 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Frequency-Aware Dynamic Transformers for All-In-One Image Restoration
Jun 30, 2024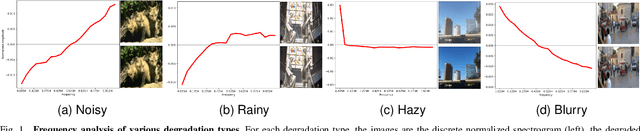
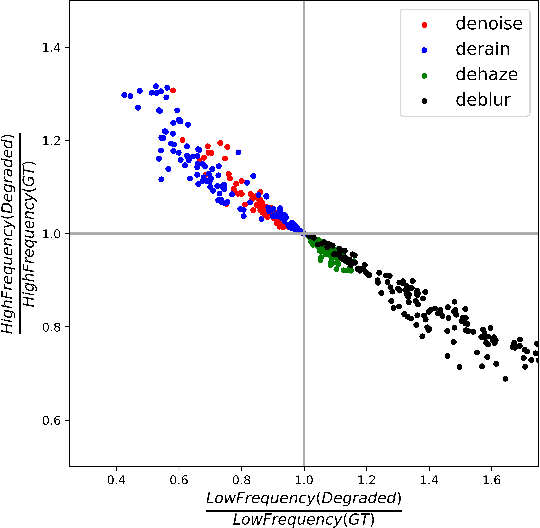
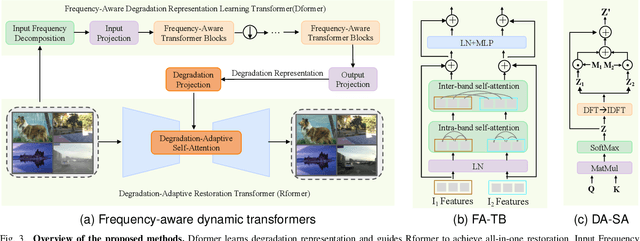

This work aims to tackle the all-in-one image restoration task, which seeks to handle multiple types of degradation with a single model. The primary challenge is to extract degradation representations from the input degraded images and use them to guide the model's adaptation to specific degradation types. Recognizing that various degradations affect image content differently across frequency bands, we propose a new all-in-one image restoration approach from a frequency perspective, leveraging advanced vision transformers. Our method consists of two main components: a frequency-aware Degradation prior learning transformer (Dformer) and a degradation-adaptive Restoration transformer (Rformer). The Dformer captures the essential characteristics of various degradations by decomposing inputs into different frequency components. By understanding how degradations affect these frequency components, the Dformer learns robust priors that effectively guide the restoration process. The Rformer then employs a degradation-adaptive self-attention module to selectively focus on the most affected frequency components, guided by the learned degradation representations. Extensive experimental results demonstrate that our approach outperforms the existing methods on four representative restoration tasks, including denoising, deraining, dehazing and deblurring. Additionally, our method offers benefits for handling spatially variant degradations and unseen degradation levels.
Densely Distilling Cumulative Knowledge for Continual Learning
May 16, 2024



Continual learning, involving sequential training on diverse tasks, often faces catastrophic forgetting. While knowledge distillation-based approaches exhibit notable success in preventing forgetting, we pinpoint a limitation in their ability to distill the cumulative knowledge of all the previous tasks. To remedy this, we propose Dense Knowledge Distillation (DKD). DKD uses a task pool to track the model's capabilities. It partitions the output logits of the model into dense groups, each corresponding to a task in the task pool. It then distills all tasks' knowledge using all groups. However, using all the groups can be computationally expensive, we also suggest random group selection in each optimization step. Moreover, we propose an adaptive weighting scheme, which balances the learning of new classes and the retention of old classes, based on the count and similarity of the classes. Our DKD outperforms recent state-of-the-art baselines across diverse benchmarks and scenarios. Empirical analysis underscores DKD's ability to enhance model stability, promote flatter minima for improved generalization, and remains robust across various memory budgets and task orders. Moreover, it seamlessly integrates with other CL methods to boost performance and proves versatile in offline scenarios like model compression.
