 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA in LoRA: Towards Parameter-Efficient Architecture Expansion for Continual Visual Instruction Tuning
Aug 08, 2025Continual Visual Instruction Tuning (CVIT) enables Multimodal Large Language Models (MLLMs) to incrementally learn new tasks over time. However, this process is challenged by catastrophic forgetting, where performance on previously learned tasks deteriorates as the model adapts to new ones. A common approach to mitigate forgetting is architecture expansion, which introduces task-specific modules to prevent interference. Yet, existing methods often expand entire layers for each task, leading to significant parameter overhead and poor scalability. To overcome these issues, we introduce LoRA in LoRA (LiLoRA), a highly efficient architecture expansion method tailored for CVIT in MLLMs. LiLoRA shares the LoRA matrix A across tasks to reduce redundancy, applies an additional low-rank decomposition to matrix B to minimize task-specific parameters, and incorporates a cosine-regularized stability loss to preserve consistency in shared representations over time. Extensive experiments on a diverse CVIT benchmark show that LiLoRA consistently achieves superior performance in sequential task learning while significantly improving parameter efficiency compared to existing approaches.
Information-Theoretic Graph Fusion with Vision-Language-Action Model for Policy Reasoning and Dual Robotic Control
Aug 07, 2025Teaching robots dexterous skills from human videos remains challenging due to the reliance on low-level trajectory imitation, which fails to generalize across object types, spatial layouts, and manipulator configurations. We propose Graph-Fused Vision-Language-Action (GF-VLA), a framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB and Depth human demonstrations. GF-VLA first extracts Shannon-information-based cues to identify hands and objects with the highest task relevance, then encodes these cues into temporally ordered scene graphs that capture both hand-object and object-object interactions. These graphs are fused with a language-conditioned transformer that generates hierarchical behavior trees and interpretable Cartesian motion commands. To improve execution efficiency in bimanual settings, we further introduce a cross-hand selection policy that infers optimal gripper assignment without explicit geometric reasoning. We evaluate GF-VLA on four structured dual-arm block assembly tasks involving symbolic shape construction and spatial generalization. Experimental results show that the information-theoretic scene representation achieves over 95 percent graph accuracy and 93 percent subtask segmentation, supporting the LLM planner in generating reliable and human-readable task policies. When executed by the dual-arm robot, these policies yield 94 percent grasp success, 89 percent placement accuracy, and 90 percent overall task success across stacking, letter-building, and geometric reconfiguration scenarios, demonstrating strong generalization and robustness across diverse spatial and semantic variations.
A Real-Time Control Barrier Function-Based Safety Filter for Motion Planning with Arbitrary Road Boundary Constraints
