 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Similarity Matching for Patent Documents Using Ensemble BERT-related Model and Novel Text Processing Method
Paper and Code
Jan 06, 2024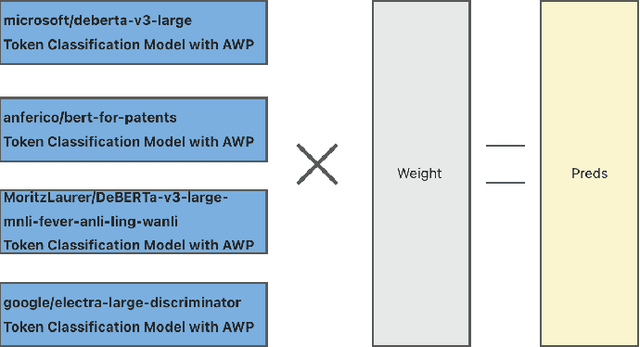
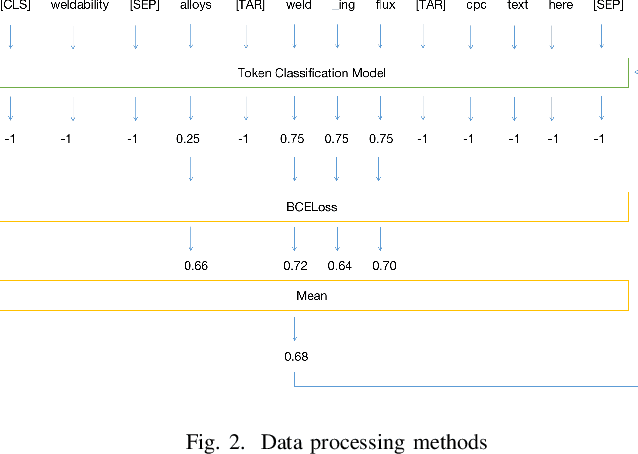
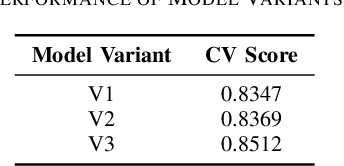
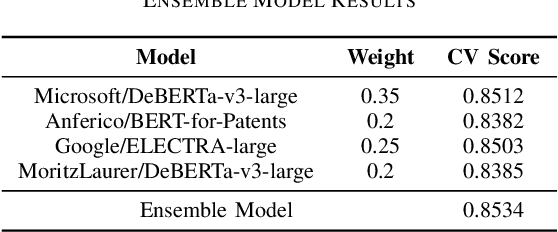
In the realm of patent document analysis, assessing semantic similarity between phrases presents a significant challenge, notably amplifying the inherent complexities of Cooperative Patent Classification (CPC) research. Firstly, this study addresses these challenges, recognizing early CPC work while acknowledging past struggles with language barriers and document intricacy. Secondly, it underscores the persisting difficulties of CPC research. To overcome these challenges and bolster the CPC system, This paper presents two key innovations. Firstly, it introduces an ensemble approach that incorporates four BERT-related models, enhancing semantic similarity accuracy through weighted averaging. Secondly, a novel text preprocessing method tailored for patent documents is introduced, featuring a distinctive input structure with token scoring that aids in capturing semantic relationships during CPC context training, utilizing BCELoss. Our experimental findings conclusively establish the effectiveness of both our Ensemble Model and novel text processing strategies when deployed on the U.S. Patent Phrase to Phrase Matching dataset.