 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating o1-Like LLMs: Unlocking Reasoning for Translation through Comprehensive Analysis
Feb 17, 2025
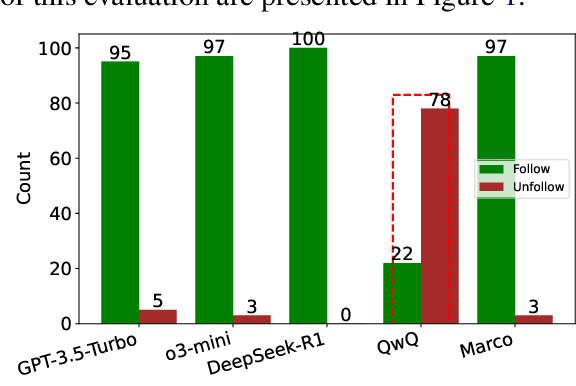


The o1-Like LLMs are transforming AI by simulating human cognitive processes, but their performance in multilingual machine translation (MMT) remains underexplored. This study examines: (1) how o1-Like LLMs perform in MMT tasks and (2) what factors influence their translation quality. We evaluate multiple o1-Like LLMs and compare them with traditional models like ChatGPT and GPT-4o. Results show that o1-Like LLMs establish new multilingual translation benchmarks, with DeepSeek-R1 surpassing GPT-4o in contextless tasks. They demonstrate strengths in historical and cultural translation but exhibit a tendency for rambling issues in Chinese-centric outputs. Further analysis reveals three key insights: (1) High inference costs and slower processing speeds make complex translation tasks more resource-intensive. (2) Translation quality improves with model size, enhancing commonsense reasoning and cultural translation. (3) The temperature parameter significantly impacts output quality-lower temperatures yield more stable and accurate translations, while higher temperatures reduce coherence and precision.
RaSeRec: Retrieval-Augmented Sequential Recommendation
Dec 24, 2024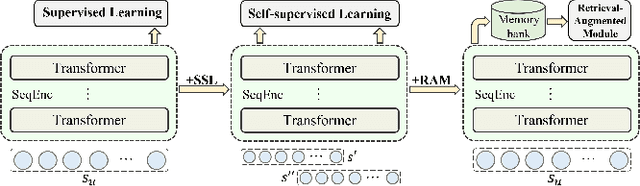

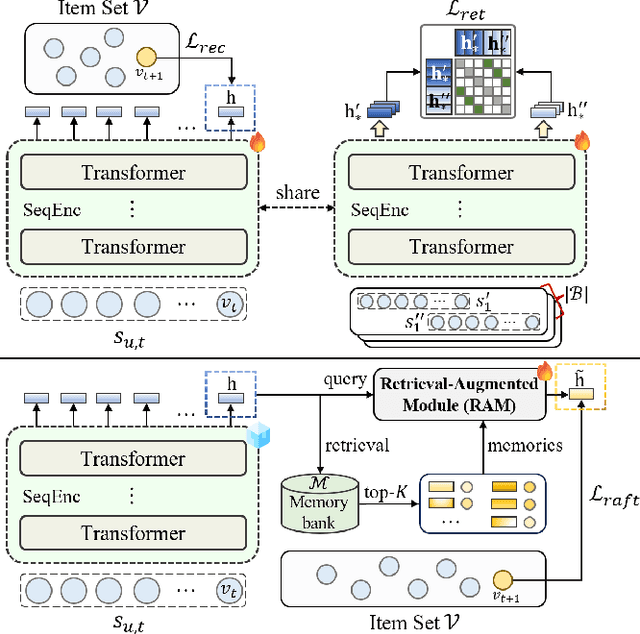
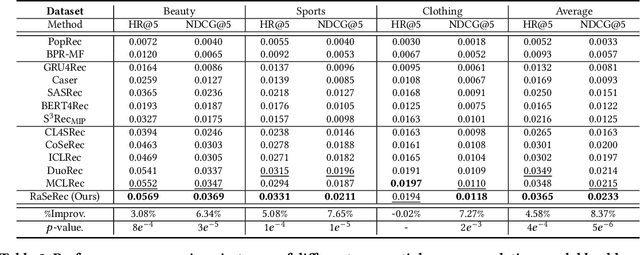
Although prevailing supervised and self-supervised learning (SSL)-augmented sequential recommendation (SeRec) models have achieved improved performance with powerful neural network architectures, we argue that they still suffer from two limitations: (1) Preference Drift, where models trained on past data can hardly accommodate evolving user preference; and (2) Implicit Memory, where head patterns dominate parametric learning, making it harder to recall long tails. In this work, we explore retrieval augmentation in SeRec, to address these limitations. To this end, we propose a Retrieval-Augmented Sequential Recommendation framework, named RaSeRec, the main idea of which is to maintain a dynamic memory bank to accommodate preference drifts and retrieve relevant memories to augment user modeling explicitly. It consists of two stages: (i) collaborative-based pre-training, which learns to recommend and retrieve; (ii) retrieval-augmented fine-tuning, which learns to leverage retrieved memories. Extensive experiments on three datasets fully demonstrate the superiority and effectiveness of RaSeRec.
LLM-based Translation Inference with Iterative Bilingual Understanding
Oct 17, 2024



The remarkable understanding and generation capabilities of large language models (LLMs) have greatly improved translation performance. However, incorrect understanding of the sentence to be translated can degrade translation quality. To address this issue, we proposed a novel Iterative Bilingual Understanding Translation (IBUT) method based on the cross-lingual capabilities of LLMs and the dual characteristics of translation tasks. The cross-lingual capability of LLMs enables the generation of contextual understanding for both the source and target languages separately. Furthermore, the dual characteristics allow IBUT to generate effective cross-lingual feedback, iteratively refining contextual understanding, thereby reducing errors and improving translation performance. Experimental results showed that the proposed IBUT outperforms several strong comparison methods, especially being generalized to multiple domains (e.g., news, commonsense, and cultural translation benchmarks).
Living in the Moment: Can Large Language Models Grasp Co-Temporal Reasoning?
Jun 13, 2024Temporal reasoning is fundamental for large language models (LLMs) to comprehend the world. Current temporal reasoning datasets are limited to questions about single or isolated events, falling short in mirroring the realistic temporal characteristics involving concurrent nature and intricate temporal interconnections. In this paper, we introduce CoTempQA, a comprehensive co-temporal Question Answering (QA) benchmark containing four co-temporal scenarios (Equal, Overlap, During, Mix) with 4,748 samples for evaluating the co-temporal comprehension and reasoning abilities of LLMs. Our extensive experiments reveal a significant gap between the performance of current LLMs and human-level reasoning on CoTempQA tasks. Even when enhanced with Chain of Thought (CoT) methodologies, models consistently struggle with our task. In our preliminary exploration, we discovered that mathematical reasoning plays a significant role in handling co-temporal events and proposed a strategy to boost LLMs' co-temporal reasoning from a mathematical perspective. We hope that our CoTempQA datasets will encourage further advancements in improving the co-temporal reasoning capabilities of LLMs. Our code is available at https://github.com/zhaochen0110/Cotempqa.