 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Graph Structure Learning via Resistance Curvature Flow
Jan 13, 2026Geometric Representation Learning (GRL) aims to approximate the non-Euclidean topology of high-dimensional data through discrete graph structures, grounded in the manifold hypothesis. However, traditional static graph construction methods based on Euclidean distance often fail to capture the intrinsic curvature characteristics of the data manifold. Although Ollivier-Ricci Curvature Flow (OCF) has proven to be a powerful tool for dynamic topological optimization, its core reliance on Optimal Transport (Wasserstein distance) leads to prohibitive computational complexity, severely limiting its application in large-scale datasets and deep learning frameworks. To break this bottleneck, this paper proposes a novel geometric evolution framework: Resistance Curvature Flow (RCF). Leveraging the concept of effective resistance from circuit physics, RCF transforms expensive curvature optimization into efficient matrix operations. This approach achieves over 100x computational acceleration while maintaining geometric optimization capabilities comparable to OCF. We provide an in-depth exploration of the theoretical foundations and dynamical principles of RCF, elucidating how it guides the redistribution of edge weights via curvature gradients to eliminate topological noise and strengthen local cluster structures. Furthermore, we provide a mechanistic explanation of RCF's role in manifold enhancement and noise suppression, as well as its compatibility with deep learning models. We design a graph optimization algorithm, DGSL-RCF, based on this framework. Experimental results across deep metric learning, manifold learning, and graph structure learning demonstrate that DGSL-RCF significantly improves representation quality and downstream task performance.
Never Too Rigid to Reach: Adaptive Virtual Model Control with LLM- and Lyapunov-Based Reinforcement Learning
Oct 27, 2025Robotic arms are increasingly deployed in uncertain environments, yet conventional control pipelines often become rigid and brittle when exposed to perturbations or incomplete information. Virtual Model Control (VMC) enables compliant behaviors by embedding virtual forces and mapping them into joint torques, but its reliance on fixed parameters and limited coordination among virtual components constrains adaptability and may undermine stability as task objectives evolve. To address these limitations, we propose Adaptive VMC with Large Language Model (LLM)- and Lyapunov-Based Reinforcement Learning (RL), which preserves the physical interpretability of VMC while supporting stability-guaranteed online adaptation. The LLM provides structured priors and high-level reasoning that enhance coordination among virtual components, improve sample efficiency, and facilitate flexible adjustment to varying task requirements. Complementarily, Lyapunov-based RL enforces theoretical stability constraints, ensuring safe and reliable adaptation under uncertainty. Extensive simulations on a 7-DoF Panda arm demonstrate that our approach effectively balances competing objectives in dynamic tasks, achieving superior performance while highlighting the synergistic benefits of LLM guidance and Lyapunov-constrained adaptation.
A Robust Classification Method using Hybrid Word Embedding for Early Diagnosis of Alzheimer's Disease
Oct 16, 2025Early detection of Alzheimer's Disease (AD) is greatly beneficial to AD patients, leading to early treatments that lessen symptoms and alleviating financial burden of health care. As one of the leading signs of AD, language capability changes can be used for early diagnosis of AD. In this paper, I develop a robust classification method using hybrid word embedding and fine-tuned hyperparameters to achieve state-of-the-art accuracy in the early detection of AD. Specifically, we create a hybrid word embedding based on word vectors from Doc2Vec and ELMo to obtain perplexity scores of the sentences. The scores identify whether a sentence is fluent or not and capture semantic context of the sentences. I enrich the word embedding by adding linguistic features to analyze syntax and semantics. Further, we input an embedded feature vector into logistic regression and fine tune hyperparameters throughout the pipeline. By tuning hyperparameters of the machine learning pipeline (e.g., model regularization parameter, learning rate and vector size of Doc2Vec, and vector size of ELMo), I achieve 91% classification accuracy and an Area Under the Curve (AUC) of 97% in distinguishing early AD from healthy subjects. Based on my knowledge, my model with 91% accuracy and 97% AUC outperforms the best existing NLP model for AD diagnosis with an accuracy of 88% [32]. I study the model stability through repeated experiments and find that the model is stable even though the training data is split randomly (standard deviation of accuracy = 0.0403; standard deviation of AUC = 0.0174). This affirms our proposed method is accurate and stable. This model can be used as a large-scale screening method for AD, as well as a complementary examination for doctors to detect AD.
