 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Localized and Disentangled Knowledge Editing for Multimodal Large Language Models
May 28, 2026Existing methods in Multimodal Knowledge Editing (MKE) have advanced the ability to correct outdated or inaccurate knowledge in Multimodal Large Language Models (MLLMs). However, they exhibit a critical limitation: while effectively modifying target factual pairs, they fail to generalize edits to logically related queries and often cause unintended alterations to unrelated but visually or semantically linked information. We identify and formalize two underlying failure modes causing this issue: Causal Misalignment, which confines edits to the specific sample, and Feature Entanglement, which causes unintended alterations to coupled but irrelevant information. To address these issues, we propose Localized and Disentangled Knowledge Editing (LDKE), a new framework that achieves precise and generalized editing by localizing fact-specific model layers and disentangling target-relevant inputs from irrelevant ones. Our approach introduces a Fast Localization module to identify and update critical layers efficiently, along with a Disentanglement Classifier that routes inputs appropriately to preserve unrelated knowledge. Extensive experiments across various benchmarks and MLLMs demonstrate that LDKE achieves superior performance in propagating edits to related contexts while maintaining high locality.
CrossCult-KIBench: A Benchmark for Cross-Cultural Knowledge Insertion in MLLMs
May 07, 2026Multimodal Large Language Models (MLLMs), trained primarily on English-centric data, frequently generate culturally inappropriate or misaligned responses in cross-cultural settings. To mitigate this, we introduce the task of cross-cultural knowledge insertion, which focuses on adapting models to specific cultural contexts while preserving their original behavior in other cultures. To facilitate research in this area, we introduce CrossCult-KIBench, a comprehensive evaluation benchmark for assessing both the effectiveness of knowledge insertion and its unintended side effects on non-target cultures. The benchmark includes 9,800 image-grounded cases covering 49 culturally relevant visual scenarios across English, Chinese, and Arabic language-culture groups. It supports evaluation in both single-insert and sequential-insert settings. We also propose Memory-Conditioned Knowledge Insertion (MCKI) as a baseline method. MCKI retrieves relevant cultural knowledge from an external memory using frozen MLLM representations, prepending matched entries as conditional prompts when applicable. Extensive experiments on CrossCult-KIBench reveal that current approaches struggle to balance effective cultural adaptation with behavioral preservation, highlighting a key challenge in developing culturally-aware MLLMs. Our work thus underscores an important research direction for developing more culturally adaptive and responsible MLLMs.
WebUncertainty: Dual-Level Uncertainty Driven Planning and Reasoning For Autonomous Web Agent
Apr 21, 2026Recent advancements in large language models (LLMs) have empowered autonomous web agents to execute natural language instructions directly on real-world webpages. However, existing agents often struggle with complex tasks involving dynamic interactions and long-horizon execution due to rigid planning strategies and hallucination-prone reasoning. To address these limitations, we propose WebUncertainty, a novel autonomous agent framework designed to tackle dual-level uncertainty in planning and reasoning. Specifically, we design a Task Uncertainty-Driven Adaptive Planning Mechanism that adaptively selects planning modes to navigate unknown environments. Furthermore, we introduce an Action Uncertainty-Driven Monte Carlo tree search (MCTS) Reasoning Mechanism. This mechanism incorporates the Confidence-induced Action Uncertainty (ConActU) strategy to quantify both aleatoric uncertainty (AU) and epistemic uncertainty (EU), thereby optimizing the search process and guiding robust decision-making. Experimental results on the WebArena and WebVoyager benchmarks demonstrate that WebUncertainty achieves superior performance compared to state-of-the-art baselines.