Joint Face Completion and Super-resolution using Multi-scale Feature Relation Learning
Feb 29, 2020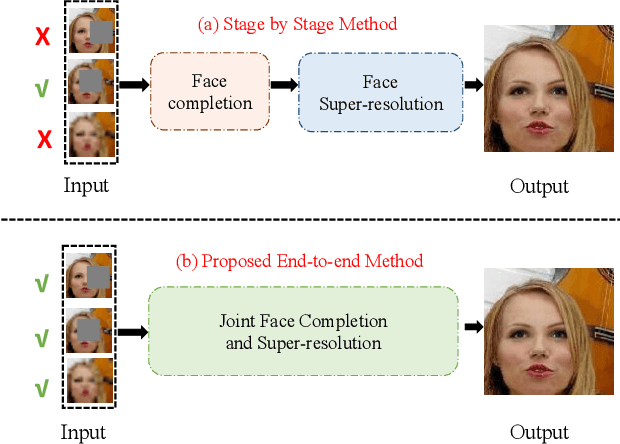
Previous research on face restoration often focused on repairing a specific type of low-quality facial images such as low-resolution (LR) or occluded facial images. However, in the real world, both the above-mentioned forms of image degradation often coexist. Therefore, it is important to design a model that can repair LR occluded images simultaneously. This paper proposes a multi-scale feature graph generative adversarial network (MFG-GAN) to implement the face restoration of images in which both degradation modes coexist, and also to repair images with a single type of degradation. Based on the GAN, the MFG-GAN integrates the graph convolution and feature pyramid network to restore occluded low-resolution face images to non-occluded high-resolution face images. The MFG-GAN uses a set of customized losses to ensure that high-quality images are generated. In addition, we designed the network in an end-to-end format. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms state-of-the-art methods in performing face super-resolution (up to 4x or 8x) and face completion simultaneously. Cross-database testing also revealed that the proposed approach has good generalizability.
Facial Expression Restoration Based on Improved Graph Convolutional Networks
Oct 23, 2019
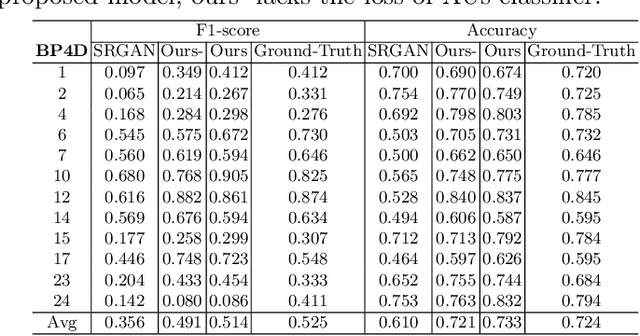
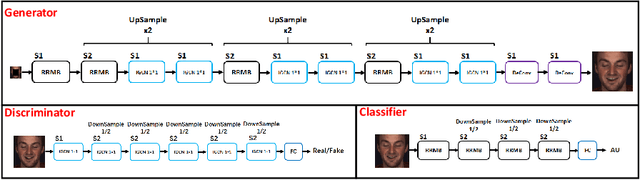

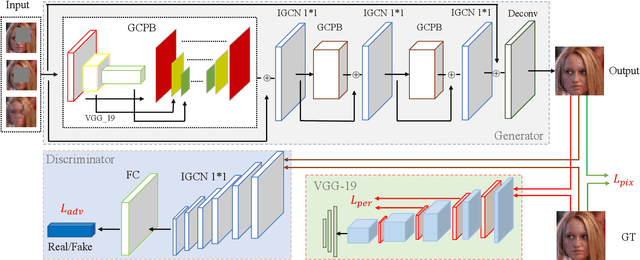
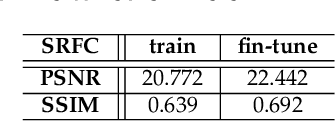
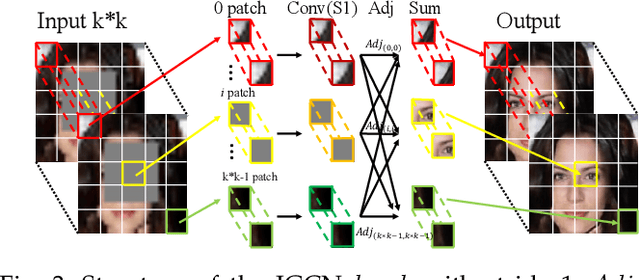
Facial expression analysis in the wild is challenging when the facial image is with low resolution or partial occlusion. Considering the correlations among different facial local regions under different facial expressions, this paper proposes a novel facial expression restoration method based on generative adversarial network by integrating an improved graph convolutional network (IGCN) and region relation modeling block (RRMB). Unlike conventional graph convolutional networks taking vectors as input features, IGCN can use tensors of face patches as inputs. It is better to retain the structure information of face patches. The proposed RRMB is designed to address facial generative tasks including inpainting and super-resolution with facial action units detection, which aims to restore facial expression as the ground-truth. Extensive experiments conducted on BP4D and DISFA benchmarks demonstrate the effectiveness of our proposed method through quantitative and qualitative evaluations.