May 05, 2025We present a real-time safety filter for motion planning, such as learning-based methods, using Control Barrier Functions (CBFs), which provides formal guarantees for collision avoidance with road boundaries. A key feature of our approach is its ability to directly incorporate road geometries of arbitrary shape without resorting to conservative overapproximations. We formulate the safety filter as a constrained optimization problem in the form of a Quadratic Program (QP). It achieves safety by making minimal, necessary adjustments to the control actions issued by the nominal motion planner. We validate our safety filter through extensive numerical experiments across a variety of traffic scenarios featuring complex roads. The results confirm its reliable safety and high computational efficiency (execution frequency up to 40 Hz). Code & Video Demo: github.com/bassamlab/SigmaRL
Separable Mixture of Low-Rank Adaptation for Continual Visual Instruction Tuning
Nov 21, 2024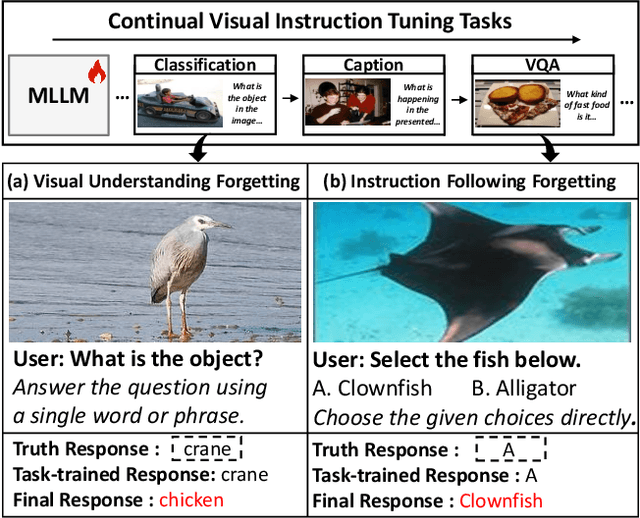
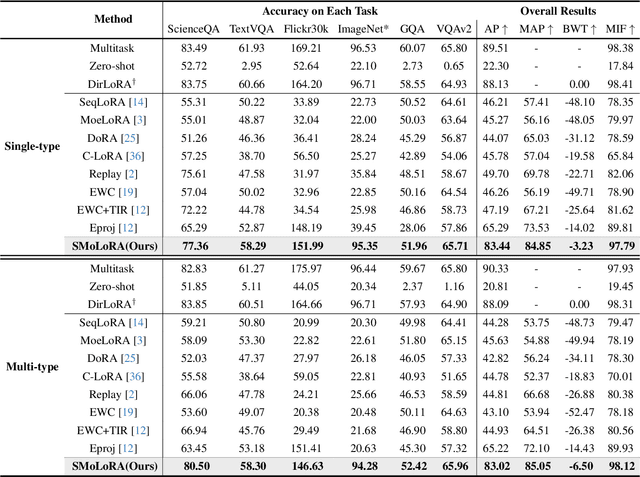
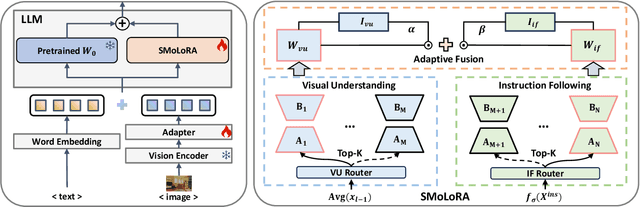
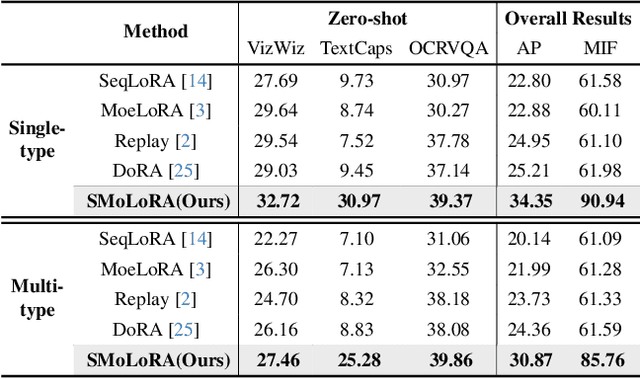
Visual instruction tuning (VIT) enables multimodal large language models (MLLMs) to effectively handle a wide range of vision tasks by framing them as language-based instructions. Building on this, continual visual instruction tuning (CVIT) extends the capability of MLLMs to incrementally learn new tasks, accommodating evolving functionalities. While prior work has advanced CVIT through the development of new benchmarks and approaches to mitigate catastrophic forgetting, these efforts largely follow traditional continual learning paradigms, neglecting the unique challenges specific to CVIT. We identify a dual form of catastrophic forgetting in CVIT, where MLLMs not only forget previously learned visual understanding but also experience a decline in instruction following abilities as they acquire new tasks. To address this, we introduce the Separable Mixture of Low-Rank Adaptation (SMoLoRA) framework, which employs separable routing through two distinct modules - one for visual understanding and another for instruction following. This dual-routing design enables specialized adaptation in both domains, preventing forgetting while improving performance. Furthermore, we propose a novel CVIT benchmark that goes beyond existing benchmarks by additionally evaluating a model's ability to generalize to unseen tasks and handle diverse instructions across various tasks. Extensive experiments demonstrate that SMoLoRA outperforms existing methods in mitigating dual forgetting, improving generalization to unseen tasks, and ensuring robustness in following diverse instructions.
Enhancing 3D Object Detection by Using Neural Network with Self-adaptive Thresholding
May 13, 2024Robust 3D object detection remains a pivotal concern in the domain of autonomous field robotics. Despite notable enhancements in detection accuracy across standard datasets, real-world urban environments, characterized by their unstructured and dynamic nature, frequently precipitate an elevated incidence of false positives, thereby undermining the reliability of existing detection paradigms. In this context, our study introduces an advanced post-processing algorithm that modulates detection thresholds dynamically relative to the distance from the ego object. Traditional perception systems typically utilize a uniform threshold, which often leads to decreased efficacy in detecting distant objects. In contrast, our proposed methodology employs a Neural Network with a self-adaptive thresholding mechanism that significantly attenuates false negatives while concurrently diminishing false positives, particularly in complex urban settings. Empirical results substantiate that our algorithm not only augments the performance of 3D object detection models in diverse urban and adverse weather scenarios but also establishes a new benchmark for adaptive thresholding techniques in field robotics.
