 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflecting Twice before Speaking with Empathy: Self-Reflective Alternating Inference for Empathy-Aware End-to-End Spoken Dialogue
Jan 26, 2026End-to-end Spoken Language Models (SLMs) hold great potential for paralinguistic perception, and numerous studies have aimed to enhance their capabilities, particularly for empathetic dialogue. However, current approaches largely depend on rigid supervised signals, such as ground-truth response in supervised fine-tuning or preference scores in reinforcement learning. Such reliance is fundamentally limited for modeling complex empathy, as there is no single "correct" response and a simple numerical score cannot fully capture the nuances of emotional expression or the appropriateness of empathetic behavior. To address these limitations, we sequentially introduce EmpathyEval, a descriptive natural-language-based evaluation model for assessing empathetic quality in spoken dialogues. Building upon EmpathyEval, we propose ReEmpathy, an end-to-end SLM that enhances empathetic dialogue through a novel Empathetic Self-Reflective Alternating Inference mechanism, which interleaves spoken response generation with free-form, empathy-related reflective reasoning. Extensive experiments demonstrate that ReEmpathy substantially improves empathy-sensitive spoken dialogue by enabling reflective reasoning, offering a promising approach toward more emotionally intelligent and empathy-aware human-computer interactions.
Multi-Waveguide Pinching Antenna Placement Optimization for Rate Maximization
Dec 21, 2025Pinching antenna systems (PASS) have emerged as a technology that enables the large-scale movement of antenna elements, offering significant potential for performance gains in next-generation wireless networks. This paper investigates the problem of maximizing the average per-user data rate by optimizing the antenna placement of a multi-waveguide PASS, subject to a stringent physical minimum spacing constraint. To address this complex challenge, which involves a coupled fractional objective and a non-convex constraint, we employ the fractional programming (FP) framework to transform the non-convex rate maximization problem into a more tractable one, and devise a projected gradient ascent (PGA)-based algorithm to iteratively solve the transformed problem. Simulation results demonstrate that our proposed scheme significantly outperforms various geometric placement baselines, achieving superior per-user data rates by actively mitigating multi-user interference.
DSDrive: Distilling Large Language Model for Lightweight End-to-End Autonomous Driving with Unified Reasoning and Planning
May 08, 2025We present DSDrive, a streamlined end-to-end paradigm tailored for integrating the reasoning and planning of autonomous vehicles into a unified framework. DSDrive leverages a compact LLM that employs a distillation method to preserve the enhanced reasoning capabilities of a larger-sized vision language model (VLM). To effectively align the reasoning and planning tasks, a waypoint-driven dual-head coordination module is further developed, which synchronizes dataset structures, optimization objectives, and the learning process. By integrating these tasks into a unified framework, DSDrive anchors on the planning results while incorporating detailed reasoning insights, thereby enhancing the interpretability and reliability of the end-to-end pipeline. DSDrive has been thoroughly tested in closed-loop simulations, where it performs on par with benchmark models and even outperforms in many key metrics, all while being more compact in size. Additionally, the computational efficiency of DSDrive (as reflected in its time and memory requirements during inference) has been significantly enhanced. Evidently thus, this work brings promising aspects and underscores the potential of lightweight systems in delivering interpretable and efficient solutions for AD.
Motion-Enhanced Nonlocal Similarity Implicit Neural Representation for Infrared Dim and Small Target Detection
Apr 22, 2025Infrared dim and small target detection presents a significant challenge due to dynamic multi-frame scenarios and weak target signatures in the infrared modality. Traditional low-rank plus sparse models often fail to capture dynamic backgrounds and global spatial-temporal correlations, which results in background leakage or target loss. In this paper, we propose a novel motion-enhanced nonlocal similarity implicit neural representation (INR) framework to address these challenges. We first integrate motion estimation via optical flow to capture subtle target movements, and propose multi-frame fusion to enhance motion saliency. Second, we leverage nonlocal similarity to construct patch tensors with strong low-rank properties, and propose an innovative tensor decomposition-based INR model to represent the nonlocal patch tensor, effectively encoding both the nonlocal low-rankness and spatial-temporal correlations of background through continuous neural representations. An alternating direction method of multipliers is developed for the nonlocal INR model, which enjoys theoretical fixed-point convergence. Experimental results show that our approach robustly separates dim targets from complex infrared backgrounds, outperforming state-of-the-art methods in detection accuracy and robustness.