Region Based Adversarial Synthesis of Facial Action Units
Oct 23, 2019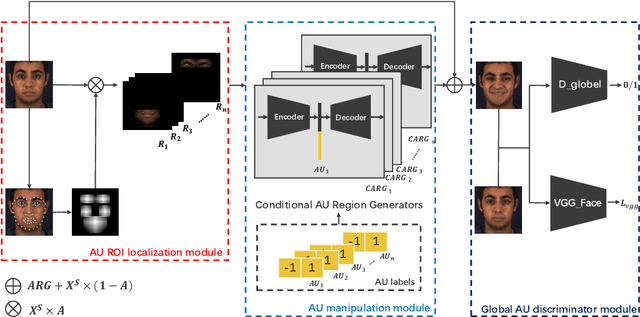
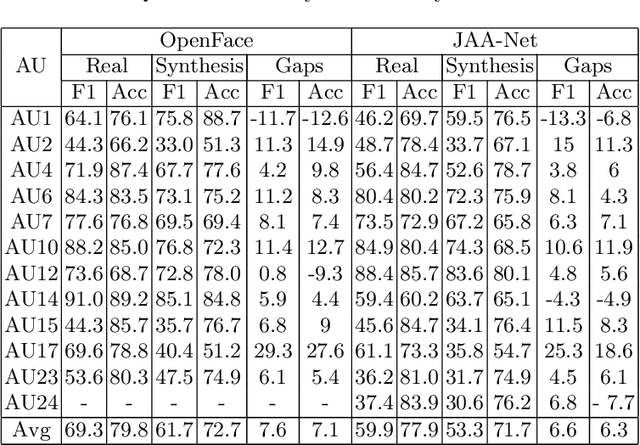
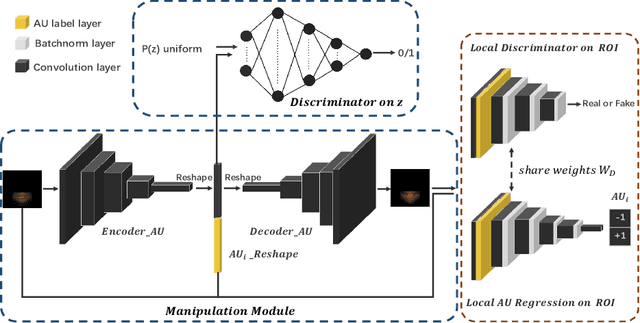
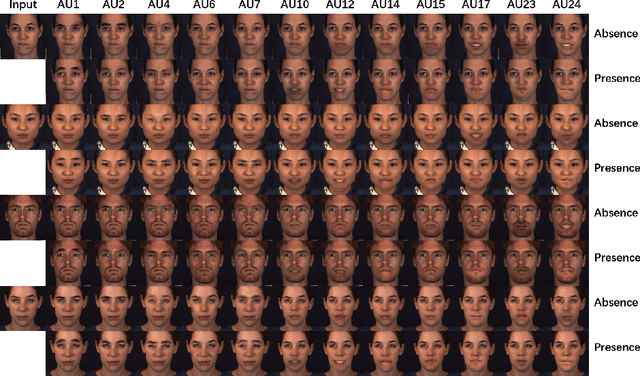
Facial expression synthesis or editing has recently received increasing attention in the field of affective computing and facial expression modeling. However, most existing facial expression synthesis works are limited in paired training data, low resolution, identity information damaging, and so on. To address those limitations, this paper introduces a novel Action Unit (AU) level facial expression synthesis method called Local Attentive Conditional Generative Adversarial Network (LAC-GAN) based on face action units annotations. Given desired AU labels, LAC-GAN utilizes local AU regional rules to control the status of each AU and attentive mechanism to combine several of them into the whole photo-realistic facial expressions or arbitrary facial expressions. In addition, unpaired training data is utilized in our proposed method to train the manipulation module with the corresponding AU labels, which learns a mapping between a facial expression manifold. Extensive qualitative and quantitative evaluations are conducted on the commonly used BP4D dataset to verify the effectiveness of our proposed AU synthesis method.