Intelligent Robotic Control System Based on Computer Vision Technology
Apr 01, 2024



The article explores the intersection of computer vision technology and robotic control, highlighting its importance in various fields such as industrial automation, healthcare, and environmental protection. Computer vision technology, which simulates human visual observation, plays a crucial role in enabling robots to perceive and understand their surroundings, leading to advancements in tasks like autonomous navigation, object recognition, and waste management. By integrating computer vision with robot control, robots gain the ability to interact intelligently with their environment, improving efficiency.
Semantic Similarity Matching for Patent Documents Using Ensemble BERT-related Model and Novel Text Processing Method
Jan 06, 2024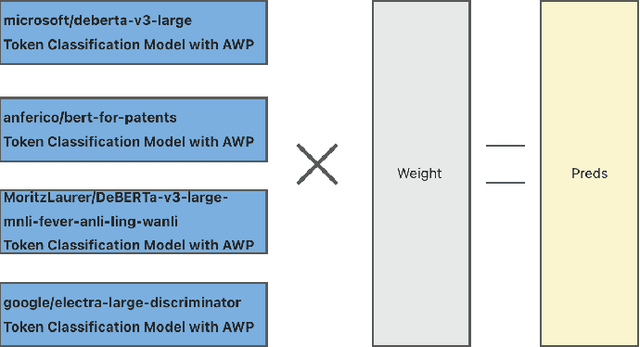
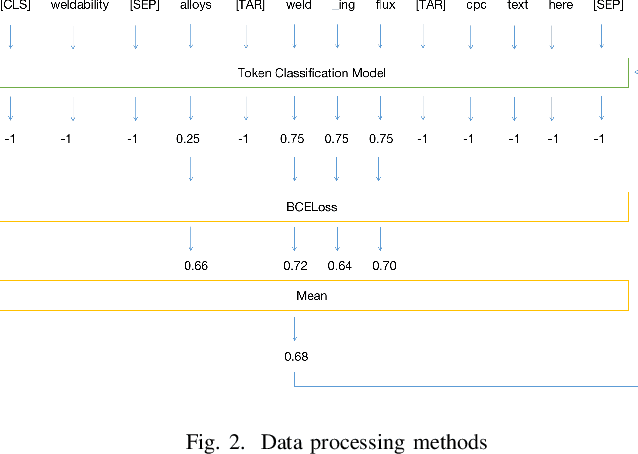
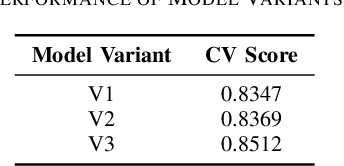
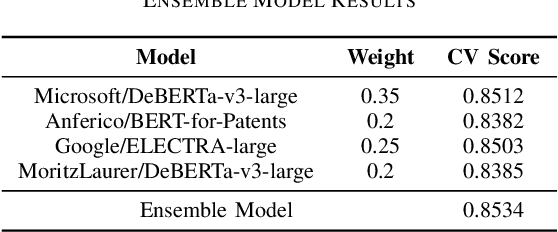
In the realm of patent document analysis, assessing semantic similarity between phrases presents a significant challenge, notably amplifying the inherent complexities of Cooperative Patent Classification (CPC) research. Firstly, this study addresses these challenges, recognizing early CPC work while acknowledging past struggles with language barriers and document intricacy. Secondly, it underscores the persisting difficulties of CPC research. To overcome these challenges and bolster the CPC system, This paper presents two key innovations. Firstly, it introduces an ensemble approach that incorporates four BERT-related models, enhancing semantic similarity accuracy through weighted averaging. Secondly, a novel text preprocessing method tailored for patent documents is introduced, featuring a distinctive input structure with token scoring that aids in capturing semantic relationships during CPC context training, utilizing BCELoss. Our experimental findings conclusively establish the effectiveness of both our Ensemble Model and novel text processing strategies when deployed on the U.S. Patent Phrase to Phrase Matching dataset.