Efficient Temporal Consistency in Diffusion-Based Video Editing with Adaptor Modules: A Theoretical Framework
Apr 22, 2025Adapter-based methods are commonly used to enhance model performance with minimal additional complexity, especially in video editing tasks that require frame-to-frame consistency. By inserting small, learnable modules into pretrained diffusion models, these adapters can maintain temporal coherence without extensive retraining. Approaches that incorporate prompt learning with both shared and frame-specific tokens are particularly effective in preserving continuity across frames at low training cost. In this work, we want to provide a general theoretical framework for adapters that maintain frame consistency in DDIM-based models under a temporal consistency loss. First, we prove that the temporal consistency objective is differentiable under bounded feature norms, and we establish a Lipschitz bound on its gradient. Second, we show that gradient descent on this objective decreases the loss monotonically and converges to a local minimum if the learning rate is within an appropriate range. Finally, we analyze the stability of modules in the DDIM inversion procedure, showing that the associated error remains controlled. These theoretical findings will reinforce the reliability of diffusion-based video editing methods that rely on adapter strategies and provide theoretical insights in video generation tasks.
HM-RAG: Hierarchical Multi-Agent Multimodal Retrieval Augmented Generation
Apr 13, 2025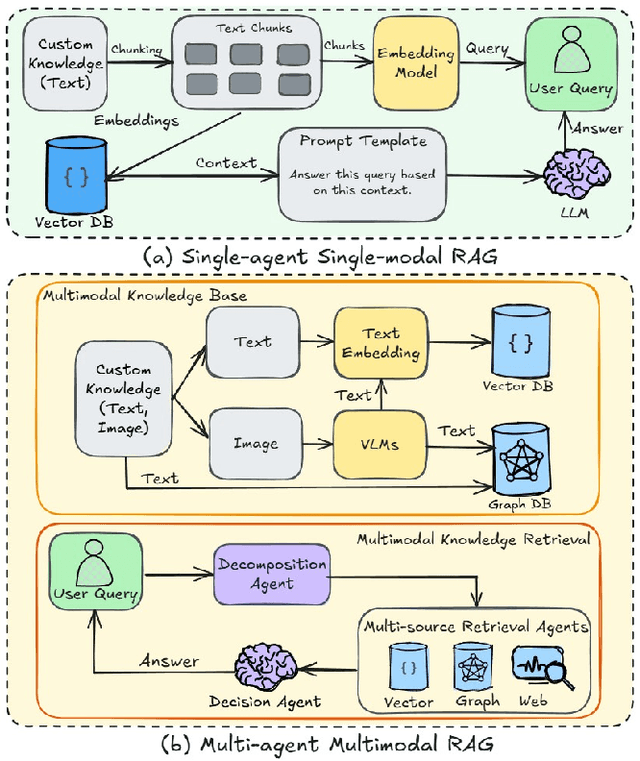
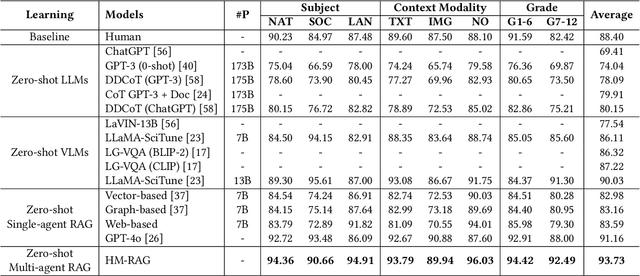
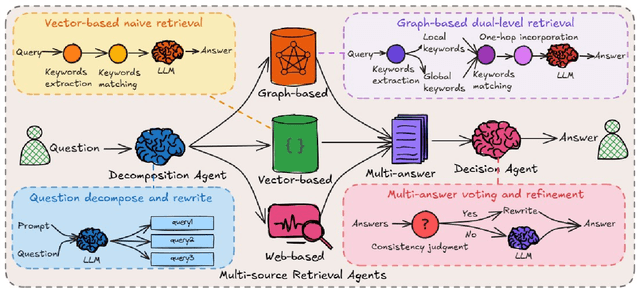
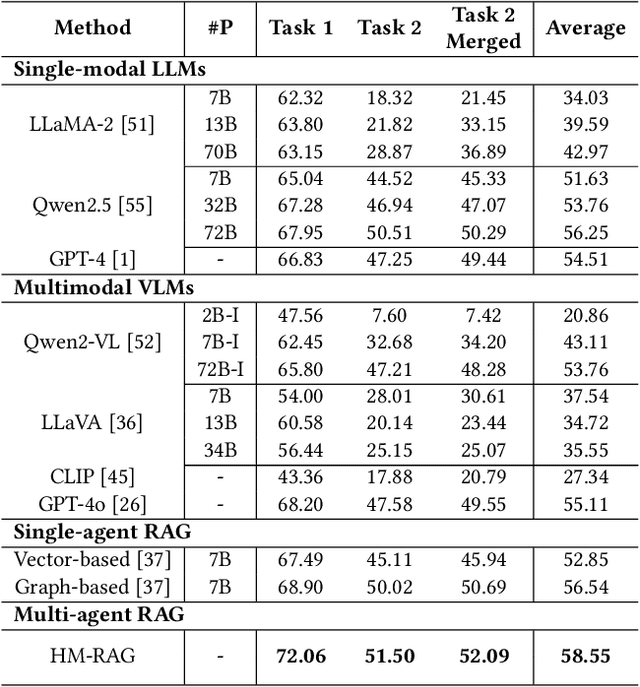
While Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge, conventional single-agent RAG remains fundamentally limited in resolving complex queries demanding coordinated reasoning across heterogeneous data ecosystems. We present HM-RAG, a novel Hierarchical Multi-agent Multimodal RAG framework that pioneers collaborative intelligence for dynamic knowledge synthesis across structured, unstructured, and graph-based data. The framework is composed of three-tiered architecture with specialized agents: a Decomposition Agent that dissects complex queries into contextually coherent sub-tasks via semantic-aware query rewriting and schema-guided context augmentation; Multi-source Retrieval Agents that carry out parallel, modality-specific retrieval using plug-and-play modules designed for vector, graph, and web-based databases; and a Decision Agent that uses consistency voting to integrate multi-source answers and resolve discrepancies in retrieval results through Expert Model Refinement. This architecture attains comprehensive query understanding by combining textual, graph-relational, and web-derived evidence, resulting in a remarkable 12.95% improvement in answer accuracy and a 3.56% boost in question classification accuracy over baseline RAG systems on the ScienceQA and CrisisMMD benchmarks. Notably, HM-RAG establishes state-of-the-art results in zero-shot settings on both datasets. Its modular architecture ensures seamless integration of new data modalities while maintaining strict data governance, marking a significant advancement in addressing the critical challenges of multimodal reasoning and knowledge synthesis in RAG systems. Code is available at https://github.com/ocean-luna/HMRAG.
