 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Sparsity Mitigate the Curse of Depth in LLMs
Mar 16, 2026Recent work has demonstrated the curse of depth in large language models (LLMs), where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixtureof-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training deptheffective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs. Code is available at https://github.com/pUmpKin-Co/SparsityAndCoD.
DICArt: Advancing Category-level Articulated Object Pose Estimation in Discrete State-Spaces
Feb 26, 2026Articulated object pose estimation is a core task in embodied AI. Existing methods typically regress poses in a continuous space, but often struggle with 1) navigating a large, complex search space and 2) failing to incorporate intrinsic kinematic constraints. In this work, we introduce DICArt (DIsCrete Diffusion for Articulation Pose Estimation), a novel framework that formulates pose estimation as a conditional discrete diffusion process. Instead of operating in a continuous domain, DICArt progressively denoises a noisy pose representation through a learned reverse diffusion procedure to recover the GT pose. To improve modeling fidelity, we propose a flexible flow decider that dynamically determines whether each token should be denoised or reset, effectively balancing the real and noise distributions during diffusion. Additionally, we incorporate a hierarchical kinematic coupling strategy, estimating the pose of each rigid part hierarchically to respect the object's kinematic structure. We validate DICArt on both synthetic and real-world datasets. Experimental results demonstrate its superior performance and robustness. By integrating discrete generative modeling with structural priors, DICArt offers a new paradigm for reliable category-level 6D pose estimation in complex environments.
Manifold-Aware Temporal Domain Generalization for Large Language Models
Feb 12, 2026Temporal distribution shifts are pervasive in real-world deployments of Large Language Models (LLMs), where data evolves continuously over time. While Temporal Domain Generalization (TDG) seeks to model such structured evolution, existing approaches characterize model adaptation in the full parameter space. This formulation becomes computationally infeasible for modern LLMs. This paper introduces a geometric reformulation of TDG under parameter-efficient fine-tuning. We establish that the low-dimensional temporal structure underlying model evolution can be preserved under parameter-efficient reparameterization, enabling temporal modeling without operating in the ambient parameter space. Building on this principle, we propose Manifold-aware Temporal LoRA (MaT-LoRA), which constrains temporal updates to a shared low-dimensional manifold within a low-rank adaptation subspace, and models its evolution through a structured temporal core. This reparameterization dramatically reduces temporal modeling complexity while retaining expressive power. Extensive experiments on synthetic and real-world datasets, including scientific documents, news publishers, and review ratings, demonstrate that MaT-LoRA achieves superior temporal generalization performance with practical scalability for LLMs.
Improving Medical Visual Reinforcement Fine-Tuning via Perception and Reasoning Augmentation
Feb 11, 2026While recent advances in Reinforcement Fine-Tuning (RFT) have shown that rule-based reward schemes can enable effective post-training for large language models, their extension to cross-modal, vision-centric domains remains largely underexplored. This limitation is especially pronounced in the medical imaging domain, where effective performance requires both robust visual perception and structured reasoning. In this work, we address this gap by proposing VRFT-Aug, a visual reinforcement fine-tuning framework tailored for the medical domain. VRFT-Aug introduces a series of training strategies designed to augment both perception and reasoning, including prior knowledge injection, perception-driven policy refinement, medically informed reward shaping, and behavioral imitation. Together, these methods aim to stabilize and improve the RFT process. Through extensive experiments across multiple medical datasets, we show that our approaches consistently outperform both standard supervised fine-tuning and RFT baselines. Moreover, we provide empirically grounded insights and practical training heuristics that can be generalized to other medical image tasks. We hope this work contributes actionable guidance and fresh inspiration for the ongoing effort to develop reliable, reasoning-capable models for high-stakes medical applications.
