 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Temporal Consistency in Diffusion-Based Video Editing with Adaptor Modules: A Theoretical Framework
Apr 22, 2025Adapter-based methods are commonly used to enhance model performance with minimal additional complexity, especially in video editing tasks that require frame-to-frame consistency. By inserting small, learnable modules into pretrained diffusion models, these adapters can maintain temporal coherence without extensive retraining. Approaches that incorporate prompt learning with both shared and frame-specific tokens are particularly effective in preserving continuity across frames at low training cost. In this work, we want to provide a general theoretical framework for adapters that maintain frame consistency in DDIM-based models under a temporal consistency loss. First, we prove that the temporal consistency objective is differentiable under bounded feature norms, and we establish a Lipschitz bound on its gradient. Second, we show that gradient descent on this objective decreases the loss monotonically and converges to a local minimum if the learning rate is within an appropriate range. Finally, we analyze the stability of modules in the DDIM inversion procedure, showing that the associated error remains controlled. These theoretical findings will reinforce the reliability of diffusion-based video editing methods that rely on adapter strategies and provide theoretical insights in video generation tasks.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025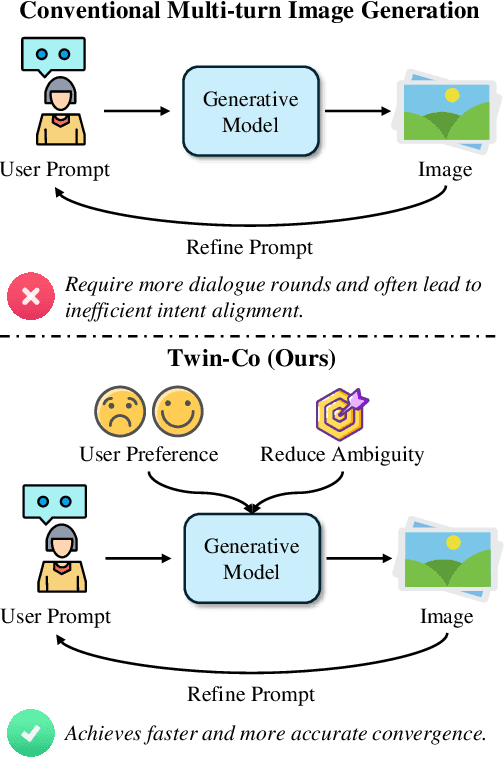
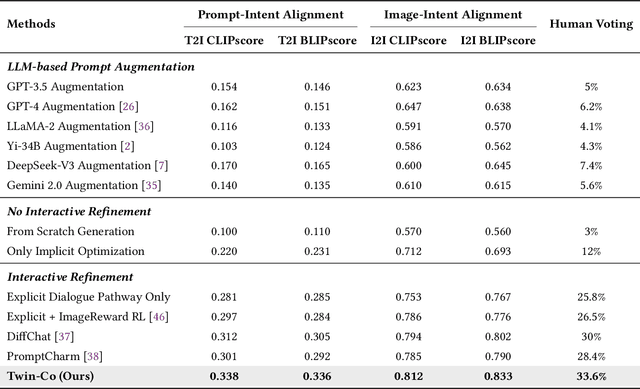
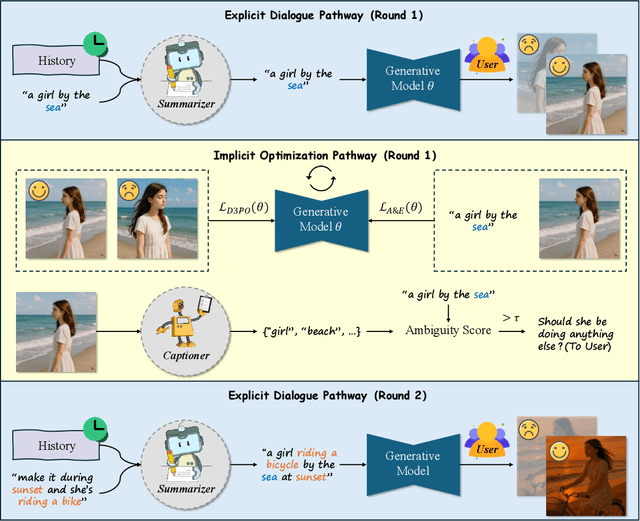

Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection
Jul 04, 2023



A critical yet frequently overlooked challenge in the field of deepfake detection is the lack of a standardized, unified, comprehensive benchmark. This issue leads to unfair performance comparisons and potentially misleading results. Specifically, there is a lack of uniformity in data processing pipelines, resulting in inconsistent data inputs for detection models. Additionally, there are noticeable differences in experimental settings, and evaluation strategies and metrics lack standardization. To fill this gap, we present the first comprehensive benchmark for deepfake detection, called DeepfakeBench, which offers three key contributions: 1) a unified data management system to ensure consistent input across all detectors, 2) an integrated framework for state-of-the-art methods implementation, and 3) standardized evaluation metrics and protocols to promote transparency and reproducibility. Featuring an extensible, modular-based codebase, DeepfakeBench contains 15 state-of-the-art detection methods, 9 deepfake datasets, a series of deepfake detection evaluation protocols and analysis tools, as well as comprehensive evaluations. Moreover, we provide new insights based on extensive analysis of these evaluations from various perspectives (e.g., data augmentations, backbones). We hope that our efforts could facilitate future research and foster innovation in this increasingly critical domain. All codes, evaluations, and analyses of our benchmark are publicly available at https://github.com/SCLBD/DeepfakeBench.