* Peer-reviewed and published in Proceedings of the 2020 3rd International Conference on Algorithms, Computing and Artificial Intelligence (ACAI 2020). 7 pages, 5 figures
Meta knowledge assisted Evolutionary Neural Architecture Search
Apr 30, 2025Evolutionary computation (EC)-based neural architecture search (NAS) has achieved remarkable performance in the automatic design of neural architectures. However, the high computational cost associated with evaluating searched architectures poses a challenge for these methods, and a fixed form of learning rate (LR) schedule means greater information loss on diverse searched architectures. This paper introduces an efficient EC-based NAS method to solve these problems via an innovative meta-learning framework. Specifically, a meta-learning-rate (Meta-LR) scheme is used through pretraining to obtain a suitable LR schedule, which guides the training process with lower information loss when evaluating each individual. An adaptive surrogate model is designed through an adaptive threshold to select the potential architectures in a few epochs and then evaluate the potential architectures with complete epochs. Additionally, a periodic mutation operator is proposed to increase the diversity of the population, which enhances the generalizability and robustness. Experiments on CIFAR-10, CIFAR-100, and ImageNet1K datasets demonstrate that the proposed method achieves high performance comparable to that of many state-of-the-art peer methods, with lower computational cost and greater robustness.
Achieving Hiding and Smart Anti-Jamming Communication: A Parallel DRL Approach against Moving Reactive Jammer
Feb 04, 2025



This paper addresses the challenge of anti-jamming in moving reactive jamming scenarios. The moving reactive jammer initiates high-power tracking jamming upon detecting any transmission activity, and when unable to detect a signal, resorts to indiscriminate jamming. This presents dual imperatives: maintaining hiding to avoid the jammer's detection and simultaneously evading indiscriminate jamming. Spread spectrum techniques effectively reduce transmitting power to elude detection but fall short in countering indiscriminate jamming. Conversely, changing communication frequencies can help evade indiscriminate jamming but makes the transmission vulnerable to tracking jamming without spread spectrum techniques to remain hidden. Current methodologies struggle with the complexity of simultaneously optimizing these two requirements due to the expansive joint action spaces and the dynamics of moving reactive jammers. To address these challenges, we propose a parallelized deep reinforcement learning (DRL) strategy. The approach includes a parallelized network architecture designed to decompose the action space. A parallel exploration-exploitation selection mechanism replaces the $\varepsilon $-greedy mechanism, accelerating convergence. Simulations demonstrate a nearly 90\% increase in normalized throughput.
A Distributed Hybrid Quantum Convolutional Neural Network for Medical Image Classification
Jan 07, 2025



Medical images are characterized by intricate and complex features, requiring interpretation by physicians with medical knowledge and experience. Classical neural networks can reduce the workload of physicians, but can only handle these complex features to a limited extent. Theoretically, quantum computing can explore a broader parameter space with fewer parameters, but it is currently limited by the constraints of quantum hardware.Considering these factors, we propose a distributed hybrid quantum convolutional neural network based on quantum circuit splitting. This model leverages the advantages of quantum computing to effectively capture the complex features of medical images, enabling efficient classification even in resource-constrained environments. Our model employs a quantum convolutional neural network (QCNN) to extract high-dimensional features from medical images, thereby enhancing the model's expressive capability.By integrating distributed techniques based on quantum circuit splitting, the 8-qubit QCNN can be reconstructed using only 5 qubits.Experimental results demonstrate that our model achieves strong performance across 3 datasets for both binary and multiclass classification tasks. Furthermore, compared to recent technologies, our model achieves superior performance with fewer parameters, and experimental results validate the effectiveness of our model.