Enhancing Essay Scoring with Adversarial Weights Perturbation and Metric-specific AttentionPooling
Jan 06, 2024
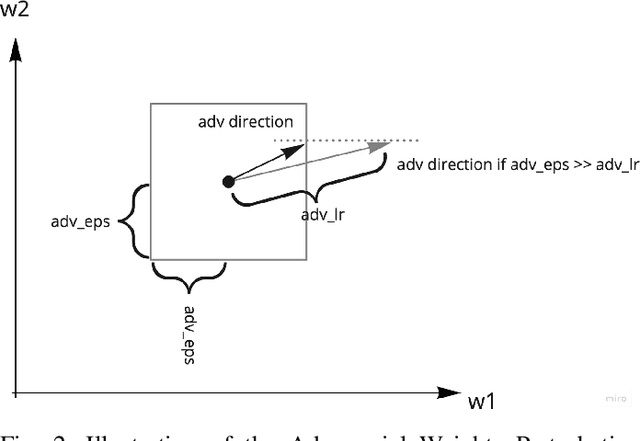
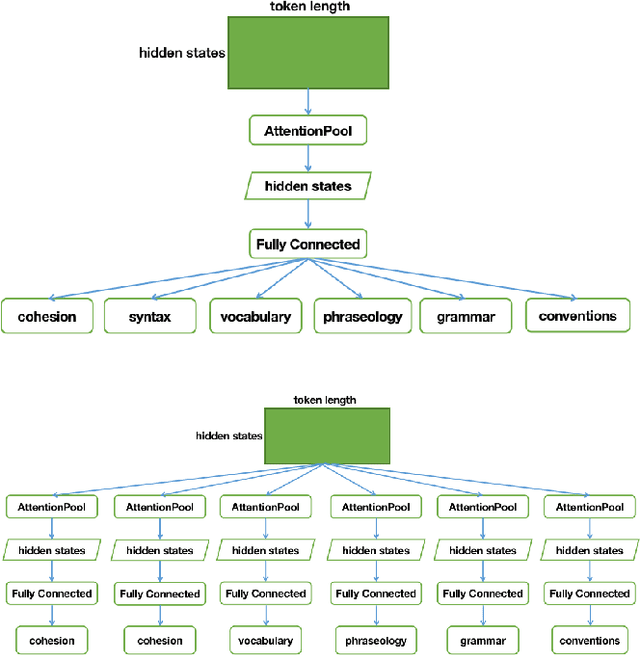
The objective of this study is to improve automated feedback tools designed for English Language Learners (ELLs) through the utilization of data science techniques encompassing machine learning, natural language processing, and educational data analytics. Automated essay scoring (AES) research has made strides in evaluating written essays, but it often overlooks the specific needs of English Language Learners (ELLs) in language development. This study explores the application of BERT-related techniques to enhance the assessment of ELLs' writing proficiency within AES. To address the specific needs of ELLs, we propose the use of DeBERTa, a state-of-the-art neural language model, for improving automated feedback tools. DeBERTa, pretrained on large text corpora using self-supervised learning, learns universal language representations adaptable to various natural language understanding tasks. The model incorporates several innovative techniques, including adversarial training through Adversarial Weights Perturbation (AWP) and Metric-specific AttentionPooling (6 kinds of AP) for each label in the competition. The primary focus of this research is to investigate the impact of hyperparameters, particularly the adversarial learning rate, on the performance of the model. By fine-tuning the hyperparameter tuning process, including the influence of 6AP and AWP, the resulting models can provide more accurate evaluations of language proficiency and support tailored learning tasks for ELLs. This work has the potential to significantly benefit ELLs by improving their English language proficiency and facilitating their educational journey.
Enhancing Multimodal Understanding with CLIP-Based Image-to-Text Transformation
Jan 02, 2024



The process of transforming input images into corresponding textual explanations stands as a crucial and complex endeavor within the domains of computer vision and natural language processing. In this paper, we propose an innovative ensemble approach that harnesses the capabilities of Contrastive Language-Image Pretraining models.
Integration and Performance Analysis of Artificial Intelligence and Computer Vision Based on Deep Learning Algorithms
Dec 20, 2023



This paper focuses on the analysis of the application effectiveness of the integration of deep learning and computer vision technologies. Deep learning achieves a historic breakthrough by constructing hierarchical neural networks, enabling end-to-end feature learning and semantic understanding of images. The successful experiences in the field of computer vision provide strong support for training deep learning algorithms. The tight integration of these two fields has given rise to a new generation of advanced computer vision systems, significantly surpassing traditional methods in tasks such as machine vision image classification and object detection. In this paper, typical image classification cases are combined to analyze the superior performance of deep neural network models while also pointing out their limitations in generalization and interpretability, proposing directions for future improvements. Overall, the efficient integration and development trend of deep learning with massive visual data will continue to drive technological breakthroughs and application expansion in the field of computer vision, making it possible to build truly intelligent machine vision systems. This deepening fusion paradigm will powerfully promote unprecedented tasks and functions in computer vision, providing stronger development momentum for related disciplines and industries.