Layer Consistency Matters: Elegant Latent Transition Discrepancy for Generalizable Synthetic Image Detection
Mar 11, 2026Recent rapid advancement of generative models has significantly improved the fidelity and accessibility of AI-generated synthetic images. While enabling various innovative applications, the unprecedented realism of these synthetics makes them increasingly indistinguishable from authentic photographs, posing serious security risks, such as media credibility and content manipulation. Although extensive efforts have been dedicated to detecting synthetic images, most existing approaches suffer from poor generalization to unseen data due to their reliance on model-specific artifacts or low-level statistical cues. In this work, we identify a previously unexplored distinction that real images maintain consistent semantic attention and structural coherence in their latent representations, exhibiting more stable feature transitions across network layers, whereas synthetic ones present discernible distinct patterns. Therefore, we propose a novel approach termed latent transition discrepancy (LTD), which captures the inter-layer consistency differences of real and synthetic images. LTD adaptively identifies the most discriminative layers and assesses the transition discrepancies across layers. Benefiting from the proposed inter-layer discriminative modeling, our approach exceeds the base model by 14.35\% in mean Acc across three datasets containing diverse GANs and DMs. Extensive experiments demonstrate that LTD outperforms recent state-of-the-art methods, achieving superior detection accuracy, generalizability, and robustness. The code is available at https://github.com/yywencs/LTD
Language as Prior, Vision as Calibration: Metric Scale Recovery for Monocular Depth Estimation
Jan 07, 2026Relative-depth foundation models transfer well, yet monocular metric depth remains ill-posed due to unidentifiable global scale and heightened domain-shift sensitivity. Under a frozen-backbone calibration setting, we recover metric depth via an image-specific affine transform in inverse depth and train only lightweight calibration heads while keeping the relative-depth backbone and the CLIP text encoder fixed. Since captions provide coarse but noisy scale cues that vary with phrasing and missing objects, we use language to predict an uncertainty-aware envelope that bounds feasible calibration parameters in an unconstrained space, rather than committing to a text-only point estimate. We then use pooled multi-scale frozen visual features to select an image-specific calibration within this envelope. During training, a closed-form least-squares oracle in inverse depth provides per-image supervision for learning the envelope and the selected calibration. Experiments on NYUv2 and KITTI improve in-domain accuracy, while zero-shot transfer to SUN-RGBD and DDAD demonstrates improved robustness over strong language-only baselines.
LoRA in LoRA: Towards Parameter-Efficient Architecture Expansion for Continual Visual Instruction Tuning
Aug 08, 2025Continual Visual Instruction Tuning (CVIT) enables Multimodal Large Language Models (MLLMs) to incrementally learn new tasks over time. However, this process is challenged by catastrophic forgetting, where performance on previously learned tasks deteriorates as the model adapts to new ones. A common approach to mitigate forgetting is architecture expansion, which introduces task-specific modules to prevent interference. Yet, existing methods often expand entire layers for each task, leading to significant parameter overhead and poor scalability. To overcome these issues, we introduce LoRA in LoRA (LiLoRA), a highly efficient architecture expansion method tailored for CVIT in MLLMs. LiLoRA shares the LoRA matrix A across tasks to reduce redundancy, applies an additional low-rank decomposition to matrix B to minimize task-specific parameters, and incorporates a cosine-regularized stability loss to preserve consistency in shared representations over time. Extensive experiments on a diverse CVIT benchmark show that LiLoRA consistently achieves superior performance in sequential task learning while significantly improving parameter efficiency compared to existing approaches.
MobileIE: An Extremely Lightweight and Effective ConvNet for Real-Time Image Enhancement on Mobile Devices
Jul 02, 2025Recent advancements in deep neural networks have driven significant progress in image enhancement (IE). However, deploying deep learning models on resource-constrained platforms, such as mobile devices, remains challenging due to high computation and memory demands. To address these challenges and facilitate real-time IE on mobile, we introduce an extremely lightweight Convolutional Neural Network (CNN) framework with around 4K parameters. Our approach integrates reparameterization with an Incremental Weight Optimization strategy to ensure efficiency. Additionally, we enhance performance with a Feature Self-Transform module and a Hierarchical Dual-Path Attention mechanism, optimized with a Local Variance-Weighted loss. With this efficient framework, we are the first to achieve real-time IE inference at up to 1,100 frames per second (FPS) while delivering competitive image quality, achieving the best trade-off between speed and performance across multiple IE tasks. The code will be available at https://github.com/AVC2-UESTC/MobileIE.git.
