manually designed backbone network, which severely hinders the potential of deep learning models due the complexity of RSI and the limitation of prior knowledge. In this paper, we research a new design paradigm for the backbone architecture in RSI recognition tasks, including scene classification, land-cover classification and object detection. A novel one-shot architecture search framework based on weight-sharing strategy and evolutionary algorithm is proposed, called RSBNet, which consists of three stages: Firstly, a supernet constructed in a layer-wise search space is pretrained on a self-assembled large-scale RSI dataset based on an ensemble single-path training strategy. Next, the pre-trained supernet is equipped with different recognition heads through the switchable recognition module and respectively fine-tuned on the target dataset to obtain task-specific supernet. Finally, we search the optimal backbone architecture for different recognition tasks based on the evolutionary algorithm without any network training. Extensive experiments have been conducted on five benchmark datasets for different recognition tasks, the results show the effectiveness of the proposed search paradigm and demonstrate that the searched backbone is able to flexibly adapt different RSI recognition tasks and achieve impressive performance.