OmniPrism: Learning Disentangled Visual Concept for Image Generation
Dec 16, 2024



Creative visual concept generation often draws inspiration from specific concepts in a reference image to produce relevant outcomes. However, existing methods are typically constrained to single-aspect concept generation or are easily disrupted by irrelevant concepts in multi-aspect concept scenarios, leading to concept confusion and hindering creative generation. To address this, we propose OmniPrism, a visual concept disentangling approach for creative image generation. Our method learns disentangled concept representations guided by natural language and trains a diffusion model to incorporate these concepts. We utilize the rich semantic space of a multimodal extractor to achieve concept disentanglement from given images and concept guidance. To disentangle concepts with different semantics, we construct a paired concept disentangled dataset (PCD-200K), where each pair shares the same concept such as content, style, and composition. We learn disentangled concept representations through our contrastive orthogonal disentangled (COD) training pipeline, which are then injected into additional diffusion cross-attention layers for generation. A set of block embeddings is designed to adapt each block's concept domain in the diffusion models. Extensive experiments demonstrate that our method can generate high-quality, concept-disentangled results with high fidelity to text prompts and desired concepts.
Separable Mixture of Low-Rank Adaptation for Continual Visual Instruction Tuning
Nov 21, 2024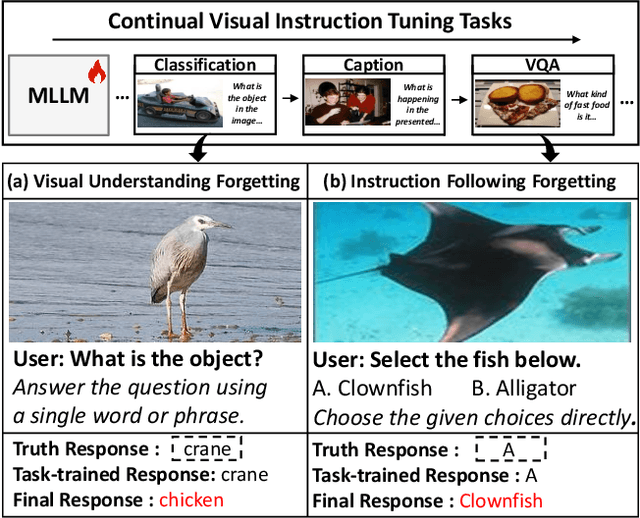
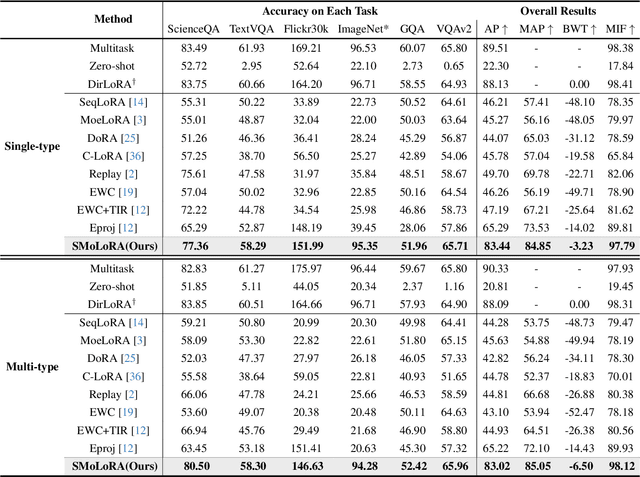
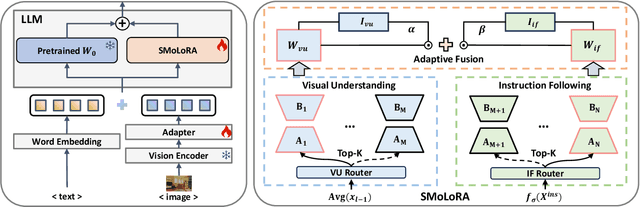