Prompt to Restore, Restore to Prompt: Cyclic Prompting for Universal Adverse Weather Removal
Mar 12, 2025
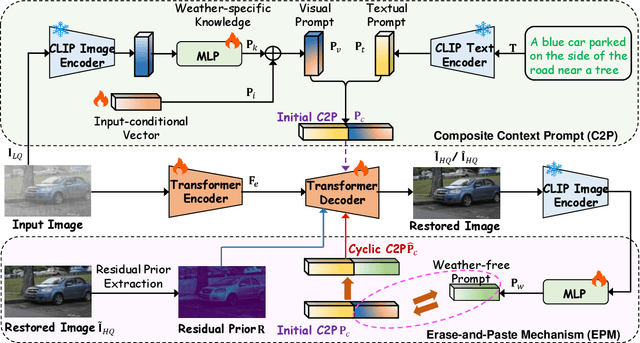
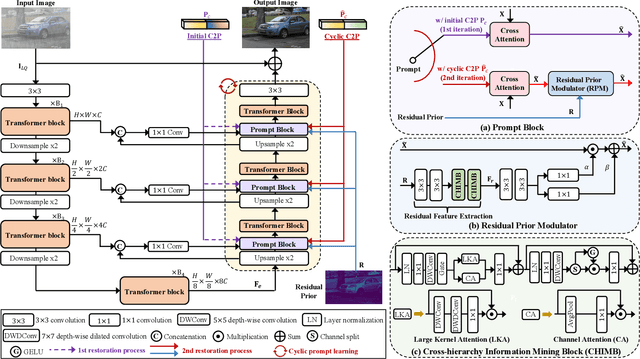

Universal adverse weather removal (UAWR) seeks to address various weather degradations within a unified framework. Recent methods are inspired by prompt learning using pre-trained vision-language models (e.g., CLIP), leveraging degradation-aware prompts to facilitate weather-free image restoration, yielding significant improvements. In this work, we propose CyclicPrompt, an innovative cyclic prompt approach designed to enhance the effectiveness, adaptability, and generalizability of UAWR. CyclicPrompt Comprises two key components: 1) a composite context prompt that integrates weather-related information and context-aware representations into the network to guide restoration. This prompt differs from previous methods by marrying learnable input-conditional vectors with weather-specific knowledge, thereby improving adaptability across various degradations. 2) The erase-and-paste mechanism, after the initial guided restoration, substitutes weather-specific knowledge with constrained restoration priors, inducing high-quality weather-free concepts into the composite prompt to further fine-tune the restoration process. Therefore, we can form a cyclic "Prompt-Restore-Prompt" pipeline that adeptly harnesses weather-specific knowledge, textual contexts, and reliable textures. Extensive experiments on synthetic and real-world datasets validate the superior performance of CyclicPrompt. The code is available at: https://github.com/RongxinL/CyclicPrompt.
