 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEB: Long-horizon Memory Embedding Benchmark
Mar 19, 2026Memory embeddings are crucial for memory-augmented systems, such as OpenClaw, but their evaluation is underexplored in current text embedding benchmarks, which narrowly focus on traditional passage retrieval and fail to assess models' ability to handle long-horizon memory retrieval tasks involving fragmented, context-dependent, and temporally distant information. To address this, we introduce the Long-horizon Memory Embedding Benchmark (LMEB), a comprehensive framework that evaluates embedding models' capabilities in handling complex, long-horizon memory retrieval tasks. LMEB spans 22 datasets and 193 zero-shot retrieval tasks across 4 memory types: episodic, dialogue, semantic, and procedural, with both AI-generated and human-annotated data. These memory types differ in terms of level of abstraction and temporal dependency, capturing distinct aspects of memory retrieval that reflect the diverse challenges of the real world. We evaluate 15 widely used embedding models, ranging from hundreds of millions to ten billion parameters. The results reveal that (1) LMEB provides a reasonable level of difficulty; (2) Larger models do not always perform better; (3) LMEB and MTEB exhibit orthogonality. This suggests that the field has yet to converge on a universal model capable of excelling across all memory retrieval tasks, and that performance in traditional passage retrieval may not generalize to long-horizon memory retrieval. In summary, by providing a standardized and reproducible evaluation framework, LMEB fills a crucial gap in memory embedding evaluation, driving further advancements in text embedding for handling long-term, context-dependent memory retrieval. LMEB is available at https://github.com/KaLM-Embedding/LMEB.
DICArt: Advancing Category-level Articulated Object Pose Estimation in Discrete State-Spaces
Feb 26, 2026Articulated object pose estimation is a core task in embodied AI. Existing methods typically regress poses in a continuous space, but often struggle with 1) navigating a large, complex search space and 2) failing to incorporate intrinsic kinematic constraints. In this work, we introduce DICArt (DIsCrete Diffusion for Articulation Pose Estimation), a novel framework that formulates pose estimation as a conditional discrete diffusion process. Instead of operating in a continuous domain, DICArt progressively denoises a noisy pose representation through a learned reverse diffusion procedure to recover the GT pose. To improve modeling fidelity, we propose a flexible flow decider that dynamically determines whether each token should be denoised or reset, effectively balancing the real and noise distributions during diffusion. Additionally, we incorporate a hierarchical kinematic coupling strategy, estimating the pose of each rigid part hierarchically to respect the object's kinematic structure. We validate DICArt on both synthetic and real-world datasets. Experimental results demonstrate its superior performance and robustness. By integrating discrete generative modeling with structural priors, DICArt offers a new paradigm for reliable category-level 6D pose estimation in complex environments.
Learning Structure-Semantic Evolution Trajectories for Graph Domain Adaptation
Feb 11, 2026Graph Domain Adaptation (GDA) aims to bridge distribution shifts between domains by transferring knowledge from well-labeled source graphs to given unlabeled target graphs. One promising recent approach addresses graph transfer by discretizing the adaptation process, typically through the construction of intermediate graphs or stepwise alignment procedures. However, such discrete strategies often fail in real-world scenarios, where graph structures evolve continuously and nonlinearly, making it difficult for fixed-step alignment to approximate the actual transformation process. To address these limitations, we propose \textbf{DiffGDA}, a \textbf{Diff}usion-based \textbf{GDA} method that models the domain adaptation process as a continuous-time generative process. We formulate the evolution from source to target graphs using stochastic differential equations (SDEs), enabling the joint modeling of structural and semantic transitions. To guide this evolution, a domain-aware network is introduced to steer the generative process toward the target domain, encouraging the diffusion trajectory to follow an optimal adaptation path. We theoretically show that the diffusion process converges to the optimal solution bridging the source and target domains in the latent space. Extensive experiments on 14 graph transfer tasks across 8 real-world datasets demonstrate DiffGDA consistently outperforms state-of-the-art baselines.