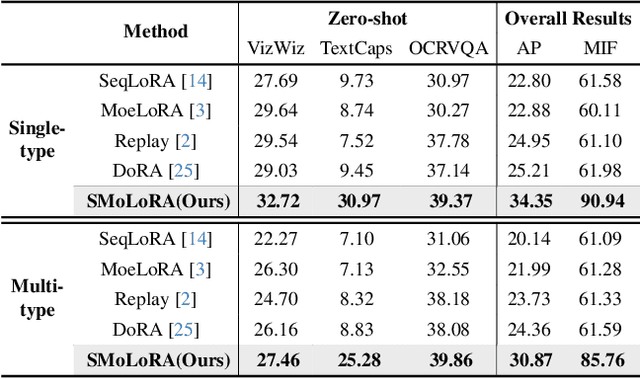
Visual instruction tuning (VIT) enables multimodal large language models (MLLMs) to effectively handle a wide range of vision tasks by framing them as language-based instructions. Building on this, continual visual instruction tuning (CVIT) extends the capability of MLLMs to incrementally learn new tasks, accommodating evolving functionalities. While prior work has advanced CVIT through the development of new benchmarks and approaches to mitigate catastrophic forgetting, these efforts largely follow traditional continual learning paradigms, neglecting the unique challenges specific to CVIT. We identify a dual form of catastrophic forgetting in CVIT, where MLLMs not only forget previously learned visual understanding but also experience a decline in instruction following abilities as they acquire new tasks. To address this, we introduce the Separable Mixture of Low-Rank Adaptation (SMoLoRA) framework, which employs separable routing through two distinct modules - one for visual understanding and another for instruction following. This dual-routing design enables specialized adaptation in both domains, preventing forgetting while improving performance. Furthermore, we propose a novel CVIT benchmark that goes beyond existing benchmarks by additionally evaluating a model's ability to generalize to unseen tasks and handle diverse instructions across various tasks. Extensive experiments demonstrate that SMoLoRA outperforms existing methods in mitigating dual forgetting, improving generalization to unseen tasks, and ensuring robustness in following diverse instructions.
Masked Image Modeling Boosting Semi-Supervised Semantic Segmentation
Nov 14, 2024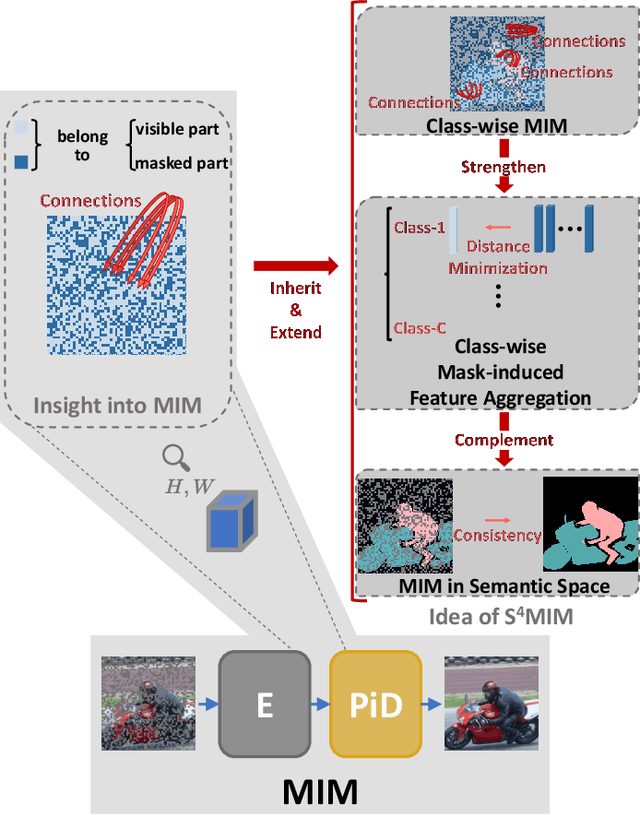