Precise Localization of Memories: A Fine-grained Neuron-level Knowledge Editing Technique for LLMs
Mar 03, 2025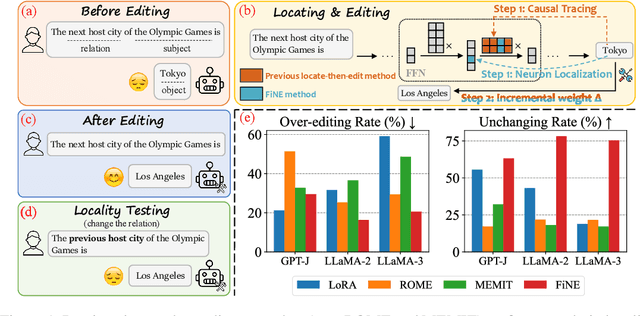
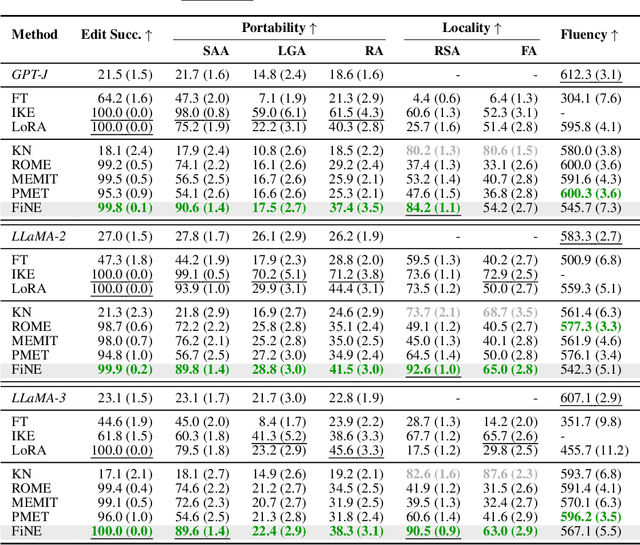
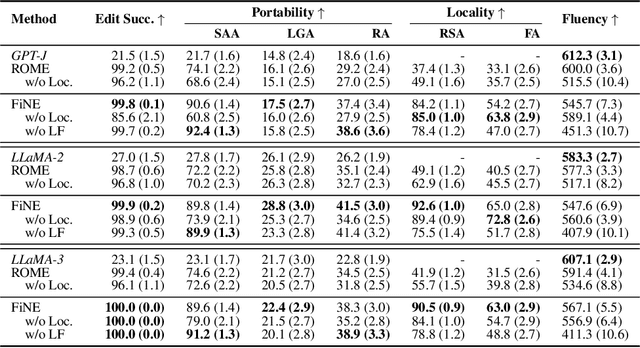
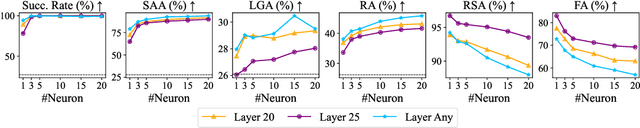
Knowledge editing aims to update outdated information in Large Language Models (LLMs). A representative line of study is locate-then-edit methods, which typically employ causal tracing to identify the modules responsible for recalling factual knowledge about entities. However, we find these methods are often sensitive only to changes in the subject entity, leaving them less effective at adapting to changes in relations. This limitation results in poor editing locality, which can lead to the persistence of irrelevant or inaccurate facts, ultimately compromising the reliability of LLMs. We believe this issue arises from the insufficient precision of knowledge localization. To address this, we propose a Fine-grained Neuron-level Knowledge Editing (FiNE) method that enhances editing locality without affecting overall success rates. By precisely identifying and modifying specific neurons within feed-forward networks, FiNE significantly improves knowledge localization and editing. Quantitative experiments demonstrate that FiNE efficiently achieves better overall performance compared to existing techniques, providing new insights into the localization and modification of knowledge within LLMs.
