 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Ordering of Channel and Spatial Attention: A Comprehensive Study on Sequential and Parallel Designs
Jan 12, 2026Attention mechanisms have become a core component of deep learning models, with Channel Attention and Spatial Attention being the two most representative architectures. Current research on their fusion strategies primarily bifurcates into sequential and parallel paradigms, yet the selection process remains largely empirical, lacking systematic analysis and unified principles. We systematically compare channel-spatial attention combinations under a unified framework, building an evaluation suite of 18 topologies across four classes: sequential, parallel, multi-scale, and residual. Across two vision and nine medical datasets, we uncover a "data scale-method-performance" coupling law: (1) in few-shot tasks, the "Channel-Multi-scale Spatial" cascaded structure achieves optimal performance; (2) in medium-scale tasks, parallel learnable fusion architectures demonstrate superior results; (3) in large-scale tasks, parallel structures with dynamic gating yield the best performance. Additionally, experiments indicate that the "Spatial-Channel" order is more stable and effective for fine-grained classification, while residual connections mitigate vanishing gradient problems across varying data scales. We thus propose scenario-based guidelines for building future attention modules. Code is open-sourced at https://github.com/DWlzm.
Semi-Supervised Multi-Label Feature Selection with Consistent Sparse Graph Learning
May 23, 2025In practical domains, high-dimensional data are usually associated with diverse semantic labels, whereas traditional feature selection methods are designed for single-label data. Moreover, existing multi-label methods encounter two main challenges in semi-supervised scenarios: (1). Most semi-supervised methods fail to evaluate the label correlations without enough labeled samples, which are the critical information of multi-label feature selection, making label-specific features discarded. (2). The similarity graph structure directly derived from the original feature space is suboptimal for multi-label problems in existing graph-based methods, leading to unreliable soft labels and degraded feature selection performance. To overcome them, we propose a consistent sparse graph learning method for multi-label semi-supervised feature selection (SGMFS), which can enhance the feature selection performance by maintaining space consistency and learning label correlations in semi-supervised scenarios. Specifically, for Challenge (1), SGMFS learns a low-dimensional and independent label subspace from the projected features, which can compatibly cross multiple labels and effectively achieve the label correlations. For Challenge (2), instead of constructing a fixed similarity graph for semi-supervised learning, SGMFS thoroughly explores the intrinsic structure of the data by performing sparse reconstruction of samples in both the label space and the learned subspace simultaneously. In this way, the similarity graph can be adaptively learned to maintain the consistency between label space and the learned subspace, which can promote propagating proper soft labels for unlabeled samples, facilitating the ultimate feature selection. An effective solution with fast convergence is designed to optimize the objective function. Extensive experiments validate the superiority of SGMFS.
Multi-label Causal Variable Discovery: Learning Common Causal Variables and Label-specific Causal Variables
Nov 09, 2020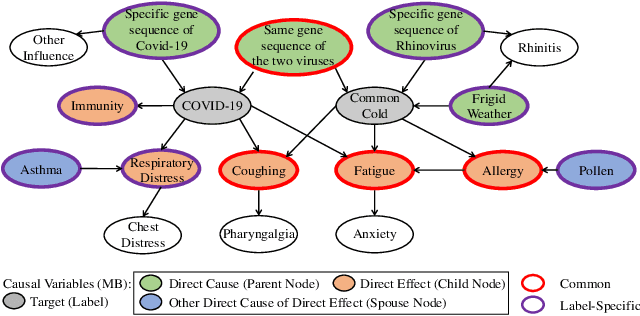
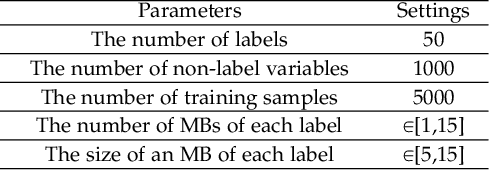


Causal variables in Markov boundary (MB) have been widely applied in extensive single-label tasks. While few researches focus on the causal variable discovery in multi-label data due to the complex causal relationships. Since some variables in multi-label scenario might contain causal information about multiple labels, this paper investigates the problem of multi-label causal variable discovery as well as the distinguishing between common causal variables shared by multiple labels and label-specific causal variables associated with some single labels. Considering the multiple MBs under the non-positive joint probability distribution, we explore the relationships between common causal variables and equivalent information phenomenon, and find that the solutions are influenced by equivalent information following different mechanisms with or without existence of label causality. Analyzing these mechanisms, we provide the theoretical property of common causal variables, based on which the discovery and distinguishing algorithm is designed to identify these two types of variables. Similar to single-label problem, causal variables for multiple labels also have extensive application prospects. To demonstrate this, we apply the proposed causal mechanism to multi-label feature selection and present an interpretable algorithm, which is proved to achieve the minimal redundancy and the maximum relevance. Extensive experiments demonstrate the efficacy of these contributions.