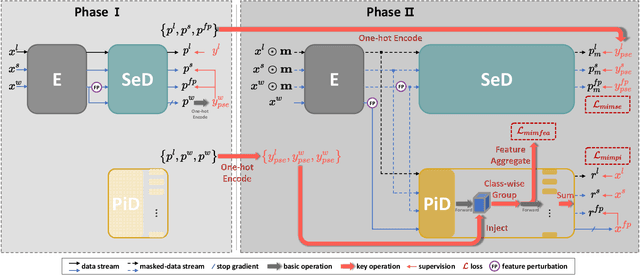
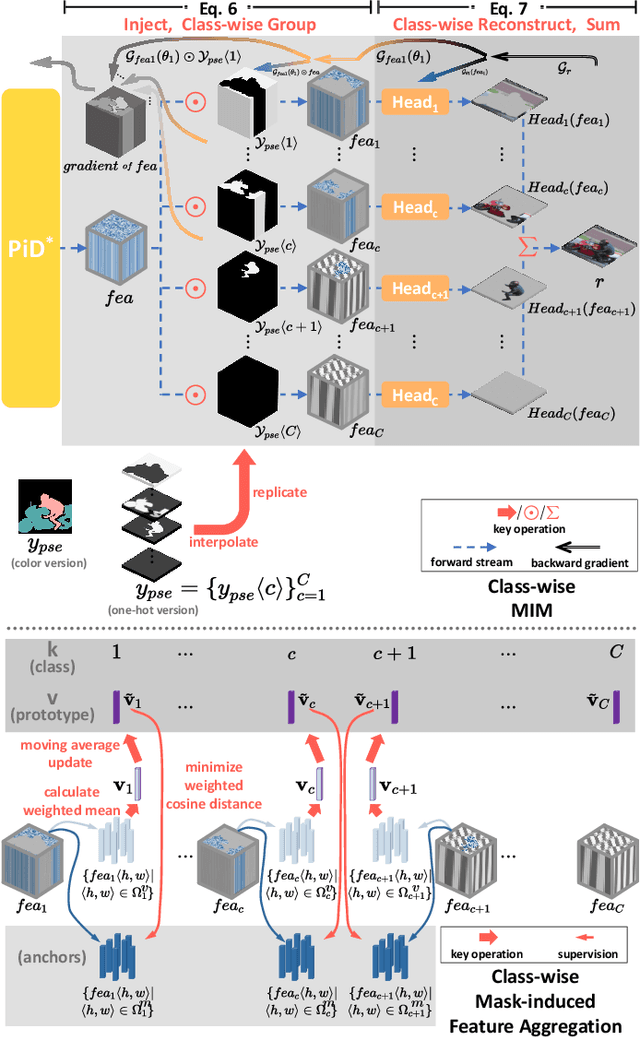
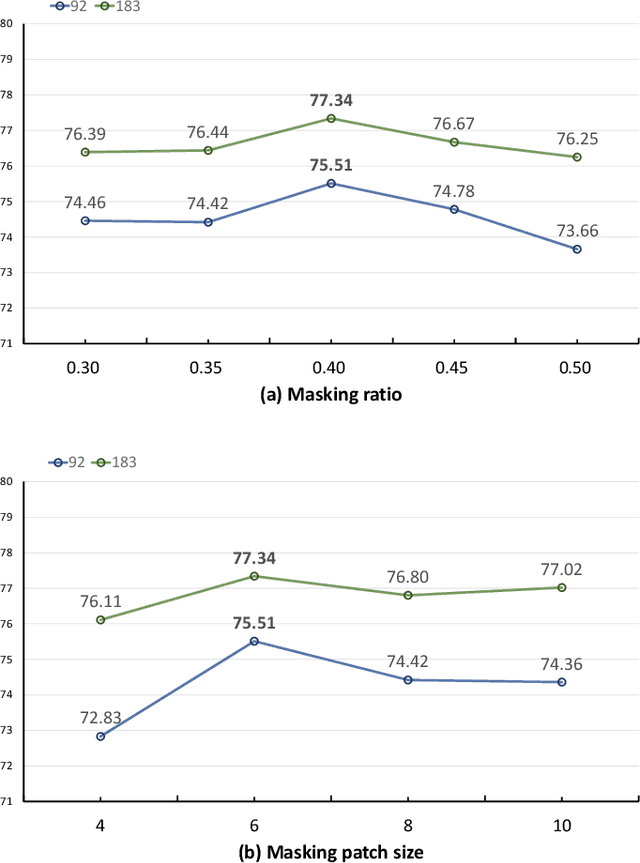
In view of the fact that semi- and self-supervised learning share a fundamental principle, effectively modeling knowledge from unlabeled data, various semi-supervised semantic segmentation methods have integrated representative self-supervised learning paradigms for further regularization. However, the potential of the state-of-the-art generative self-supervised paradigm, masked image modeling, has been scarcely studied. This paradigm learns the knowledge through establishing connections between the masked and visible parts of masked image, during the pixel reconstruction process. By inheriting and extending this insight, we successfully leverage masked image modeling to boost semi-supervised semantic segmentation. Specifically, we introduce a novel class-wise masked image modeling that independently reconstructs different image regions according to their respective classes. In this way, the mask-induced connections are established within each class, mitigating the semantic confusion that arises from plainly reconstructing images in basic masked image modeling. To strengthen these intra-class connections, we further develop a feature aggregation strategy that minimizes the distances between features corresponding to the masked and visible parts within the same class. Additionally, in semantic space, we explore the application of masked image modeling to enhance regularization. Extensive experiments conducted on well-known benchmarks demonstrate that our approach achieves state-of-the-art performance. The code will be available at https://github.com/haoxt/S4MIM.