Leveraging Line-of-Sight Propagation for Near-Field Beamfocusing in Cell-Free Networks
Mar 27, 2025Cell-free (CF) massive multiple-input multiple-output (MIMO) is a promising approach for next-generation wireless networks, enabling scalable deployments of multiple small access points (APs) to enhance coverage and service for multiple user equipments (UEs). While most existing research focuses on low-frequency bands with Rayleigh fading models, emerging 5G trends are shifting toward higher frequencies, where geometric channel models and line-of-sight (LoS) propagation become more relevant. In this work, we explore how distributed massive MIMO in the LoS regime can achieve near-field-like conditions by forming artificially large arrays through coordinated AP deployments. We investigate centralized and decentralized CF architectures, leveraging structured channel estimation (SCE) techniques that exploit the line-of-sight properties of geometric channels. Our results demonstrate that dense distributed AP deployments significantly improve system performance w.r.t. the case of a co-located array, even in highly populated UE scenarios, while SCE approaches the performance of perfect CSI.
IQPFR: An Image Quality Prior for Blind Face Restoration and Beyond
Mar 12, 2025Blind Face Restoration (BFR) addresses the challenge of reconstructing degraded low-quality (LQ) facial images into high-quality (HQ) outputs. Conventional approaches predominantly rely on learning feature representations from ground-truth (GT) data; however, inherent imperfections in GT datasets constrain restoration performance to the mean quality level of the training data, rather than attaining maximally attainable visual quality. To overcome this limitation, we propose a novel framework that incorporates an Image Quality Prior (IQP) derived from No-Reference Image Quality Assessment (NR-IQA) models to guide the restoration process toward optimal HQ reconstructions. Our methodology synergizes this IQP with a learned codebook prior through two critical innovations: (1) During codebook learning, we devise a dual-branch codebook architecture that disentangles feature extraction into universal structural components and HQ-specific attributes, ensuring comprehensive representation of both common and high-quality facial characteristics. (2) In the codebook lookup stage, we implement a quality-conditioned Transformer-based framework. NR-IQA-derived quality scores act as dynamic conditioning signals to steer restoration toward the highest feasible quality standard. This score-conditioned paradigm enables plug-and-play enhancement of existing BFR architectures without modifying the original structure. We also formulate a discrete representation-based quality optimization strategy that circumvents over-optimization artifacts prevalent in continuous latent space approaches. Extensive experiments demonstrate that our method outperforms state-of-the-art techniques across multiple benchmarks. Besides, our quality-conditioned framework demonstrates consistent performance improvements when integrated with prior BFR models. The code will be released.
VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion
Feb 25, 2025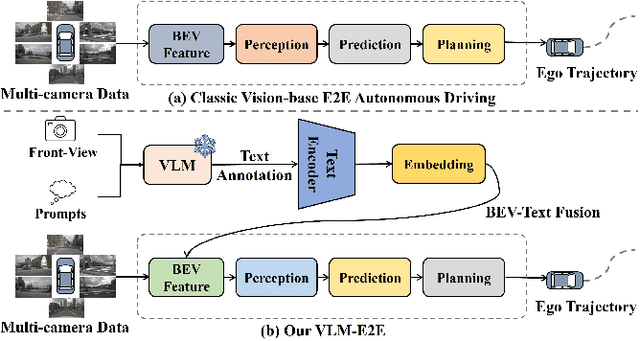
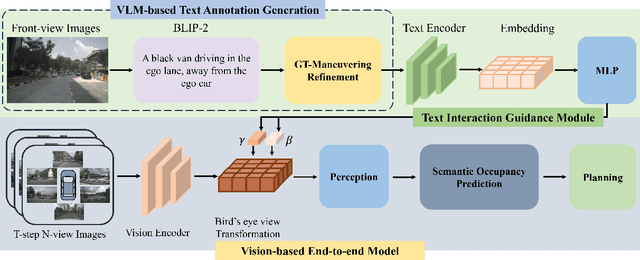
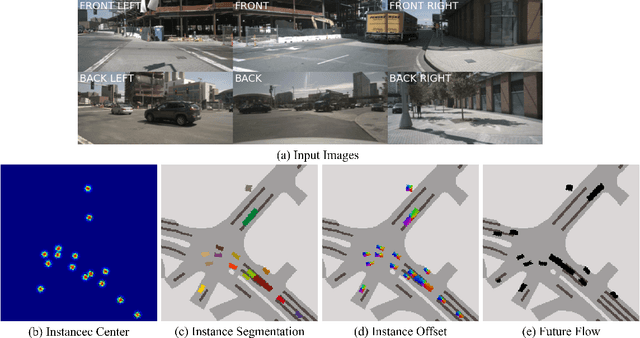
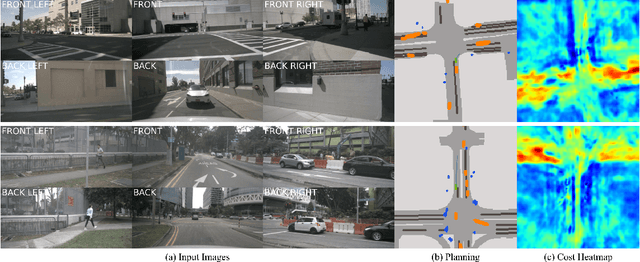