Learning to Recommend Multi-Agent Subgraphs from Calling Trees
Jan 29, 2026Multi-agent systems (MAS) increasingly solve complex tasks by orchestrating agents and tools selected from rapidly growing marketplaces. As these marketplaces expand, many candidates become functionally overlapping, making selection not just a retrieval problem: beyond filtering relevant agents, an orchestrator must choose options that are reliable, compatible with the current execution context, and able to cooperate with other selected agents. Existing recommender systems -- largely built for item-level ranking from flat user-item logs -- do not directly address the structured, sequential, and interaction-dependent nature of agent orchestration. We address this gap by \textbf{formulating agent recommendation in MAS as a constrained decision problem} and introducing a generic \textbf{constrained recommendation framework} that first uses retrieval to build a compact candidate set conditioned on the current subtask and context, and then performs \textbf{utility optimization} within this feasible set using a learned scorer that accounts for relevance, reliability, and interaction effects. We ground both the formulation and learning signals in \textbf{historical calling trees}, which capture the execution structure of MAS (parent-child calls, branching dependencies, and local cooperation patterns) beyond what flat logs provide. The framework supports two complementary settings: \textbf{agent-level recommendation} (select the next agent/tool) and \textbf{system-level recommendation} (select a small, connected agent team/subgraph for coordinated execution). To enable systematic evaluation, we construct a unified calling-tree benchmark by normalizing invocation logs from eight heterogeneous multi-agent corpora into a shared structured representation.
Speculative Decoding in Decentralized LLM Inference: Turning Communication Latency into Computation Throughput
Nov 13, 2025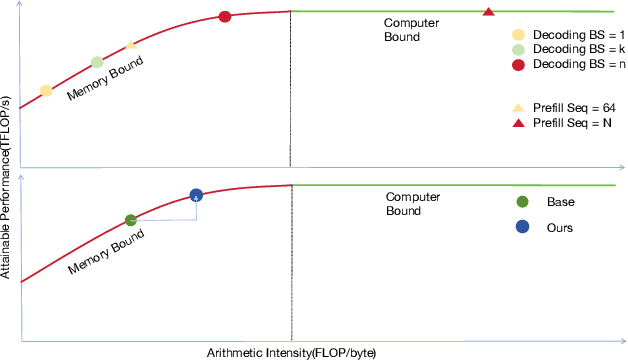
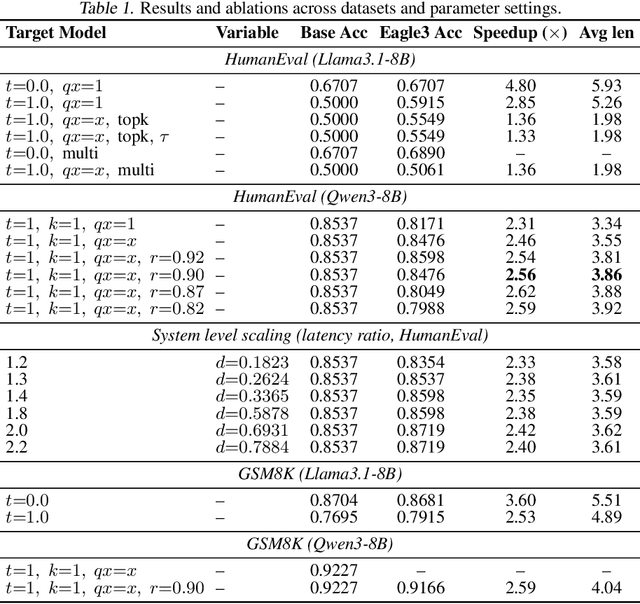

Speculative decoding accelerates large language model (LLM) inference by using a lightweight draft model to propose tokens that are later verified by a stronger target model. While effective in centralized systems, its behavior in decentralized settings, where network latency often dominates compute, remains under-characterized. We present Decentralized Speculative Decoding (DSD), a plug-and-play framework for decentralized inference that turns communication delay into useful computation by verifying multiple candidate tokens in parallel across distributed nodes. We further introduce an adaptive speculative verification strategy that adjusts acceptance thresholds by token-level semantic importance, delivering an additional 15% to 20% end-to-end speedup without retraining. In theory, DSD reduces cross-node communication cost by approximately (N-1)t1(k-1)/k, where t1 is per-link latency and k is the average number of tokens accepted per round. In practice, DSD achieves up to 2.56x speedup on HumanEval and 2.59x on GSM8K, surpassing the Eagle3 baseline while preserving accuracy. These results show that adapting speculative decoding for decentralized execution provides a system-level optimization that converts network stalls into throughput, enabling faster distributed LLM inference with no model retraining or architectural changes.