Separable Mixture of Low-Rank Adaptation for Continual Visual Instruction Tuning
Nov 21, 2024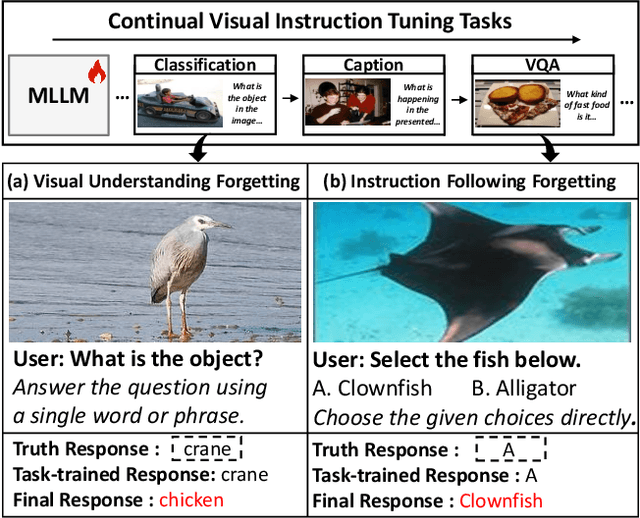
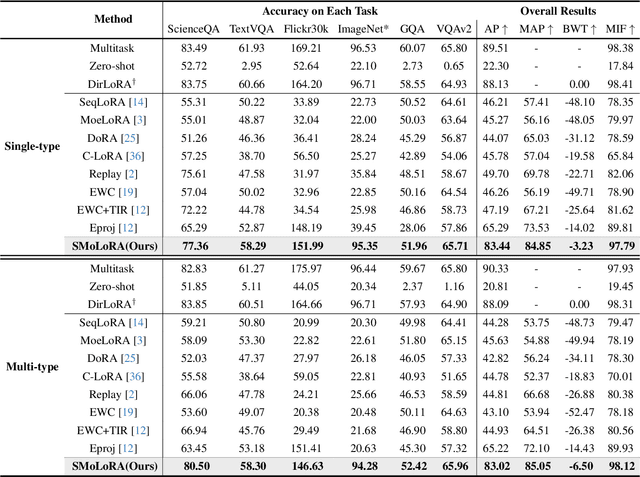
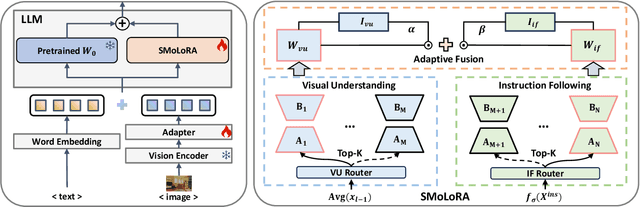
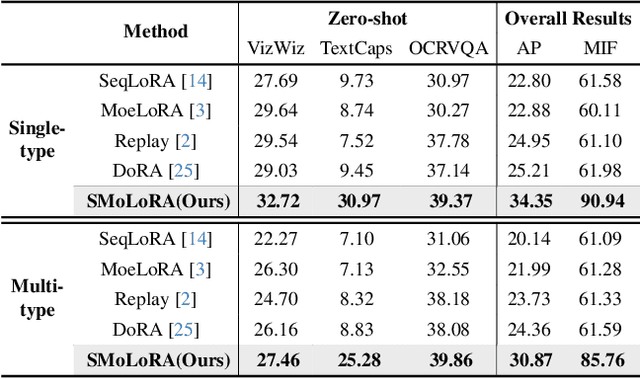
Visual instruction tuning (VIT) enables multimodal large language models (MLLMs) to effectively handle a wide range of vision tasks by framing them as language-based instructions. Building on this, continual visual instruction tuning (CVIT) extends the capability of MLLMs to incrementally learn new tasks, accommodating evolving functionalities. While prior work has advanced CVIT through the development of new benchmarks and approaches to mitigate catastrophic forgetting, these efforts largely follow traditional continual learning paradigms, neglecting the unique challenges specific to CVIT. We identify a dual form of catastrophic forgetting in CVIT, where MLLMs not only forget previously learned visual understanding but also experience a decline in instruction following abilities as they acquire new tasks. To address this, we introduce the Separable Mixture of Low-Rank Adaptation (SMoLoRA) framework, which employs separable routing through two distinct modules - one for visual understanding and another for instruction following. This dual-routing design enables specialized adaptation in both domains, preventing forgetting while improving performance. Furthermore, we propose a novel CVIT benchmark that goes beyond existing benchmarks by additionally evaluating a model's ability to generalize to unseen tasks and handle diverse instructions across various tasks. Extensive experiments demonstrate that SMoLoRA outperforms existing methods in mitigating dual forgetting, improving generalization to unseen tasks, and ensuring robustness in following diverse instructions.