Learning Adaptive Distribution Alignment with Neural Characteristic Function for Graph Domain Adaptation
Feb 11, 2026Graph Domain Adaptation (GDA) transfers knowledge from labeled source graphs to unlabeled target graphs but is challenged by complex, multi-faceted distributional shifts. Existing methods attempt to reduce distributional shifts by aligning manually selected graph elements (e.g., node attributes or structural statistics), which typically require manually designed graph filters to extract relevant features before alignment. However, such approaches are inflexible: they rely on scenario-specific heuristics, and struggle when dominant discrepancies vary across transfer scenarios. To address these limitations, we propose \textbf{ADAlign}, an Adaptive Distribution Alignment framework for GDA. Unlike heuristic methods, ADAlign requires no manual specification of alignment criteria. It automatically identifies the most relevant discrepancies in each transfer and aligns them jointly, capturing the interplay between attributes, structures, and their dependencies. This makes ADAlign flexible, scenario-aware, and robust to diverse and dynamically evolving shifts. To enable this adaptivity, we introduce the Neural Spectral Discrepancy (NSD), a theoretically principled parametric distance that provides a unified view of cross-graph shifts. NSD leverages neural characteristic function in the spectral domain to encode feature-structure dependencies of all orders, while a learnable frequency sampler adaptively emphasizes the most informative spectral components for each task via minimax paradigm. Extensive experiments on 10 datasets and 16 transfer tasks show that ADAlign not only outperforms state-of-the-art baselines but also achieves efficiency gains with lower memory usage and faster training.
Exploring Category-level Articulated Object Pose Tracking on SE(3) Manifolds
Nov 08, 2025Articulated objects are prevalent in daily life and robotic manipulation tasks. However, compared to rigid objects, pose tracking for articulated objects remains an underexplored problem due to their inherent kinematic constraints. To address these challenges, this work proposes a novel point-pair-based pose tracking framework, termed \textbf{PPF-Tracker}. The proposed framework first performs quasi-canonicalization of point clouds in the SE(3) Lie group space, and then models articulated objects using Point Pair Features (PPF) to predict pose voting parameters by leveraging the invariance properties of SE(3). Finally, semantic information of joint axes is incorporated to impose unified kinematic constraints across all parts of the articulated object. PPF-Tracker is systematically evaluated on both synthetic datasets and real-world scenarios, demonstrating strong generalization across diverse and challenging environments. Experimental results highlight the effectiveness and robustness of PPF-Tracker in multi-frame pose tracking of articulated objects. We believe this work can foster advances in robotics, embodied intelligence, and augmented reality. Codes are available at https://github.com/mengxh20/PPFTracker.
SToFM: a Multi-scale Foundation Model for Spatial Transcriptomics