CoT-X: An Adaptive Framework for Cross-Model Chain-of-Thought Transfer and Optimization
Nov 07, 2025



Chain-of-Thought (CoT) reasoning enhances the problem-solving ability of large language models (LLMs) but leads to substantial inference overhead, limiting deployment in resource-constrained settings. This paper investigates efficient CoT transfer across models of different scales and architectures through an adaptive reasoning summarization framework. The proposed method compresses reasoning traces via semantic segmentation with importance scoring, budget-aware dynamic compression, and coherence reconstruction, preserving critical reasoning steps while significantly reducing token usage. Experiments on 7{,}501 medical examination questions across 10 specialties show up to 40% higher accuracy than truncation under the same token budgets. Evaluations on 64 model pairs from eight LLMs (1.5B-32B parameters, including DeepSeek-R1 and Qwen3) confirm strong cross-model transferability. Furthermore, a Gaussian Process-based Bayesian optimization module reduces evaluation cost by 84% and reveals a power-law relationship between model size and cross-domain robustness. These results demonstrate that reasoning summarization provides a practical path toward efficient CoT transfer, enabling advanced reasoning under tight computational constraints. Code will be released upon publication.
AutoSurvey2: Empowering Researchers with Next Level Automated Literature Surveys
Oct 29, 2025The rapid growth of research literature, particularly in large language models (LLMs), has made producing comprehensive and current survey papers increasingly difficult. This paper introduces autosurvey2, a multi-stage pipeline that automates survey generation through retrieval-augmented synthesis and structured evaluation. The system integrates parallel section generation, iterative refinement, and real-time retrieval of recent publications to ensure both topical completeness and factual accuracy. Quality is assessed using a multi-LLM evaluation framework that measures coverage, structure, and relevance in alignment with expert review standards. Experimental results demonstrate that autosurvey2 consistently outperforms existing retrieval-based and automated baselines, achieving higher scores in structural coherence and topical relevance while maintaining strong citation fidelity. By combining retrieval, reasoning, and automated evaluation into a unified framework, autosurvey2 provides a scalable and reproducible solution for generating long-form academic surveys and contributes a solid foundation for future research on automated scholarly writing. All code and resources are available at https://github.com/annihi1ation/auto_research.
Demystifying the Roles of LLM Layers in Retrieval, Knowledge, and Reasoning
Oct 02, 2025Recent studies suggest that the deeper layers of Large Language Models (LLMs) contribute little to representation learning and can often be removed without significant performance loss. However, such claims are typically drawn from narrow evaluations and may overlook important aspects of model behavior. In this work, we present a systematic study of depth utilization across diverse dimensions, including evaluation protocols, task categories, and model architectures. Our analysis confirms that very deep layers are generally less effective than earlier ones, but their contributions vary substantially with the evaluation setting. Under likelihood-based metrics without generation, pruning most layers preserves performance, with only the initial few being critical. By contrast, generation-based evaluation uncovers indispensable roles for middle and deeper layers in enabling reasoning and maintaining long-range coherence. We further find that knowledge and retrieval are concentrated in shallow components, whereas reasoning accuracy relies heavily on deeper layers -- yet can be reshaped through distillation. These results highlight that depth usage in LLMs is highly heterogeneous and context-dependent, underscoring the need for task-, metric-, and model-aware perspectives in both interpreting and compressing large models.
SEDM: Scalable Self-Evolving Distributed Memory for Agents
Sep 11, 2025Long-term multi-agent systems inevitably generate vast amounts of trajectories and historical interactions, which makes efficient memory management essential for both performance and scalability. Existing methods typically depend on vector retrieval and hierarchical storage, yet they are prone to noise accumulation, uncontrolled memory expansion, and limited generalization across domains. To address these challenges, we present SEDM, Self-Evolving Distributed Memory, a verifiable and adaptive framework that transforms memory from a passive repository into an active, self-optimizing component. SEDM integrates verifiable write admission based on reproducible replay, a self-scheduling memory controller that dynamically ranks and consolidates entries according to empirical utility, and cross-domain knowledge diffusion that abstracts reusable insights to support transfer across heterogeneous tasks. Evaluations on benchmark datasets demonstrate that SEDM improves reasoning accuracy while reducing token overhead compared with strong memory baselines, and further enables knowledge distilled from fact verification to enhance multi-hop reasoning. The results highlight SEDM as a scalable and sustainable memory mechanism for open-ended multi-agent collaboration. The code will be released in the later stage of this project.