Incorporate LLMs with Influential Recommender System
Sep 07, 2024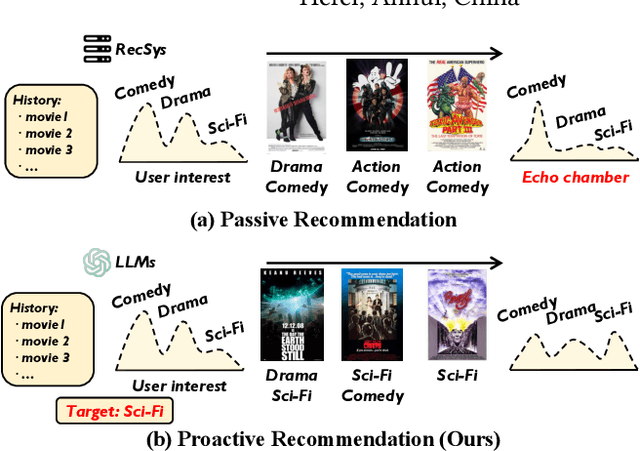
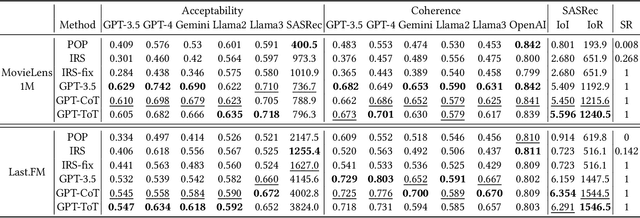
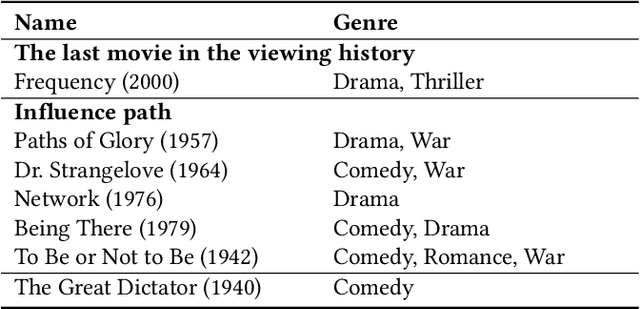
Recommender systems have achieved increasing accuracy over the years. However, this precision often leads users to narrow their interests, resulting in issues such as limited diversity and the creation of echo chambers. Current research addresses these challenges through proactive recommender systems by recommending a sequence of items (called influence path) to guide user interest in the target item. However, existing methods struggle to construct a coherent influence path that builds up with items the user is likely to enjoy. In this paper, we leverage the Large Language Model's (LLMs) exceptional ability for path planning and instruction following, introducing a novel approach named LLM-based Influence Path Planning (LLM-IPP). Our approach maintains coherence between consecutive recommendations and enhances user acceptability of the recommended items. To evaluate LLM-IPP, we implement various user simulators and metrics to measure user acceptability and path coherence. Experimental results demonstrate that LLM-IPP significantly outperforms traditional proactive recommender systems. This study pioneers the integration of LLMs into proactive recommender systems, offering a reliable and user-engaging methodology for future recommendation technologies.