Human drivers adeptly navigate complex scenarios by utilizing rich attentional semantics, but the current autonomous systems struggle to replicate this ability, as they often lose critical semantic information when converting 2D observations into 3D space. In this sense, it hinders their effective deployment in dynamic and complex environments. Leveraging the superior scene understanding and reasoning abilities of Vision-Language Models (VLMs), we propose VLM-E2E, a novel framework that uses the VLMs to enhance training by providing attentional cues. Our method integrates textual representations into Bird's-Eye-View (BEV) features for semantic supervision, which enables the model to learn richer feature representations that explicitly capture the driver's attentional semantics. By focusing on attentional semantics, VLM-E2E better aligns with human-like driving behavior, which is critical for navigating dynamic and complex environments. Furthermore, we introduce a BEV-Text learnable weighted fusion strategy to address the issue of modality importance imbalance in fusing multimodal information. This approach dynamically balances the contributions of BEV and text features, ensuring that the complementary information from visual and textual modality is effectively utilized. By explicitly addressing the imbalance in multimodal fusion, our method facilitates a more holistic and robust representation of driving environments. We evaluate VLM-E2E on the nuScenes dataset and demonstrate its superiority over state-of-the-art approaches, showcasing significant improvements in performance.
Enhancing Crash Frequency Modeling Based on Augmented Multi-Type Data by Hybrid VAE-Diffusion-Based Generative Neural Networks
Jan 17, 2025Crash frequency modelling analyzes the impact of factors like traffic volume, road geometry, and environmental conditions on crash occurrences. Inaccurate predictions can distort our understanding of these factors, leading to misguided policies and wasted resources, which jeopardize traffic safety. A key challenge in crash frequency modelling is the prevalence of excessive zero observations, caused by underreporting, the low probability of crashes, and high data collection costs. These zero observations often reduce model accuracy and introduce bias, complicating safety decision making. While existing approaches, such as statistical methods, data aggregation, and resampling, attempt to address this issue, they either rely on restrictive assumptions or result in significant information loss, distorting crash data. To overcome these limitations, we propose a hybrid VAE-Diffusion neural network, designed to reduce zero observations and handle the complexities of multi-type tabular crash data (count, ordinal, nominal, and real-valued variables). We assess the synthetic data quality generated by this model through metrics like similarity, accuracy, diversity, and structural consistency, and compare its predictive performance against traditional statistical models. Our findings demonstrate that the hybrid VAE-Diffusion model outperforms baseline models across all metrics, offering a more effective approach to augmenting crash data and improving the accuracy of crash frequency predictions. This study highlights the potential of synthetic data to enhance traffic safety by improving crash frequency modelling and informing better policy decisions.