Probabilistic Classification Vector Machine for Multi-Class Classification
Jun 29, 2020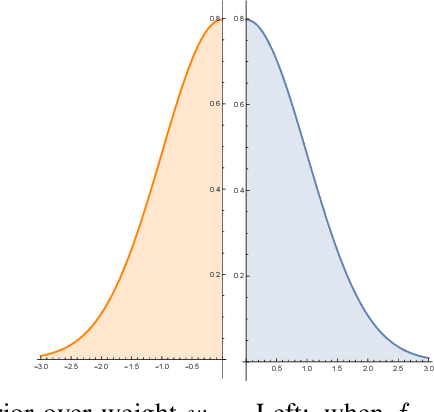



The probabilistic classification vector machine (PCVM) synthesizes the advantages of both the support vector machine and the relevant vector machine, delivering a sparse Bayesian solution to classification problems. However, the PCVM is currently only applicable to binary cases. Extending the PCVM to multi-class cases via heuristic voting strategies such as one-vs-rest or one-vs-one often results in a dilemma where classifiers make contradictory predictions, and those strategies might lose the benefits of probabilistic outputs. To overcome this problem, we extend the PCVM and propose a multi-class probabilistic classification vector machine (mPCVM). Two learning algorithms, i.e., one top-down algorithm and one bottom-up algorithm, have been implemented in the mPCVM. The top-down algorithm obtains the maximum a posteriori (MAP) point estimates of the parameters based on an expectation-maximization algorithm, and the bottom-up algorithm is an incremental paradigm by maximizing the marginal likelihood. The superior performance of the mPCVMs, especially when the investigated problem has a large number of classes, is extensively evaluated on synthetic and benchmark data sets.
Probabilistic Feature Selection and Classification Vector Machine
Jun 13, 2018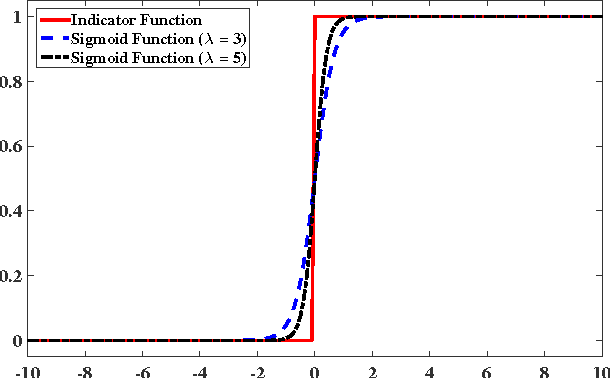
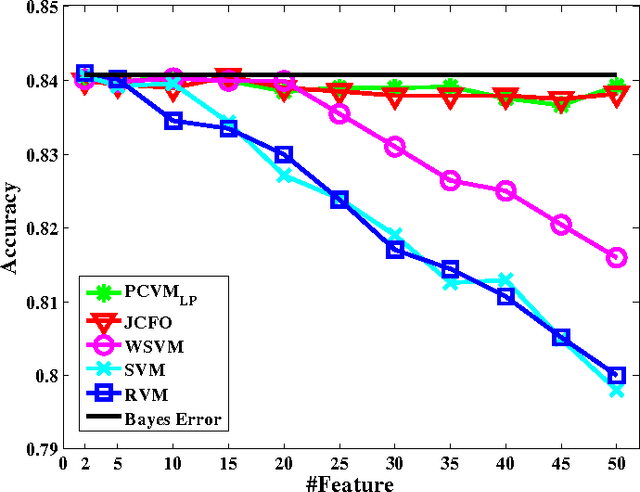
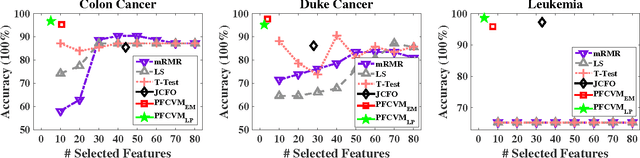
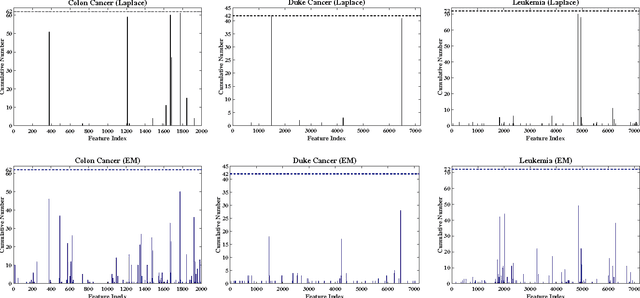
Sparse Bayesian learning is a state-of-the-art supervised learning algorithm that can choose a subset of relevant samples from the input data and make reliable probabilistic predictions. However, in the presence of high-dimensional data with irrelevant features, traditional sparse Bayesian classifiers suffer from performance degradation and low efficiency by failing to eliminate irrelevant features. To tackle this problem, we propose a novel sparse Bayesian embedded feature selection method that adopts truncated Gaussian distributions as both sample and feature priors. The proposed method, called probabilistic feature selection and classification vector machine (PFCVMLP ), is able to simultaneously select relevant features and samples for classification tasks. In order to derive the analytical solutions, Laplace approximation is applied to compute approximate posteriors and marginal likelihoods. Finally, parameters and hyperparameters are optimized by the type-II maximum likelihood method. Experiments on three datasets validate the performance of PFCVMLP along two dimensions: classification performance and effectiveness for feature selection. Finally, we analyze the generalization performance and derive a generalization error bound for PFCVMLP . By tightening the bound, the importance of feature selection is demonstrated.