Jul 15, 2025Spatial Transcriptomics (ST) technologies provide biologists with rich insights into single-cell biology by preserving spatial context of cells. Building foundational models for ST can significantly enhance the analysis of vast and complex data sources, unlocking new perspectives on the intricacies of biological tissues. However, modeling ST data is inherently challenging due to the need to extract multi-scale information from tissue slices containing vast numbers of cells. This process requires integrating macro-scale tissue morphology, micro-scale cellular microenvironment, and gene-scale gene expression profile. To address this challenge, we propose SToFM, a multi-scale Spatial Transcriptomics Foundation Model. SToFM first performs multi-scale information extraction on each ST slice, to construct a set of ST sub-slices that aggregate macro-, micro- and gene-scale information. Then an SE(2) Transformer is used to obtain high-quality cell representations from the sub-slices. Additionally, we construct \textbf{SToCorpus-88M}, the largest high-resolution spatial transcriptomics corpus for pretraining. SToFM achieves outstanding performance on a variety of downstream tasks, such as tissue region semantic segmentation and cell type annotation, demonstrating its comprehensive understanding of ST data
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
May 29, 2025Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on "test-time scaling" further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
Semi-Supervised Multi-Label Feature Selection with Consistent Sparse Graph Learning
May 23, 2025In practical domains, high-dimensional data are usually associated with diverse semantic labels, whereas traditional feature selection methods are designed for single-label data. Moreover, existing multi-label methods encounter two main challenges in semi-supervised scenarios: (1). Most semi-supervised methods fail to evaluate the label correlations without enough labeled samples, which are the critical information of multi-label feature selection, making label-specific features discarded. (2). The similarity graph structure directly derived from the original feature space is suboptimal for multi-label problems in existing graph-based methods, leading to unreliable soft labels and degraded feature selection performance. To overcome them, we propose a consistent sparse graph learning method for multi-label semi-supervised feature selection (SGMFS), which can enhance the feature selection performance by maintaining space consistency and learning label correlations in semi-supervised scenarios. Specifically, for Challenge (1), SGMFS learns a low-dimensional and independent label subspace from the projected features, which can compatibly cross multiple labels and effectively achieve the label correlations. For Challenge (2), instead of constructing a fixed similarity graph for semi-supervised learning, SGMFS thoroughly explores the intrinsic structure of the data by performing sparse reconstruction of samples in both the label space and the learned subspace simultaneously. In this way, the similarity graph can be adaptively learned to maintain the consistency between label space and the learned subspace, which can promote propagating proper soft labels for unlabeled samples, facilitating the ultimate feature selection. An effective solution with fast convergence is designed to optimize the objective function. Extensive experiments validate the superiority of SGMFS.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025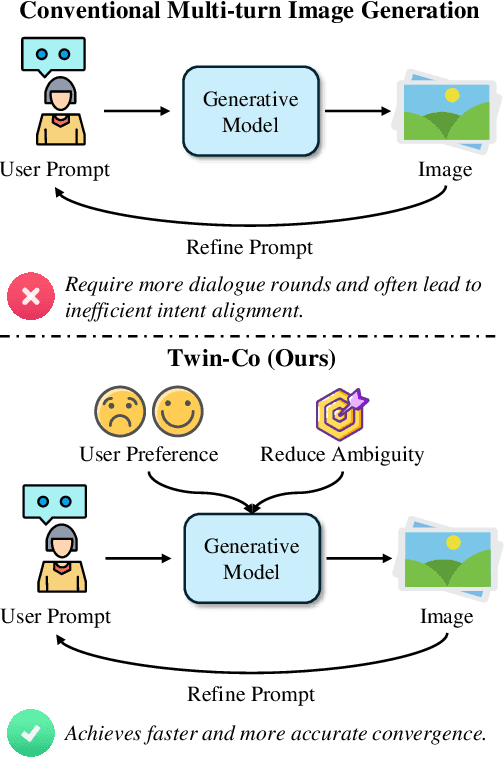
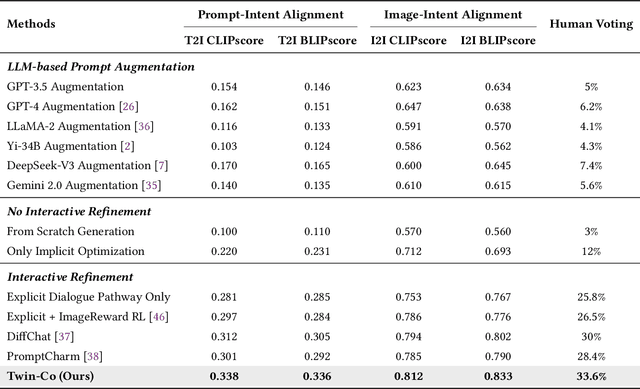
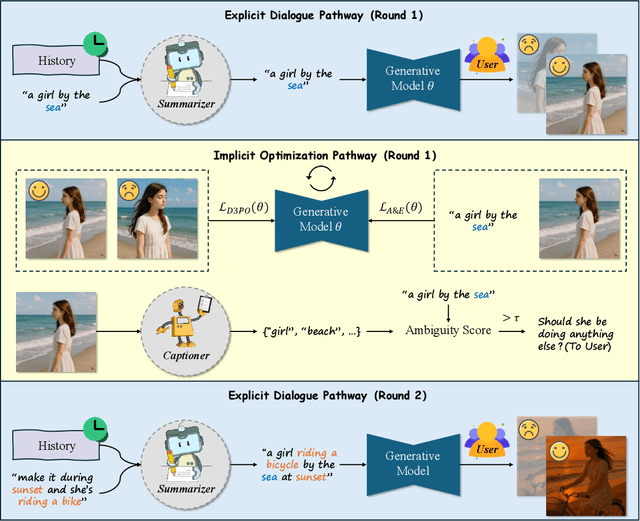

Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.